Ruby Buffer Queue for Ruby
https://developer.mozilla.org/en-US/docs/Web/API/Navigator/sendBeacon
Ruby 里有类似 Navigator sendBeacon 机制的 gem 吗
大概是这样:
- add(msg)之后不立即执行,插入到 queue 里
- 插入到一定数量(N)之后批量执行
- 对于没达到 N 的 queue,有 timer 定时 flush
感觉是非常通用的场景,没有找到
对
 themadeknight
回复
themadeknight
回复
那个是用的 client middleware,要用的话,我要改成 server middleware。不一定基于 sidekiq,感觉 Ractor 可以做这东西。
saiga
#3
2021年03月22日
之前写 server 端 ab testing 的时候看过,貌似没有现成的。最后自己用线程实现了
核心代码就几行。
thread = Thread.new { sleep(5) and mutex.synchronize { flush(jobs) } while true } # 定时 5 秒 flush
mutex.synchronize { thread.wakeup if jobs.push(job).size > 10 } # push 时检查数组大小,超过则 flush
at_exit { mutex.synchronize { flush(jobs) } } # 退出时 flush
对
 saiga
回复
saiga
回复
搞了一个简单版 https://github.com/HyperCable/hypercable/pull/49/files
# frozen_string_literal: true
class BufferQueue
attr_reader :max_batch_size, :execution_interval, :timeout_interval, :callback
def initialize(max_batch_size: 100, execution_interval: 60, timeout_interval: 60, &callback)
@max_batch_size = max_batch_size
@execution_interval = execution_interval
@timeout_interval = timeout_interval
@queue = Queue.new
@timer = Concurrent::TimerTask.new(execution_interval: execution_interval, timeout_interval: timeout_interval) do
flush
end
@timer.execute
@callback = callback
at_exit { shutdown }
end
def flush
batch = []
max_batch_size.times do
if not @queue.empty?
begin
batch << @queue.pop(true)
rescue ThreadError
puts "queue is empty"
break
end
else
break
end
end
callback.call(batch) unless batch.empty?
end
def push(item)
@queue << item
if @queue.size >= max_batch_size
flush
end
item
end
def shutdown
puts "shutdown ..."
@timer.shutdown
flush
end
end
效果
[1] pry(main)> bq = BufferQueue.new(max_batch_size: 10, execution_interval: 5) do |batch|
p batch
end
25.times do |i|
bq.push(i)
end
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
=> 25
[2] pry(main)> [20, 21, 22, 23, 24]
[2] pry(main)> quit
shutdown ...

对
saiga
回复
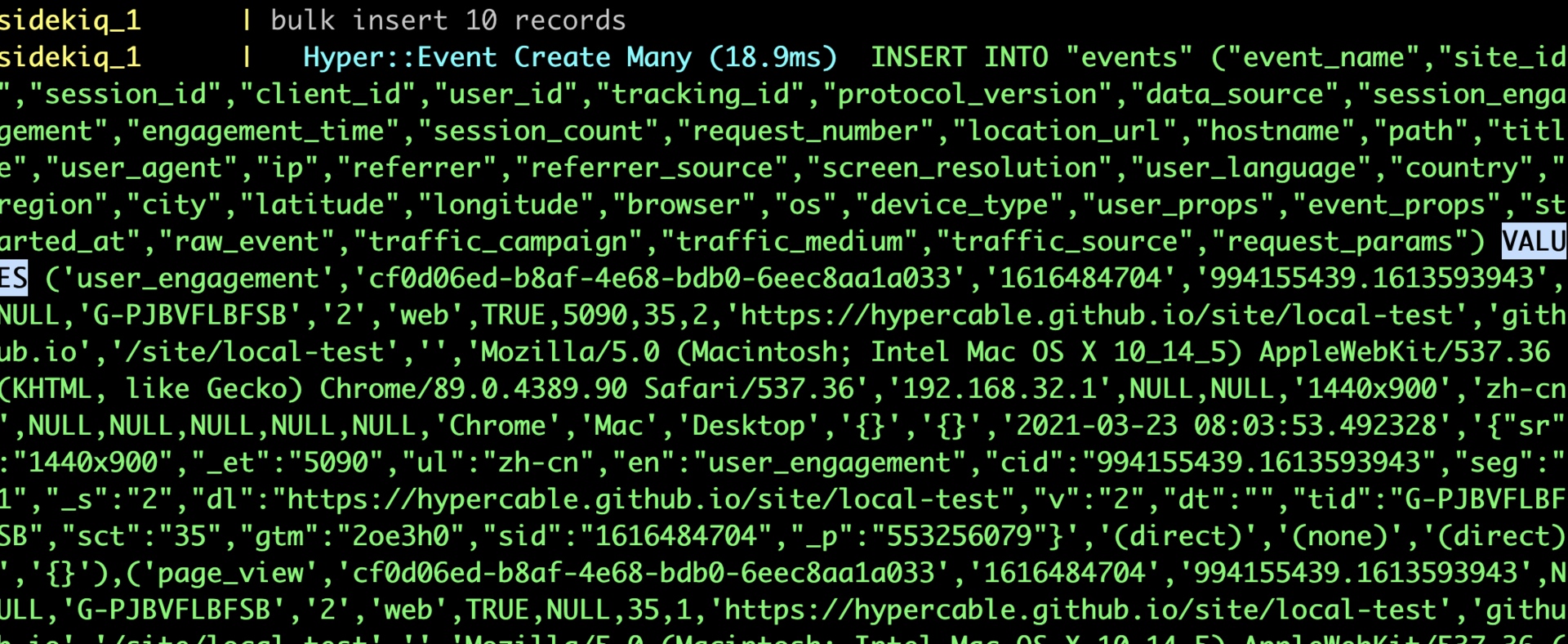
是的,没有实现 worker,但我现在的用法是和 sidekiq 一起,利用 sidekiq 的 worker 来实现,可以看上面新提交的代码
if Sidekiq.server?
Sidekiq.on(:startup) do
BQ = BufferQueue.new(max_batch_size: 10, execution_interval: 100) do |batch|
puts "bulk insert #{batch.size} records"
Hyper::Event.import(
EventJob::COLUMN_NAMES,
batch.flatten.map { |attr| Hyper::Event.new(attr) },
validate: false,
timestamps: false
) unless batch.empty?
end
end
end
in sidekiq job:
class EventJob
include Sidekiq::Worker
COLUMN_NAMES = Hyper::Event.column_names
def perform(*args)
result = a_lot_of_cal
BQ.push result
end
end
end
效果就是先利用 sidekiq 的多线程并行处理一些计算任务,产生的结果批量插入数据库; 相比之前 sidekiq job 里单条插入会快很多。并且可以利用 activerecord import 把多条记录改成 insert into values 的形式,插入更快。
saiga
#11
2021年03月24日
我当时的需求是做个 server 端的 event track sdk,所以需要异步处理并且尽量不依赖第三方包。
不过既然你用了 concurrent ruby,感觉是不是直接用 actor 代替 queue 会更直观。
require 'concurrent'
require 'concurrent-edge'
class JobActor < Concurrent::Actor::Context
Message = Struct.new(:action, :value)
def initialize
@jobs = []
@timer = Concurrent::TimerTask.new(execution_interval: 5) do
puts 'time to flush.'
flush
end.execute
end
def on_message(message)
case message.action
when :add then push(message.value)
when :flush then flush
end
end
private
def push(value)
flush if @jobs.size == 20
@jobs << value
end
def flush
jobs = @jobs.map(&:itself)
@jobs = []
p jobs
end
end
actor = JobActor.spawn name: 'job_actor'
67.times do |i|
actor.tell(JobActor::Message.new(:add, i))
end