本系列分为四大部分:
- gRPC 系列 (一) 什么是 RPC?
- gRPC 系列 (二) 如何用 Protobuf 组织内容
- gRPC 系列 (三) 如何借助 HTTP2 实现传输
- gRPC 系列 (四) 框架如何赋能分布式系统
初步印象
RPC 的语义是远程过程调用,在一般的印象中,就是将一个服务调用封装在一个本地方法中,让调用者像使用本地方法一样调用服务,对其屏蔽实现细节。而具体的实现是通过调用方和服务方的一套约定,基于 TCP 长连接进行数据交互达成。
上面的解释似云里雾里,仅仅了解到这种程度是远远不够的,还需要更进一步,以相对底层和抽象的视角来理解 RPC。
三个特点
广义上来讲,所有本应用程序外的调用都可以归类为 RPC,不管是分布式服务,第三方服务的 HTTP 接口,还是读写 Redis 的一次请求。从抽象的角度来讲,它们都一样是 RPC,由于不在本地执行,都有三个特点:
- 需要事先约定调用的语义 (接口语法)
- 需要网络传输
- 需要约定网络传输中的内容格式
以一次 Redis 调用为例,执行redis.set("rpc", 1)这个调用,其中:
-
set及其参数("rpc", 1),就是对调用语义的约定,由 redis 的 API 给出 - RedisServer 会监听一个服务端口,通过 TCP 传输内容,用异步事件驱动实现高并发
- 底层库会约定数据如何进行编解码,如何标识命令和参数,如何表示结果,如何表示数据的结尾等等
这三个特点都是因为调用不在本地而不得不衍生出来的问题,也因此决定了 RPC 的形态。所有的 RPC 解决方案都是在解决这三个问题,不断地在提出更加优良的解决方案,试图达到更好的性能,更低的使用成本。本文也将围绕这三个特点来展开内容。
常规的 RPC 一般都是基于一个大的内部服务,进行分布式拆分,由于其语义上以本地方法的作为入口,那么天然的就更倾向于具备高性能、支持复杂参数和返回值、跨语言等特性。下图是 RPC 调用的过程示意图:
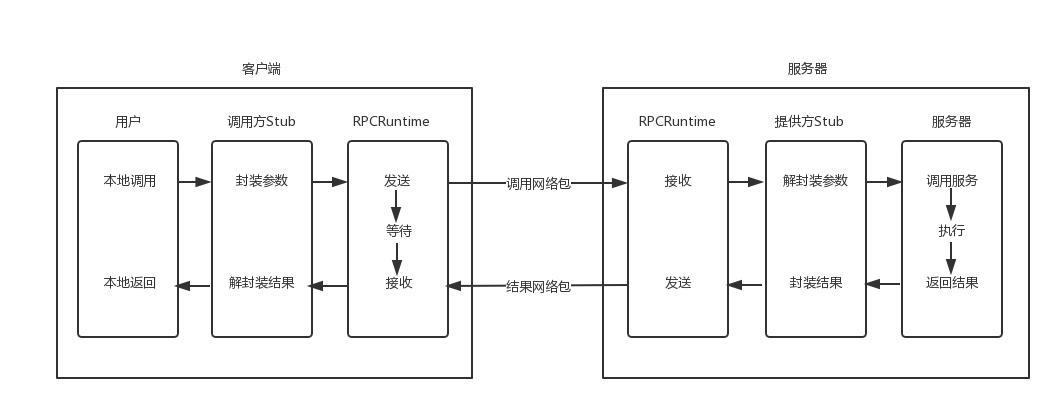
内容组织约定
Stub 会负责封装命令和参数,并以特定的数据格式进行打包。其中命令、参数和返回值的需要客户端和服务端的 Stub 事先进行协商,双方都需要维护一份完全一样的方法及参数列表。更进一步需要知道对方如何进行压缩打包,如何压缩结构体,如何压缩 Class 等等,并严格按照标准进行解压缩,中途有任何一丝的差错都会的导致调用失败。所以一般情况下可能会对数据进行一定的校验,同时要协商方法、参数等错误时如何返回。这是一个比较繁杂的过程,混合了调用语法和 内容解压缩两部分内容,可被理解为如何组织内容的问题。
网络传输
搞定了协议约定问题后,接下来就是要通过 Runtime 进行内容传输了,这又是一大难题,一般是需要通过 Socket 编程来实现,使用 TCP 或 UDP 来进行传输,如果是 UDP 可以用数据报来区分每一次请求和回复。但如果是字节流的 TCP,就需要用特殊的方式来标示请求或回复的末尾,用来区分不同的请求。同时当对调用性能有要求时,可能会使用 Socket 的异步编程模型,消除等待中的消耗,这会引入事件机制,通过状态机来解析处理或回复请求。当出现超时、丢包等情况时还进行做重试、重传、报错等等。
拆解到协议约定和网络传输时,就会发现实现 RPC 调用是一件非常复杂的事情,自己实现千难万难,接下来就了解一番已有的,针对协议约定和网络传输的解决方案。
当然,在技术高度成熟的今天,已经又很多先烈将传输问题解决掉了,接下来就介绍几款常见的案例组合。
ONC RPC
ONC RPC 是相对早期的 RPC 解决方案,通过外部数据表示法来约定数据的压缩方式:
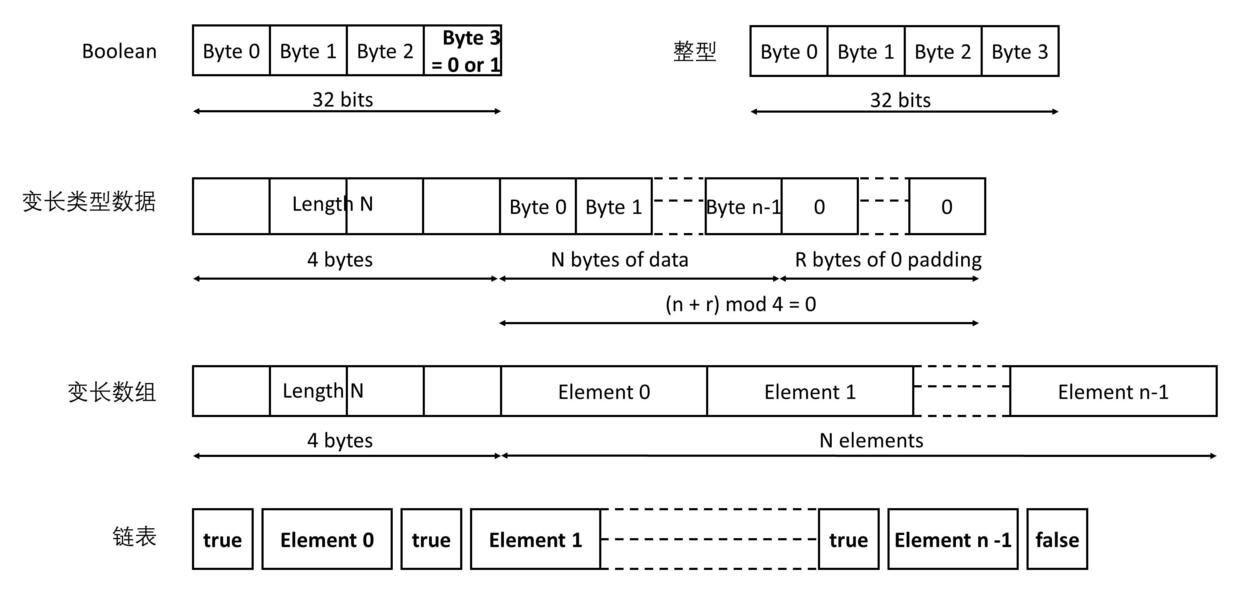
被传输的所有内容都需要通过上面的约定进行压缩,这样接收方就能顺利地按照同样的协议进行解压缩。
对于命令和参数列表的约定,会创建一份公共的协议文件,里面会定义被调用的方法名,参数列表,对象的列表等等。然后用特定工具将文件进行解析生成 Stub 程序,客户端和服务端都同时将 Stub 程序放在代码中。比如对方法名进行编号,将GetUserName(userId)这个方法编号为 1,在调用时就将 1 传输给服务端,服务端通过协议文件就知道调用的方法,这样节省了大量的空间。
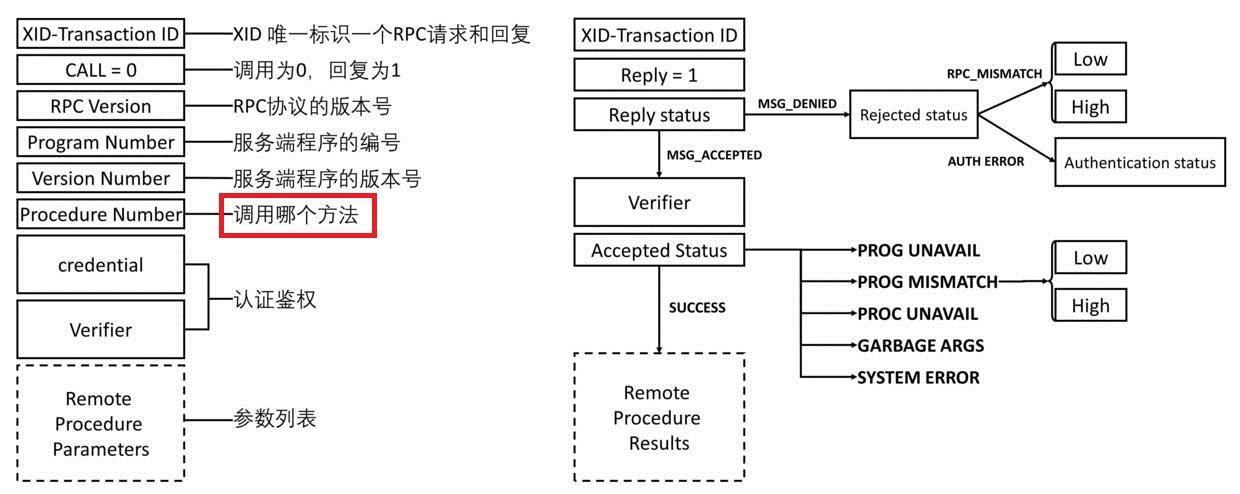
传输则通过对应的类库实现,通过 Socket 编程实现的非常复杂的解决方案,包含了超时、失败、异常处理、状态转换等等功能。
这种早期的方案,在每一次代码更新时都需要重新生成 Stub 程序,调用方和服务方都需要及时更新对应的文件。给某一个方法增加一个默认参数,都需要全部使用者同步升级,从迭代或多版本的场景看来,这是一场噩梦。
RESTfull HTTP JSON
RESTfull 是一种资源状态转换的架构风格,也可以用来实现 RPC,互联网对 HTTP 超广泛的支持,使得这相当简单,也是大多数情况下的首选。
通过 HTTP 协议来进行内容传输,Header 用来约定编码、body 大小等,彼此以\r\n来分割,Header 和 body 之间通过两个连续的\r\n来间隔,能很容易地区分不同的请求。
通过 Url 和对应参数来标示要调用的方法和参数。在 body 中用 JSON 对内容进行编码,极易跨语言,不需要约定特定的复杂编码格式和 Stub 文件。在版本兼容性上非常友好,扩展也很容易。
众多的优点使得这种方案广受欢迎。不过也有其无法避开的弱点:
- HTTP 的 header 和 Json 的数据冗余和低压缩率使得传输性能差
- JSON 难以表达复杂的参数类型,如结构体等
gRPC HTTP2.0 Protobuf
gRPC 是一款 RPC 框架,也是本系列的主角,在性能和版本兼容上做了提升和让步:
- Protobuf 进行数据编码,提高数据压缩率
- 使用 HTTP2.0 弥补了 HTTP1.1 的不足
- 同样在调用方和服务方使用协议约定文件,提供参数可选,为版本兼容留下缓冲空间
protobuf是一款用 C++ 开发的跨语言、二进制编码的数据序列化协议,以超高的压缩率著称。它和早期的 RPC 方案一样,需要双方维护一个协议约束文件,以.proto 结尾,使用 proto 命令对文件进行解析,会生成对应的 Stub 程序,客户端和服务端都需要保存这份 Stub 程序用来进行编解码。对于这种协议文件导致的升级困难问题,protobuf 3 中定义的字段默认都是可选的 (可以不传),在接口升级时,部分客户端不需要升级自己的 Stub 程序。
// ***.proto文件
syntax = "proto3";
package id_rpc;
message BusinessType {// 定义参数
string name = 1; //参数字段
}
message UniqueId {// 定义返回值
uint64 id = 1;
string business_type = 2;
}
service UniqueIdService {// 定义服务,可以调用 MakeUniqueId 方法
rpc MakeUniqueId(BusinessType) returns (UniqueId){}
}
对于 JSON 等文本形式的序列化协议来说,protobuf 能有几十倍空间和性能提升,比如传输123,文本类的需要 3 个字节 (ascii 31 32 33) 来传输,而二进制类只需要一个字节 (01111011) 就可以表示。
同时 protobuf 会维护.proto 文件,这样在解析文件生成 Stub 程序时,可以对方法名等进行编号,传输时只传编号,而不用传方法的名字,这又可以节省大量字节,还有其他更多的精巧压缩方法,比如 TLV,详情可以参考proto encoding 。
解决了数据体积的问题后,gRPC 使用 HTTP2 来改善传输性能。HTTP2 是在 HTTP1.1 的基础上做了大量的改进,HTTP1.1 虽然引入了 KeepAlive 复用 TCP 连接,但仍然有很多问题:
- 使用 KeepAlive 的请求是串行执行 (非 pipeline 时),pipeline 时有队首阻塞问题
- 每次都需要发送不必要的 Header
- 不能双向通信
简单补充一下 pipeline,HTTP1.1 中允许多个请求复用连接,同时可以一口气将请求全部发出去,不用一个返回后再发送第二个,提升并发性。而服务端需要将请求的结果,按照 pipeline 中发送的顺序进行顺序返回,如果靠前的请求阻塞了,那么靠后请求返回就会被动等待。
HTTP2 解决了这些问题,引入了新的机制:
- 在两端建立 Header 索引表,每次只发送索引,减小 header 体积
- 建立虚拟通道,将数据拆分成多个流,每个流有自己的 ID 和优先级,并且流可以双向传输,每个流可以进一步拆成多个帧。可以将多个请求切成不同的流发送,每个流可以独立返回,避开 1.1 的串行或队首阻塞问题。
同时,基于 HTTP2 的数据流机制,gRPC 客户端和服务端可以实现批量操作优化,客户端可以攒一些请求,一口气发给服务端,服务端也可以批量返回结果,借此实现流式 rpc。
RabbitMQ
rpc 作为一种极常见的服务形态,以异步和解耦著称的 mq 也自然不会放过这个场景,rabbitmq 就为 rpc 调用提供了很好的支持。
一般和 rabbitmq 的交互场景是发布或消费消息,是一个单向的过程,而 rpc 却是一种同步的双向交互过程,在使用上有些差异。要理解 rabbitmq 如何实现 rpc,还是可以从上面三个抽象的特点出发,万变不离其宗。
如何协商调用语义
mq 中的消息是从 exchange 分发到 queue 中,消费端在特定的 queue 中获取消息,rpc 的请求依然要走这条路径:方法调用->exchange->queue->方法执行。
创建一个 direct 类型的 exchange,让每个 rpc 方法对应一个 queue,这个 exchange 通过 routing_key 分发到对应的 queue 中,让特定的消费者来实际执行 rpc 方法。这样 rpc 方法的语义就通过 queue 来约定,而方法的参数,可以放入消息中。
如何将结果传递回客户端
方法调用->exchange->queue->方法执行, 这条路是单行道,方法执行端执行完 rpc 方法后不能按照原路将结果返回给客户端。要实现结果回传,就得再开辟一条结果回传端->exchange->queue->结果等待端路径,一条用来发送 rpc 请求,另一条用来回传 rpc 结果,方法调用者和方法执行者都会扮演生产者和消费者。
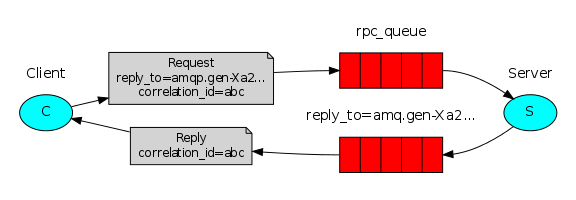
rabbitmq 中有回调队列(Callback queue)来实现调用结果回传,同时有关联ID(Correlation Id)来唯一标识每一份调用结果。
rpc 调用方在发送请求时,会在数据中带上回调队列信息 (routing_key) 和关联 ID,rpc 执行方在执行完方法后,就将关联 ID 掺入执行结果中,并将结果通过 exchange 发往回调队列 (通过 routing_key)。rpc 调用方在发送请求后,紧接着在设置的回调队列中等结果就行。整个过程 (两条路径) 共用同一个 exchange。
调用参数和调用结果的打包可以用 JSON,protobuf 等等,协商一致即可。完整示例代码
使用 mq 实现 rpc,有其独有的优势,rpc 执行端可以轻松地横向扩展,rpc 调用方也不用考虑负载均衡,沿袭了 mq 解耦的优点。不过对于调用超时,执行端崩溃等等情况得做额外处理。调用方在等待结果时需要设置超时间,高性能的 rpc 调用还需要调用方能异步高效地通过关联 ID 将请求结果储存起来,等待调用者获取。Spring 框架的实现方案就是用一个 HashMap 将结果保存起来,等待调用者以关联 ID 作为 key 来取结果。
工程落地
RPC 作为分布式系统的桥梁,在解决以上三大问题之外,还得需要进行工程落地,这就是RPC框架的核心职责。其要解决的问题有:
- 集成服务发现的能力
- 负载均衡、限流、熔断等常规操作
- 服务方并发能力、稳定性
- 请求方资源利用、池化、容错等
整体的目标是将 RPC 调用落地,为分布式系统赋能。这是一个系统性的工程。
总结
RPC 从抽象的角度来看:
- 具有需要约定调用语法
- 需要约定内容编码方式
- 需要网络传输
这三大特点,进一步可以归纳为协议约定问题和网络传输问题,本文的主要内容都围绕这两大问题,并介绍常见的解决方案,借此对建立 RPC 更深的理解。
接下来的内容,会走进 gRPC 这款强大的 RPC 框架,分别介绍 gRPC 是如何解决上面的三个点,并提供出框架级的能力,为分布式系统赋能。