Ruby Ruby YJIT 原理浅析
前言
本人水平有限,如有错误,欢迎指正与补充。
YJIT 是 shopify 公司开发的 jit, 已于去年合并到了 ruby 源码。 本文会结合源码从 字节码,YJIT,到背后的 Lazy Basic Block Versioning (LBBV) 概念进行浅析,最后个人感叹一下软件缓存。
字节码
Ruby 自 1.9 版本开始,代码执行过程变为 Ruby源码 -> 字节码 -> YARV虚拟机 。
可用 RubyVM::InstructionSequence.disasm 查看生成的字节码,如下代码
def get(obj, idx)
return obj[idx]
end
puts RubyVM::InstructionSequence.disasm(method(:get))
[ 2] obj@0<Arg> [ 1] idx@1<Arg>
0000 getlocal_WC_0 obj@0 ( 7)[LiCa]
0002 getlocal_WC_0 idx@1
0004 opt_aref <calldata!mid:[], argc:1, ARGS_SIMPLE>
0006 leave ( 8)[Re]
如上,总共生成了 4 个字节码:第一个 getlocal_WC_0 获取变量 obj , 第二个getlocal_WC_0获取变量 idx, 第三个opt_aref代表源码里的 [], 第四个leave代表 return。ruby 定义的所有字节码及对应的 c 源码,可在 insns.def里查看,最后一个字节码是关于 42 的梗
本文主要讲 YJIT,对于 YARV 虚拟机感兴趣的同学推荐ruby-under-a-microscope(Ruby 原理剖析)
JIT
YARV 虚拟机执行字节码前,会尝试先用 JIT 来执行,c 源码在vm.c, 精简后如下
VALUE
vm_exec(rb_execution_context_t *ec, bool mjit_enable_p)
{
/* 省略 */
if (!mjit_enable_p || (result = mjit_exec(ec)) == Qundef) { /* 没有启动jit,或者jit的执行结果mjit_exec是不成功 Qundef, 则回到虚拟机正常执行 */
result = vm_exec_core(ec, initial);
}
goto vm_loop_start;
/* 省略 */
}
mjit_exec 会尝试构造一个函数指针,然后执行该函数。源码在 mjit.h, 精简后如下
static inline VALUE
mjit_exec(rb_execution_context_t *ec)
{
/* 省略 */
yjit_enabled = rb_yjit_enabled_p();
if (yjit_enabled && !mjit_call_p && body->total_calls == rb_yjit_call_threshold()) { /* 如果启动了yjit 并且这段字节码的总执行次数达到了yjit的限制,默认10次,则yjit尝试编译字节码 */
if (!rb_yjit_compile_iseq(iseq, ec)) { /* YJIT编译字节码,如果编译失败,返回Qundef */
return Qundef;
}
}
/* 省略 */
mjit_func_t func = body->jit_func; /* 如果YJIT编译成功,获取函数指针 */
// ec -> RDI 按照惯例,ec会存入RDI寄存器, 原由见下方的 yjit_entry_prologue 函数
// cfp -> RSI 按照惯例, cfp会存入RSI寄存器, 原由见下方的 yjit_entry_prologue 函数
return func(ec, ec->cfp); /* 执行函数指针对应的函数 */
}
剩下的工作,就是 YJIT 的 rb_yjit_compile_iseq 函数如何编译字节码,并返回一个函数指针?
YJIT
YJIT 为大部分字节码,注册了一个处理函数,例如一开始的 opt_aref 字节码,在 yjit_codegen.c 中注册了 gen_opt_aref 处理函数,精简如下
void
yjit_init_codegen(void)
{
/* 省略 */
yjit_reg_op(BIN(opt_neq), gen_opt_neq);
yjit_reg_op(BIN(opt_aref), gen_opt_aref);
yjit_reg_op(BIN(opt_aset), gen_opt_aset);
/* 省略 */
}
gen_opt_aref 处理函数,用手动编写汇编机器码的方式,在内存中写入 X86 汇编代码,精简如下
static codegen_status_t
gen_opt_aref(jitstate_t *jit, ctx_t *ctx, codeblock_t *cb)
{
/* 省略 */
if (CLASS_OF(comptime_recv) == rb_cArray && RB_FIXNUM_P(comptime_idx)) { /* 如果参数类型分别是 Array和Fixnum */
mov(cb, RDI, recv_opnd); /* 生成mov 汇编语句 */
sar(cb, REG1, imm_opnd(1)); /* 生成sar汇编语句 */
mov(cb, RSI, REG1); /* 生成 mov 汇编语句 */
call_ptr(cb, REG0, (void *)rb_ary_entry_internal); /* 生成call汇编语句,调用实际的rb_ary_entry_internal函数 */
x86opnd_t stack_ret = ctx_stack_push(ctx, TYPE_UNKNOWN);
mov(cb, stack_ret, RAX); /* 生成mov汇编语句,把 rb_ary_entry_internal 的返回值(RAX寄存器的值)存入YARV虚拟机的栈顶 */
jit_jump_to_next_insn(jit, ctx); /* 生成jmp汇编语句,继续执行后续的字节码生成的汇编语句 */
return YJIT_END_BLOCK;
}
else if (CLASS_OF(comptime_recv) == rb_cHash) {
/* 参数类型是Hash, 生成对应汇编语句,省略 */
}
else {
/* 参数类型是Proc, lambda 等, 生成对应汇编语句,省略 */
}
/* 省略 */
}
除了上面的 mov, sar, call_ptr, 其他完整的汇编机器码写入内存的函数,在yjit_asm.c。
可想而之,YJIT 的 rb_yjit_compile_iseq 就是把字节码对应的汇编机器码写入内存,并把该内存地址作为函数指针返回了。完整代码入口见yjit_iface.c, 精简如下
bool
rb_yjit_compile_iseq(const rb_iseq_t *iseq, rb_execution_context_t *ec)
{
/* 省略 */
bool success = true;
uint8_t *code_ptr = gen_entry_point(iseq, 0, ec); /* 获取汇编代码的内存地址, 详情见下方函数 */
/* 省略 */
if (code_ptr) {
iseq->body->jit_func = (yjit_func_t)code_ptr; /* 把汇编代码的内存地址存入函数指针 */
}
return success;
}
static uint8_t *
gen_entry_point(const rb_iseq_t *iseq, uint32_t insn_idx, rb_execution_context_t *ec)
{
/* 省略 */
uint8_t *code_ptr = yjit_entry_prologue(cb, iseq); /* 生成初始汇编代码,把相关寄存器存入栈中, 返回初始内存地址, 详情见下方函数 */
/* 省略 */
block_t *block = gen_block_version(blockid, &DEFAULT_CTX, ec); /* 根据字节码,生成后续的汇编代码。目前先省略,后续谈到LBBV的branch_stub_hit函数时,会再深入 */
return code_ptr;
}
static uint8_t *
yjit_entry_prologue(codeblock_t *cb, const rb_iseq_t *iseq)
{
/* 省略 */
uint8_t *code_ptr = cb_get_ptr(cb, cb->write_pos); /* 获取初始内存地址 */
ADD_COMMENT(cb, "yjit entry");
push(cb, REG_CFP); /* 在内存中写入 push 汇编代码 */
push(cb, REG_EC); /* 在内存中写入 push 汇编代码 */
push(cb, REG_SP); /* 在内存中写入 push 汇编代码 */
mov(cb, REG_EC, C_ARG_REGS[0]); /* mov汇编代码, 从C_ARG_REGS[0]即RDI寄存器, 获取传入的参数EC, 存入REG_EC寄存器 */
mov(cb, REG_CFP, C_ARG_REGS[1]); /* mov汇编代码, 从 C_ARG_REGS[0]即RSI寄存器, 获取传入的参数CFP, 存入REG_CFP寄存器 */
/* 把 cfp->sp 地址, 存入 REG_SP寄存器 */
mov(cb, REG_SP, member_opnd(REG_CFP, rb_control_frame_t, sp));
/* 把return相关的leave_exit_code汇编代码,存入 cfp->jit_return 函数指针 */
mov(cb, REG0, const_ptr_opnd(leave_exit_code));
mov(cb, member_opnd(REG_CFP, rb_control_frame_t, jit_return), REG0);
return code_ptr; /* 返回初始内存地址 */
}
Lazy Basic Block Versioning (LBBV)
如果只是把字节码手动转成汇编代码执行,那和直接让 YARV 虚拟机执行字节码没什么区别;因此 YJIT 额外用了名为 Lazy Basic Block Versioning(LBBV) 的优化方法,详情见 YJIT 作者发表的LBBV 论文
Lazy
Lazy Basic Block Versioning 中的 Lazy 代表懒生成,类似 ActiveRecord 中的 where 懒加载,只有在调用 to_a, each 等语句时才会真正触发 sql。YJIT 一开始生成的是一段 stub(空壳汇编代码),只有空壳代码被执行时,才继续生成真正的汇编代码。用 ruby 举例的话,类似如下代码
def time_consuming_operation
if respond_to?(:real_time_consuming_operation)
send(:real_time_consuming_operation)
else
stub
end
end
def stub
define_method(:real_time_consuming_operation) do
# time consuming operations
end
time_consuming_operation
end
if false
time_consuming_operation
else
# other operation
end
如上,如果执行时 if false, time_consuming_operation 暂时不被真正执行,则暂时不会生成实际的 real_time_consuming_operation 方法。YJIT 用懒生成的方式节省了汇编代码大小,省略了暂时不需要真正执行的汇编代码。还是以opt_aref 字节码对应的处理函数gen_opt_aref 源码为例子,精简后如下
static codegen_status_t
gen_opt_aref(jitstate_t *jit, ctx_t *ctx, codeblock_t *cb)
{
/* 省略 */
/* 如果是初次编译字节码,而不是真的执行到了对应的汇编代码。则调用defer_compilation 生成空壳汇编代码 */
if (!jit_at_current_insn(jit)) {
defer_compilation(jit, ctx); /* 生成空壳汇编代码,详情见下方函数 */
return YJIT_END_BLOCK;
}
/* 否则执行下面的语句,生成实际的汇编代码 */
if (CLASS_OF(comptime_recv) == rb_cArray && RB_FIXNUM_P(comptime_idx)) { /* 如果参数类型分别是 Array和Fixnum */
mov(cb, RDI, recv_opnd); /* 生成mov 汇编语句 */
sar(cb, REG1, imm_opnd(1)); /* 生成sar汇编语句 */
mov(cb, RSI, REG1); /* 生成 mov 汇编语句 */
call_ptr(cb, REG0, (void *)rb_ary_entry_internal); /* 生成call汇编语句,调用实际的rb_ary_entry_internal函数 */
x86opnd_t stack_ret = ctx_stack_push(ctx, TYPE_UNKNOWN);
mov(cb, stack_ret, RAX); /* 生成mov汇编语句,把 rb_ary_entry_internal 的返回值(RAX寄存器的值)存入YARV虚拟机的栈顶 */
jit_jump_to_next_insn(jit, ctx); /* 生成jmp汇编语句,继续执行后续的字节码生成的汇编语句 */
return YJIT_END_BLOCK;
}
else if (CLASS_OF(comptime_recv) == rb_cHash) {
/* 参数类型是Hash, 生成对应汇编语句,省略 */
}
else {
/* 参数类型是Proc, lambda 等, 生成对应汇编语句,省略 */
}
/* 省略 */
}
static void
defer_compilation(
jitstate_t *jit,
ctx_t *cur_ctx
)
{
/* 省略 */
/* 调用get_branch_target 获取stub空壳汇编代码的内存地址, 详情见下方函数 */
branch->dst_addrs[0] = get_branch_target(branch->targets[0], &next_ctx, branch, 0);
/* 省略 */
}
static uint8_t *
get_branch_target(
blockid_t target,
const ctx_t *ctx,
branch_t *branch,
uint32_t target_idx
)
{
/* 省略 */
uint8_t *stub_addr = cb_get_ptr(ocb, ocb->write_pos);
mov(ocb, C_ARG_REGS[2], REG_EC); /* 生成mov汇编代码,传REG_EC参数给branch_stub_hit */
mov(ocb, C_ARG_REGS[1], imm_opnd(target_idx)); /* 生成mov汇编代码,传target_idx参数给branch_stub_hit */
mov(ocb, C_ARG_REGS[0], const_ptr_opnd(branch)); /* 生成mov汇编代码,传branch指针参数给branch_stub_hit */
call_ptr(ocb, REG0, (void *)&branch_stub_hit); /* 生成call汇编代码,调用branch_stub_hit函数, 详情见下方函数 */
jmp_rm(ocb, RAX); /* 生成jmp汇编代码,跳转到branch_stub_hit的返回值地址 */
return stub_addr;
/* 省略 */
}
/* 如果该函数被执行,说明执行时对应的空壳汇编代码也被执行,需要生成实际的汇编代码 */
static uint8_t *
branch_stub_hit(branch_t *branch, const uint32_t target_idx, rb_execution_context_t *ec)
{
/* 省略 */
/* 生成实际的汇编代码(gen_block_version会重新调用gen_opt_aref),gen_block_version在之前的gen_entry_point函数中也出现过 */
p_block = gen_block_version(target, target_ctx, ec);
/* 省略 */
dst_addr = p_block->start_addr;
/* 省略 */
return dst_addr;
}
Basic Block Versioning
Basic Block Versioning 原理是把每段汇编代码缓存起来,形成用变量类型作为 key,汇编代码作为 value 的缓存。
ruby,js 等动态类型的语言,同一个操作可以使用不同类型的变量。还是以字节码opt_aref对应的 ruby 源码[]为例子,可以作用在 Array, Hash, Proc/lambda等变量类型上, 例如如下代码
rec = [1, 2, 3]
puts rec[2]
rec = { 1 => 1, 2 => 2 }
puts rec[2]
rec = Proc.new { |n| puts n }
rec[2]
所以 opt_aref 字节码对应的 c 源码有复杂的类型检查。Basic Block Versioning 的优化思路是,为当前变量类型生成特定的汇编代码,缓存下来。下次再遇到同样的字节码时,先检查变量类型,尝试从缓存中获取已有汇编代码内存地址;如果找不到缓存,再为新的变量类型,新增汇编代码,缓存下来。这样最终生成的汇编代码就只针对特定变量类型,易复用的同时更精简
以上面的 get_branch_target 和 branch_stub_hit 函数为例,他们都先调用 find_block_version 尝试从缓存中获取汇编代码,精简后如下
static uint8_t *
get_branch_target(
blockid_t target,
const ctx_t *ctx,
branch_t *branch,
uint32_t target_idx
)
{
/* 省略 */
/* 如果从缓存中找到对应的汇编代码,直接返回汇编代码内存地址, find_block_version 函数详情见下方 */
block_t *p_block = find_block_version(target, ctx);
// If the block already exists
if (p_block) {
/* 省略 */
/* 命中缓存,返回缓存汇编代码地址 */
return p_block->start_addr;
}
/* 未命中缓存,生成空壳汇编代码 */
/* 省略 */
uint8_t *stub_addr = cb_get_ptr(ocb, ocb->write_pos);
mov(ocb, C_ARG_REGS[2], REG_EC); /* 生成mov汇编代码,传REG_EC参数给branch_stub_hit */
mov(ocb, C_ARG_REGS[1], imm_opnd(target_idx)); /* 生成mov汇编代码,传target_idx参数给branch_stub_hit */
mov(ocb, C_ARG_REGS[0], const_ptr_opnd(branch)); /* 生成mov汇编代码,传branch指针参数给branch_stub_hit */
call_ptr(ocb, REG0, (void *)&branch_stub_hit); /* 生成call汇编代码,调用branch_stub_hit函数, 详情见下方函数 */
jmp_rm(ocb, RAX); /* 生成jmp汇编代码,跳转到branch_stub_hit的返回值地址 */
return stub_addr;
/* 省略 */
}
/* 如果该函数被执行,说明可能对应的空壳汇编代码也真的被执行,需要生成实际的汇编代码 */
static uint8_t *
branch_stub_hit(branch_t *branch, const uint32_t target_idx, rb_execution_context_t *ec)
{
/* 省略 */
/* 尝试从缓存中找汇编代码,find_block_version 函数详情见下方 */
block_t *p_block = find_block_version(target, target_ctx);
/* 如果从缓存中没有找到汇编代码,生成新汇编代码 */
if (!p_block) {
/* 生成实际的汇编代码(gen_block_version会重新调用gen_opt_aref),gen_block_version在之前的gen_entry_point函数中也出现过 */
p_block = gen_block_version(target, target_ctx, ec);
/* 省略 */
}
/* 省略 */
dst_addr = p_block->start_addr;
/* 省略 */
return dst_addr;
}
static block_t *
find_block_version(blockid_t blockid, const ctx_t *ctx)
{
/* 获取该字节码的所有缓存 */
rb_yjit_block_array_t versions = yjit_get_version_array(blockid.iseq, blockid.idx);
block_t *best_version = NULL;
int best_diff = INT_MAX;
/* 找出最匹配的缓存 */
rb_darray_for(versions, idx) {
block_t *version = rb_darray_get(versions, idx);
int diff = ctx_diff(ctx, &version->ctx); /* 比较当前变量类型和缓存变量类型的差异, 详情见下方函数 */
if (diff < best_diff) {
best_version = version; /* 找出最匹配的缓存 */
best_diff = diff;
}
}
/* 省略 */
return best_version;
}
static int
ctx_diff(const ctx_t *src, const ctx_t *dst)
{
/* 省略 */
/* 栈顶变量数量不同,放弃匹配 */
if (dst->stack_size != src->stack_size)
return INT_MAX;
/* sp偏移量不同,放弃匹配 */
if (dst->sp_offset != src->sp_offset)
return INT_MAX;
// Difference sum
int diff = 0;
// Check the type of self
int self_diff = type_diff(src->self_type, dst->self_type);
/* self 类型不同,放弃匹配 */
if (self_diff == INT_MAX)
return INT_MAX;
diff += self_diff;
// For each local type we track
for (size_t i = 0; i < MAX_LOCAL_TYPES; ++i)
{
val_type_t t_src = src->local_types[i];
val_type_t t_dst = dst->local_types[i];
int temp_diff = type_diff(t_src, t_dst);
/* 本地变量类型不同,放弃匹配 */
if (temp_diff == INT_MAX)
return INT_MAX;
diff += temp_diff;
}
/* 临时推到栈顶的变量类型 */
for (size_t i = 0; i < src->stack_size; ++i)
{
temp_type_mapping_t m_src = ctx_get_opnd_mapping(src, OPND_STACK(i));
temp_type_mapping_t m_dst = ctx_get_opnd_mapping(dst, OPND_STACK(i));
/* 省略 */
int temp_diff = type_diff(m_src.type, m_dst.type);
/* 临时变量类型不同,放弃匹配 */
if (temp_diff == INT_MAX)
return INT_MAX;
diff += temp_diff;
}
return diff;
}
综上,Lazy Basic Block Versioning(LBBV) 就是利用【懒生成】和【变量类型缓存汇编】的 jit 优化方法。本文只浅析了大致原理,具体如何将汇编代码写入缓存,如何把不同缓存的汇编代码用 jmp 拼接在一起,如何处理分支 jmp 跳转,感兴趣的同学可自行深入浏览源码。
缓存
根据Computer System A Programmer's Perspective(深入理解计算机系统),从硬件角度,本地硬盘是远端数据的缓存,内存是本地硬盘的缓存,CPU L1,L2,L3 是内存的缓存
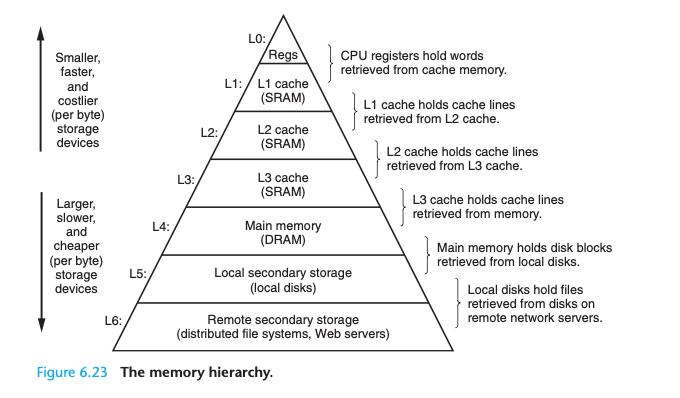
以我个人的知识经验:
从操作系统的角度,内存是文件系统的缓存 (系统调用 fflush, fsync), TLB 是虚拟内存地址到物理内存地址的缓存。
从 Web 服务器的角度,数据库索引是用于查找和排序的缓存,数据库视图是用于统计的缓存,数据库 MVCC 是事务中原数据的快照/缓存,redis 等又是数据库的缓存,cdn 又是 web 服务器的缓存,HTTP 的 ETag, last-modified 又是浏览器到服务器间的缓存。
从 Ruby 语言的角度,之前同样是 Shopify 开发的 bootsnap, 用覆盖 Kernel#require 的方式实现了 Gem 文件相对文件路径到绝对文件路径的缓存; 用 RubyVM::InstructionSequence.load_iseq 实现了 Ruby 源码到字节码的缓存。而本文的 YJIT 则实现了字节码到汇编代码的缓存。
“计算机科学只存在两个难题:缓存失效和命名。” ——Phil KarIton