分享 使用 Docker 构建 Nebula Graph 源码

Nebula Graph 介绍
Nebula Graph 是开源的高性能分布式图数据库。项目使用 C++ 语言开发,cmake 工具构建。其中两个重要的依赖是 Facebook 的 Thrift RPC 框架和 folly 库.
由于项目采用了 C++ 14 标准开发,需要使用较新版本的编译器和一些三方库。虽然 Nebula Graph 官方给出了一份开发者构建指南,但是在本地构建完整的编译环境依然不是一件轻松的事。
开发环境构建
Nebula Graph 依赖较多,且一些第三方库需本地编译安装,为了方便开发者本地编译项目源码,Nebula Graph 官方为大家提供了一个预安装所有依赖的 docker 镜像。开发者只需如下的三步即可快速的编译 Nebula Graph 工程,参与 Nebula Graph 的开源贡献:
本地安装好 Docker
将
vesoft/nebula-dev镜像pull到本地
$ docker pull vesoft/nebula-dev
- 运行
Docker并挂载 Nebula 源码目录到容器的/home/nebula目录
$ docker run --rm -ti -v {nebula-root-path}:/home/nebula vesoft/nebula-dev bash
感谢社区伙伴@阿东 提的建议,把上面的 {nebula-root-path} 替换成你 Nebula Graph 实际 clone 的目录
为了避免每次退出 docker 容器之后,重新键入上述的命令,我们在 vesoft-inc/nebula-dev-docker 中提供了一个简单的 build.sh 脚本,可通过 ./build.sh /path/to/nebula/root/ 进入容器。
- 使用
cmake构建 Nebula 工程
docker> mkdir _build && cd _build
docker> cmake .. && make -j2
docker> ctest # 执行单元测试
提醒
Nebula 项目目前主要采用静态依赖的方式编译,加上附加的一些调试信息,所以生产的一些可执行文件会比较占用磁盘空间,建议小伙伴预留 20G 以上的空闲空间给 Nebula 目录 :)
Docker 加速小 Tips
由于 Docker 镜像文件存储在国外,在 pull 过程中会遇到速度过慢的问题,这里 Nebula Graph 提供一种加速 pull 的方法:通过配置国内地址解决,例如:
- Azure 中国镜像 https://dockerhub.azk8s.cn
- 七牛云 https://reg-mirror.qiniu.com
Linux 小伙伴可在 /etc/docker/daemon.json 中加入如下内容(若文件不存在,请新建该文件)
{
"registry-mirrors": [
"https://dockerhub.azk8s.cn",
"https://reg-mirror.qiniu.com"
]
}
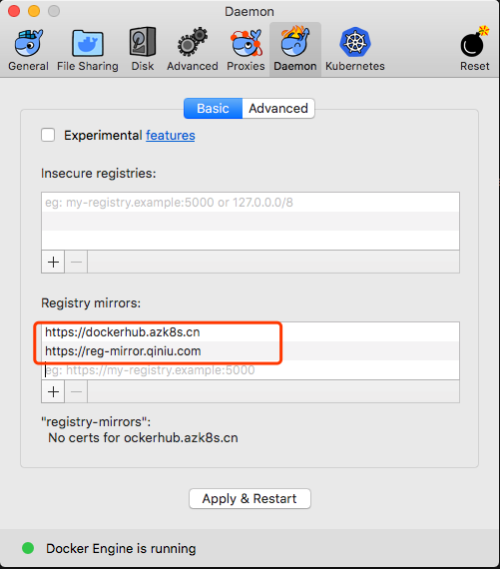
macOS 小伙伴请点击 Docker Desktop 图标 -> Preferences -> Daemon -> Registry mirrors。在列表中添加 https://dockerhub.azk8s.cn 和 https://reg-mirror.qiniu.com 。修改后,点击 Apply & Restart 按钮,重启 Docker。
Nebula Graph 社区
Nebula Graph 社区是由一群爱好图数据库,共同推进图数据库发展的开发者构成的社区。
本文由 Nebula Graph 社区 Committer 伊兴路贡献,也欢迎阅读本文的你参与到 Nebula Graph 的开发,或向 Nebula Graph 投稿。
附录
Nebula Graph:一个开源的分布式图数据库。
GitHub:https://github.com/vesoft-inc/nebula