背景
项目有时会遇到数据库关系设计不当的情况,如果局限于“开闭原则”的话就发现本该合理的业务在遗留项目中很难实现,扔给产品一句“由于历史原因,这个做不了”。这里分析一个开发过程中的简单 migration 案例,目前已经在使用 execute sql 了。
项目
这是一个投票项目,一共两张表:users 和 votes
create_table :users
create_table :votes do |t|
t.references :candidate, foreign_key: { to_table: :users }
t.references :voter, foreign_key: { to_table: :users }
end
每次用户投票 votes 表增加一条记录,candidate 和 voter 分别是一个用户,直到。。。
新需求
- “我们要能创建很多投票活动,为第三方提供投票服务”
- “后台可以添加哪些用户是哪个活动的 candidate”
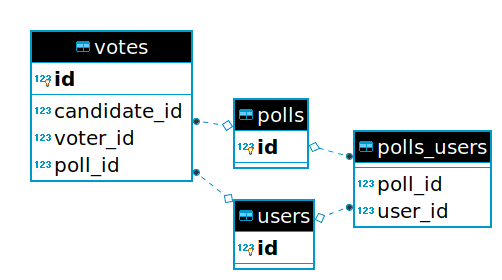
对策 1
创建 polls 表,把 poll_id 添加到 votes 表中:
create_table :polls
add_reference :votes, :poll, foreign_key: true
创建 polls 表到 users 表的多对多关系
create_join_table :polls, :users
对策 2
在对策 1 的思路上,我们可以把 polls 和 users 的多对多关系实体化为一个新的 candidates,(此前 candidate_id 对应的是 users 表),让 votes 表记录这个新的 candidate 实体而不是 user 实体。这样对策 1 就变成了:
create_table :polls
create_table :candidates |t|
t.references :users
t.references :polls
end
remove_reference :votes :candidate, foreign_key: { to_table: :users }
add_reference :votes :candidate, foreign_key: true
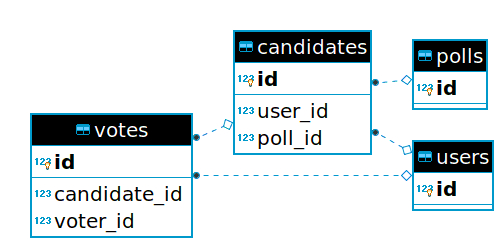
注意到这样 votes 表的外键由 3 个变成了 2 个,并且这样方便对 candidate 作 counter_cache
数据迁移
直接 remove_reference、add_reference 会丢失生产环境中已有 votes 的 candidate 信息,需要:
- 将 users 表中的记录导入到 candidates 表中,poll_id 设为 nil
- 将 votes 表中的 candidate_id 从实际引用的 users 表的 id 更新到 candidates 表的 id
使用 execute sql 进行数据迁移(使用了 PostgreSQL 的 Window 函数)
create_table :polls
create_table :candidates |t|
t.references :users
t.references :polls
end
revert do
add_foreign_key :votes, :users, column: :candidate_id
end
reversible do |dir|
dir.up do
execute <<~SQL
INSERT INTO candidates (user_id, created_at, updated_at)
SELECT DISTINCT candidate_id, min(created_at) OVER (PARTITION BY candidate_id), min(created_at) OVER (PARTITION BY candidate_id)
FROM votes;
UPDATE votes SET candidate_id = (SELECT id FROM candidates WHERE user_id = candidate_id);
SQL
end
dir.down do
execute <<~SQL
UPDATE votes SET candidate_id = (SELECT user_id FROM candidates WHERE id = candidate_id);
SQL
end
end
add_foreign_key :votes, :candidates