Erlang/Elixir Note of "Memory Barriers: a Hardware View for Software Hackers"
以下主要是 Memory Barriers: a Hardware View for Software Hackers 这篇论文的笔记。
所谓笔记,就是一些自己的理解,忽略了一些细节,也不那么严谨。
如果大家对 memory barrier 这个概念感兴趣,还是推荐看论文。
Cache Structure
目前,CPU 运行速度很快,但操作内存很慢。
硬件设计者,为了解决两者速度不匹配,就在内存和 CPU 间加了缓存 cache。
CPU 先尝试从 cache 里读,如果没有,会在从内存里把数据读到 cache 里。
每个 CPU 都有自己对应的 cache,如下图:
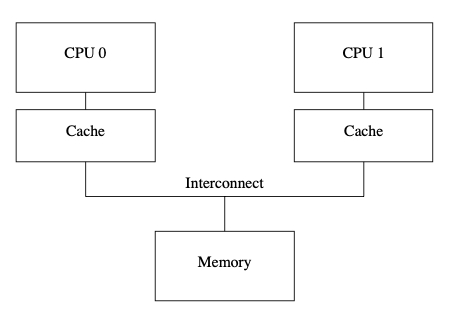
这个时候,假设一个变量,读到了两个 cache 里,如果某个 CPU 更新了这个变量的值,而另一个 CPU 没更新,就会不一致。
所以提出了 Cache-Coherence Protocols 来解决这个问题。
Cache-Coherence Protocols
Cache-Coherence Protocols 通过消息传递,让多个 cache 达成一致的一个协议。
比如:
假设某个变量只有一个 cache 有,那么这个 cache 可以直接更新。
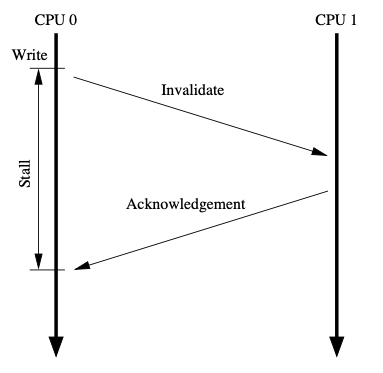
如果一个变量,有两个 cache 有,某个 cache 要更新这个值,就需要通知另一个 cache。并且等到收到另一个 cache 的返回,才能真的更新。
Store Buffers and Memory Barriers
假设变量 a,在 CPU 0 和 CPU 1 的 cache 里都有。
根据 cache-coherence protocols,则需要通知 CPU 1,
并等待返回,而在等待返回的这一段时间里,CPU 0 什么也不做,显然不明智。
为了避免傻等,硬件设计者,给 CPU 增加了 store buffer,结构如下:
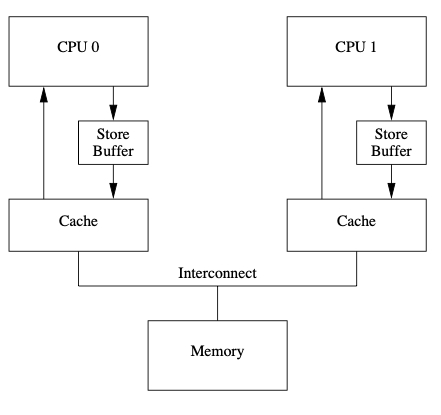
在更新 a 的时候,会先将更新后的值放到 store buffer 里。
因为消息是异步的,cache 和 store buffer 的值有可能是不一致的,所以需要优先读 store buffer 里的值,既 store forwarding。
有些问题,store forwarding 是无法解决的,比如下面这个例子。
void foo(void) {
a = 1;
b = 1;
}
void bar(void) {
while (b == 0) continue;
assert(a == 1);
}
CPU 0 执行 foo,CPU 1 执行 bar。a 在 CPU 1 的 cache 里,b 在 CPU 0 的内存里。
CPU 0 执行 a = 1,但 CPU 0 cache 里没有 a,所以把 a = 1 放到了 store buffer 里,并跟 CPU 1 说 a 失效了(read invalidate)。
CPU 1 执行 while (b == 0) continue,CPU 1 的缓存里没有 b 的值,所以发消息(read message)向 CPU 0 要。
CPU 0 继续执行,执行 b = 1,因为 b 只在 CPU 0 的缓存里,CPU 直接更新缓存。
CPU 0 收到了 read message,把 b 的最新值 1 返回给 CPU 1。
CPU 1 收到 CPU 0 的消息,将 b 更新为 1。
再次执行 while (b == 0) continue 这个时候,b = 1,
执行 assert(a == 1),这个时候 a 的值还是 0(invalidate message 处理的比较慢),assert 失败。
简单来说,就是 a = 1 这件事,CPU 0 还不知道,但 CPU 0 已经知道了 b = 1 这件事,导致错误。
解决方案,就是在 a = 1 和 b = 1 之间加上 memory barrier。
既:
void foo(void) {
a = 1;
smp_mb();
b = 1;
}
大体来讲,就是 a = 1 会被放到 store buffer 里,之后执行 smp_mb。
在执行 b = 1 的时候,因为在此之前有 memory barrier,所以 b = 1 不会被写到到 cache 里。
在 CPU 1 在向 CPU 0 要 b 的值的时候,仍然返回 0。
直到 CPU 1 收到 read invalidate,并返回确认消息。CPU 0 收到确认,更新 a = 1 到 cache line 之后,
才会更新 b = 1 到 cache line。
这样就保证了代码的正确执行。
Invalidate Queues
我们知道,如果要更新某个 cache line,需要让其他 CPU 对应的 cache line 失效。
这个时候需要向相应的 CPU 发 invalidate message。
但收到消息的 cache 可能比较忙,来不及处理,所以硬件设计者,又增加了一个 invalidate queue,
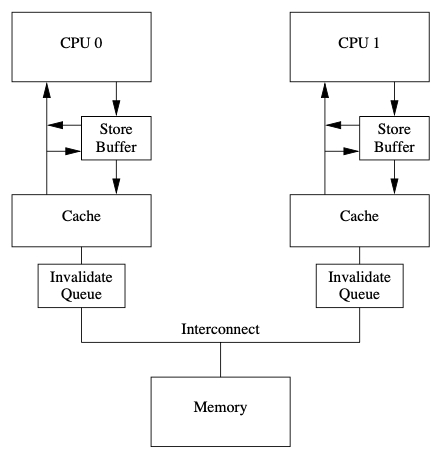
cache 会把收到的 invalidate 消息先放到 invalidate queue 里,并返回确认消息。
invalidate queue 也会造成 memory misorder。
还是之前的例子,简单来说,就是 CPU 1 收到了 a 的 invalidate message,并返回了确认消息。
但 cache 没更新,只是把消息放到 invalidate queue 里了。
CPU 0 收到了 a invalidate 的确认消息,更新了 a,之后更新了 b。
CPU 1 执行 while (b == 0) continue,由于 b = 1,但这个时候,a 是 invalidate 的消息还在 invalidate queue。
CPU 1 从 cache 里拿到的 a 的值是 0,导致 assert(a == 1) 失败。
因为 memory barrier 对 invalidate queue 也有效,所以解决方案是在 while (b == 0) continue 和 assert(a == 1) 之间再加一个 memory barrier。
既:
void bar(void) {
while (b == 0) continue;
smp_mb();
assert(a == 1);
}
Read and Write Memory Barriers
之前的 memory barrier 都是同时对 invalidate queue 和 store buffer 奇效,有些时候,并不需要同事等两个,
所以硬件设计者,提供了 read memory barrier 和 write memory barrier。
简单来说,就是 read memory barrier 只对 invalidate queue 有效,write memory barrier 只对 store buffer 有效。
其他
这篇论文还介绍 memory barrier 在不同 CPU 上的情况,完全是硬件知识,这里就不说了。
最后作者还贴心的给硬件工作者提了一些可以让软件编写更难的建议(There are any number of things that hardware designers can do to make the lives of software people difficult)。 
Erlang 处理的 memory barrier 有 6 种(比上面介绍的还复杂  ),如果硬件不支持,就会替换成自己的实现。Erlang 在并行上,做了大量的努力。
),如果硬件不支持,就会替换成自己的实现。Erlang 在并行上,做了大量的努力。
最后想说,并发、并行是件非常复杂的事情,反直觉,且琐碎。