Ruby ractor 跑一段简单代码,百分百崩溃
昨天我试图在真实项目中应用 ractor,测出了 ractor 2 线程比 ractor 1 线程慢近 1 倍的诡异现象。原贴在此:https://ruby-china.org/topics/40901。
今天继续折腾 ractor。经过一系列的失望,我对 ractor 的期望值已经非常低了,我只要它跑起来不要崩溃就谢天谢地了。因为在测试过程中,经常出现 rails 崩溃的情况。结果,我发现一段非常简单的代码,就能让 ractor 百分百崩溃……
先贴出不用 ractor 的单线程方法,当然运行是正常的:
e = (1..1000).to_a
arr = [e,e,e,e]
arr.map { |sub_arr|
sub_arr.map {
md5(rand.to_s)
}
}.flatten
就是随机生成字符串做 md5。md5 调用 module 中的方法 Digest::MD5.hexdigest(str)。代码中分成 4 个子数组,是为了和 ractor 对比,ractor 方法会开 4 个线程,每个线程处理 1 个子数组:
arr.map { |sub_arr|
Ractor.new(sub_arr) do |sub_arr|
sub_arr.map {
md5(rand.to_s)
}
end
}.map{|r| r.take}.reduce(:+)
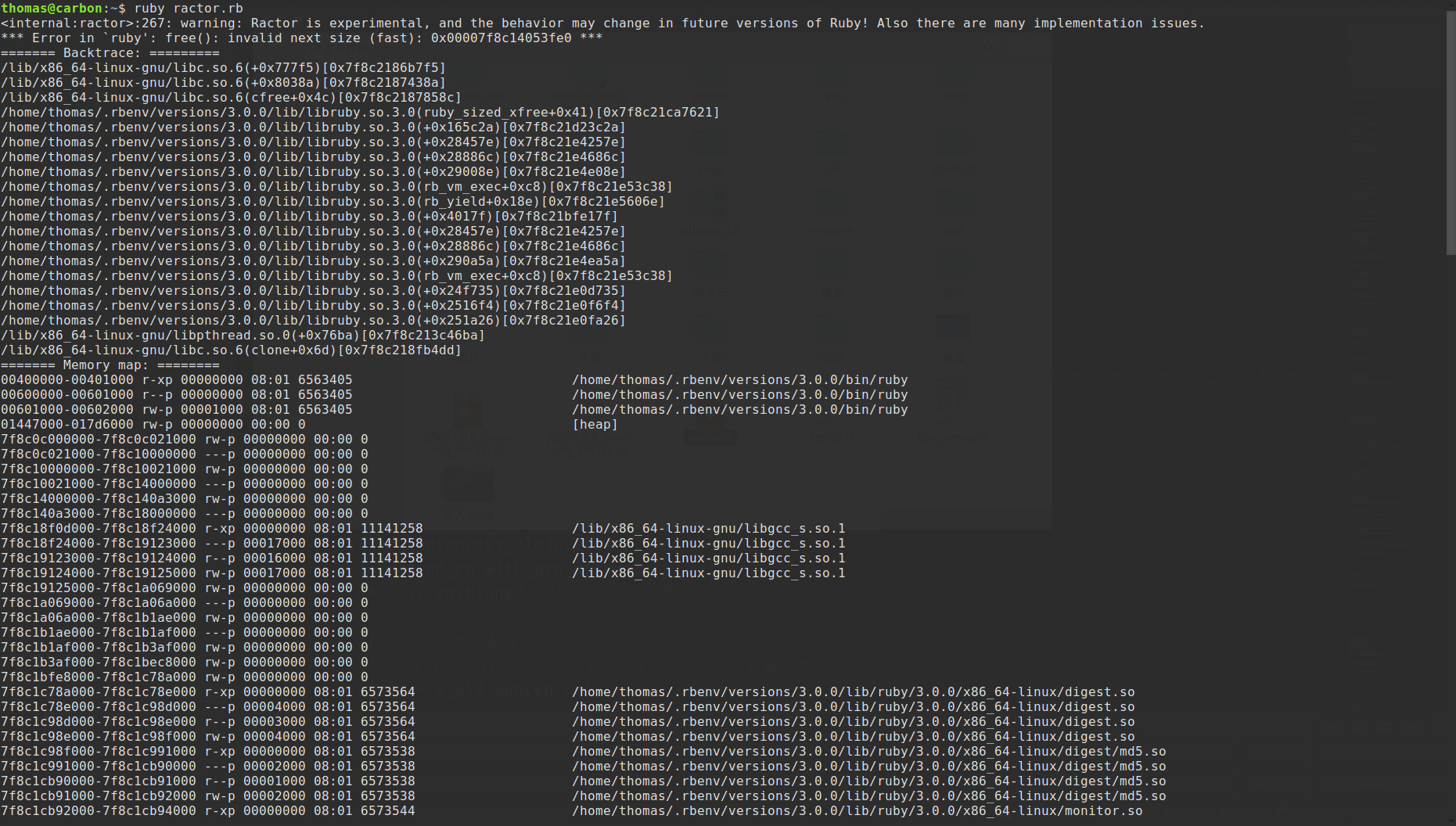
这段代码每次运行都会导致 rails 崩溃,报错:*** Error in `puma 5.2.1 (tcp://0:3001) : free(): invalid next size (fast): 0x00007fa7d80032a0 ***
是代码的问题吗?把 e 改为 1..100,立马不崩溃了,怎么解释?
e=1..1 万、100 万,又崩溃了。是计算量太大导致崩溃的吗?然而,同样数值用非 ractor 的普通单线程方法,却完全正常。
我的环境是 ruby3.0+rails6.1.1,所有 gem 升到最新。2 核 4 线程 cpu,空闲内存有 4g。大家可以用自己的环境重现试试。
要么是我代码的问题,要么是环境的问题,要么是 ractor 本身的问题,我想不出别的可能了。希望是我自己的问题,请各位打脸无妨。如果是我的问题,我还能改;如果是 ractor 的问题,那我只能弃用 ractor 了。
后续:
后来把这个问题发到https://bugs.ruby-lang.org/issues,处理我问题的是 ko1(Koichi Sasada),他用一个更简化的版本复现了问题,只有一行代码:
2.times.map{ Ractor.new{ loop{ rand.to_s } } }.each(&:take)
看来基本可以确定是 ruby3.0 的 bug,大概率与 ractor 有关,可能与环境也有关。至于坑有多深我就不知道了,让大神去填吧。
各位如果方便的话,可以把这行代码放到 irb 里跑一下,只需 1 秒钟的时间。如果有人竟然不报错崩溃的,请回复我,我可以把情况发给 ko1 做个参考。
结局:
此问题已被 nobu 和 ko1 修复,原文如下:
Fixed the race condition when replacing freelist entry with its chained next element. At acquiring an entry, hold the entry once with the special value, then release by replacing it with the next element again after acquired. If another thread is holding the same entry at that time, spinning until the entry gets released.