数据库 How DBMS Memory Buffer Works
Introduction
面向磁盘(disk orienged)的数据库,需要把数据存储到磁盘上,而磁盘的速度比内存的速度慢非常多。

为了达到更好的性能,数据库通过 buffer pool manager 来让速度尽可能接近内存的速度。
数据库对数据的操作,是以 page 为单位的。不同的数据库的 page 大小不一样,MySQL 默认的是 16KB,PostgreSQL 是 8KB。
当需要访问某个 page 的时候,第一次,要从磁盘里读到内存里,再次访问时,因为这个 page 已经在内存里了,就不需要再读磁盘了。
根据时间局部性和空间局部性,每条 sql 所需要操作的 pages,有很大概率已经存在内存里了,这样就可以减少磁盘操作。
buffer pool 的命中率越高,就越接近内存的速度。
Frame, Page Table, Free List and Page Replacer
Buffer pool manager 主要负责的是把 page 从磁盘读到内存里,当内存里的 page 被替换时,需要根据情况写入到硬盘。
我们把内存里存放 page 的结构称为 frame。frame 除了放 page 的内容以外,还会存一些其它信息,比如 page_id、pin_count、dirty 等。
我们将 page_id 和 frame_id 分别作为 page 和 frame 的唯一标识。
现在,我们把 page_id=2 的 page 放到 frame_id=1 的 frame 里,当我们要想能查找 page_id 等于 2 的 frame 的时候,就需要一个 page_id 到 frame_id 的映射。
这个结构一般被叫做 page table。
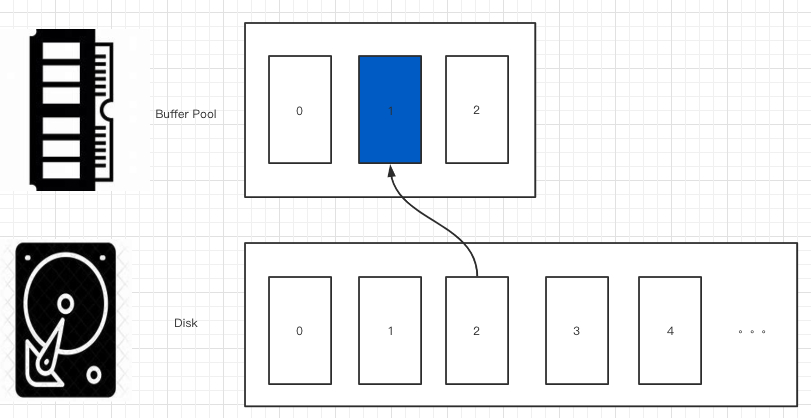
上图可以看到,frame 1 已经被使用了,frame 0 和 frame 2 还是空闲的。为了能找到空闲的 frame,我们还需要一个列表来记录这些空闲的 frame,我们可以叫它 free_frames 或者 free_list。
当 buffer pool 满了的时候,比如下面这幅图,我们就需要挑选可以被替换的 frame。
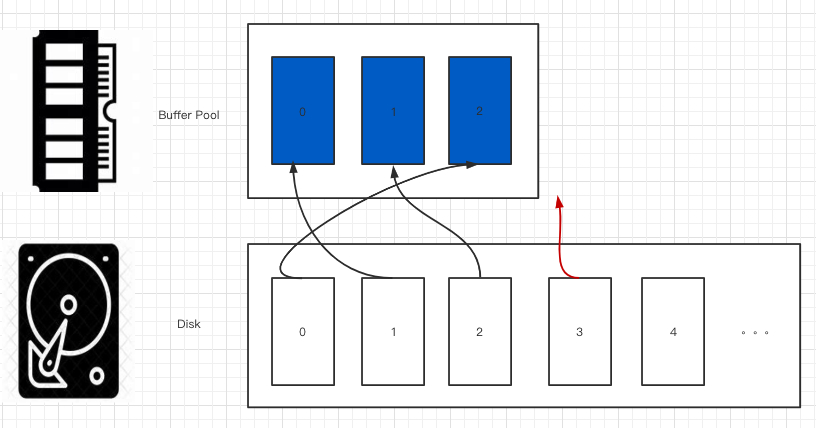
如果一个 frame 在被使用中的时候,我们是不能把这个 frame 的内容替换成其他 page 的。
所以 buffer pool manager 为每个 frame 维护了一个 pin_count 字段,初始为 0,当一个 frame 被用到的时候,就增加一 frame.pin_count += 1。
当用完了后,再对这个字段减一 frame.pin_count -= 1。因此,只有 pin_count == 0 的 frame 才能被其他 page 替换。
挑选需要被替换的 frame 的工作由 frame replacer 来完成。同时为了提高 buffer 命中率,需要一定的算法来挑选被替换的 frame。常见的算法有 LRU、CLOCK 等。
Main Operations
Fetch Page
首先要通过 page_id 检查 page_table 里有没有对应的 frame id,如果有,说明在内存里,直接返回对应的 frame。
如果没有,则需要把磁盘里的 page 拿到内存里来。
首先要检查 free list 里有没有空闲的 frame,如果有的话,则则通过 disk manager 将数据读到 frame 里,并初始化 frame 相应的状态。
如果 free list 是空的,则需要检查有没有合适替换的 frame。如果没有,则直接返回失败。
如果有,则通过 replacer 找到被替换的 frame_id,这个时候需要检查 frame 里的数据是否有被更改(is_dirty),如果有,则需要把数据写入磁盘。
处理完就的 frame,则需要通过 disk manager 读出新的 page,并放到 frame 里,同时需要设置 frame 相应的状态,比如 is_dirty = false。
因为这个 frame 有被使用,同时需要将 pin_count 增加一。

