数据库 一个 MySQL 死锁案例分析 --Index merge when update
本文通过OKR来约束文章内容边界:
Objectives:
- 通过死锁案例分析,加深对 MySQL 锁的理解
Key Results:
- 交待死锁背景信息
- 介绍 MVCC、锁等相关的前置知识
- 分析出加锁细节
- 分析出为什么会死锁
- 给出对应策略并加以分析
死锁背景
死锁日志
*** (1) TRANSACTION:
TRANSACTION 641576, ACTIVE 0 sec starting index read
mysql tables in use 3, locked 3
LOCK WAIT 5 lock struct(s), heap size 1136, 4 row lock(s)
MySQL thread id 2289, OS thread handle 123145606135808, query id 1725930 localhost 127.0.0.1 root updating
UPDATE `lists` SET `updated_at` = '2019-04-20 17:17:57.752797' WHERE (`interval` = 1 and started_at = 4)
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 32 page no 6 n bits 328 index PRIMARY of table `live_room`.`lists` trx id 641576 lock_mode X locks rec but not gap waiting
Record lock, heap no 15 PHYSICAL RECORD: n_fields 11; compact format; info bits 0
*** (2) TRANSACTION:
TRANSACTION 641568, ACTIVE 0 sec starting index read
mysql tables in use 3, locked 3
5 lock struct(s), heap size 1136, 4 row lock(s)
MySQL thread id 2225, OS thread handle 123145587195904, query id 1725900 localhost 127.0.0.1 root updating
UPDATE `lists` SET `updated_at` = '2019-04-20 17:17:57.747561' WHERE (`interval` = 2 and started_at = 3)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 32 page no 6 n bits 328 index PRIMARY of table `live_room`.`lists` trx id 641568 lock_mode X locks rec but not gap
Record lock, heap no 15 PHYSICAL RECORD: n_fields 11; compact format; info bits 0
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 32 page no 6 n bits 328 index PRIMARY of table `live_room`.`lists` trx id 641568 lock_mode X locks rec but not gap waiting
Record lock, heap no 9 PHYSICAL RECORD: n_fields 11; compact format; info bits 0
*** WE ROLL BACK TRANSACTION (2)
表结构
CREATE TABLE `lists` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`interval` bigint(20) DEFAULT '10000',
`started_at` bigint(20) DEFAULT '1',
`updated_at` timestamp NULL DEFAULT NULL,
`enable` tinyint(1) DEFAULT '1',
PRIMARY KEY (`id`),
KEY `index_interval` (`interval`),
KEY `index_started` (`started_at`)
) ENGINE=InnoDB AUTO_INCREMENT=15355 DEFAULT CHARSET=utf8
死锁 sql 执行计划
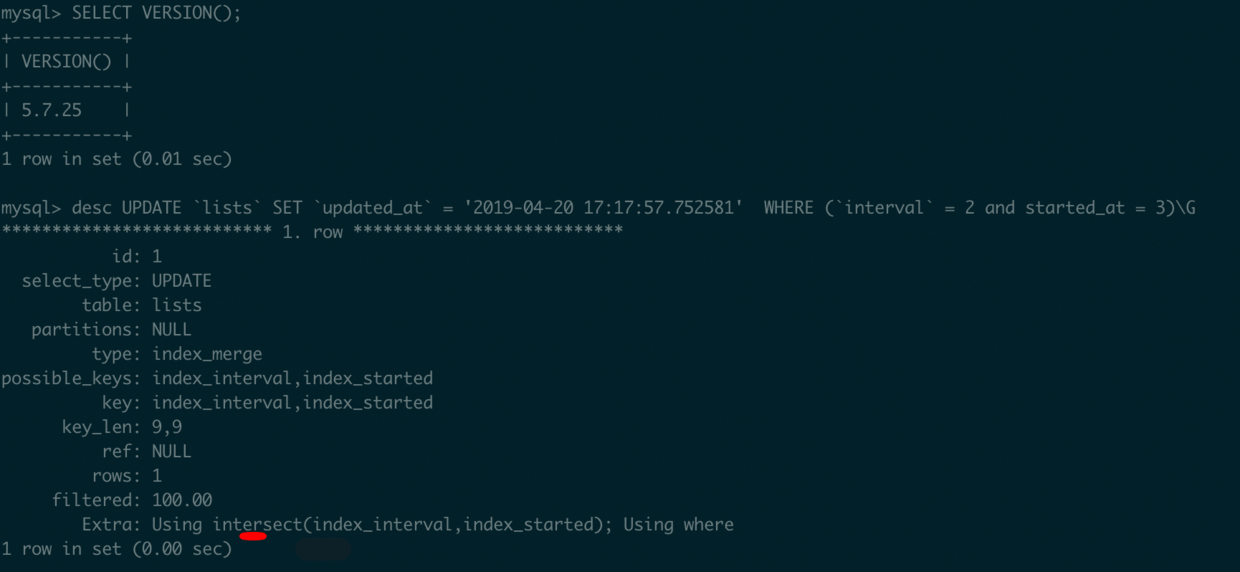
死锁信息梳理
UPDATE `lists` SET `updated_at` = *** WHERE (`interval` = 1 and started_at = 4) -- 事务1
UPDATE `lists` SET `updated_at` = *** WHERE (`interval` = 2 and started_at = 3) -- 事务2
死锁发生在两条 update 语句之间,它们有着相同的结构,只是更新的数据不同。有两个查询条件,彼此都单独有索引,在执行计划中,MySQL 使用了index merge来提升查询效率。
事务 1((1) TRANSACTION:) 持有 4 把行锁 (4 row lock(s)), 其中一把处于等待状态 ((1) WAITING FOR THIS LOCK TO BE GRANTED),位于页面编号为 6(page no 6) 的地方,锁针对的是主键索引 (index PRIMARY of table) 的记录锁 (Record lock),只锁记录不锁区间 ( lock_mode X locks rec but not gap waiting)。
事务 2 持有 ((2) HOLDS THE LOCK(S)) 页面编号为 6(page no 6) 的一个主键记录锁 (应该正是事务 1 在等待的),正在等待 ((2) WAITING FOR THIS LOCK TO BE GRANTED) 页面编号为 6 中一把只锁记录不锁区间的主键锁。
可以看出,两个事务互相拥有对方需要的主键记录锁,而又在等待对方的另一把锁释放,所以造成了死锁。
看一看两条语句相关的内容:
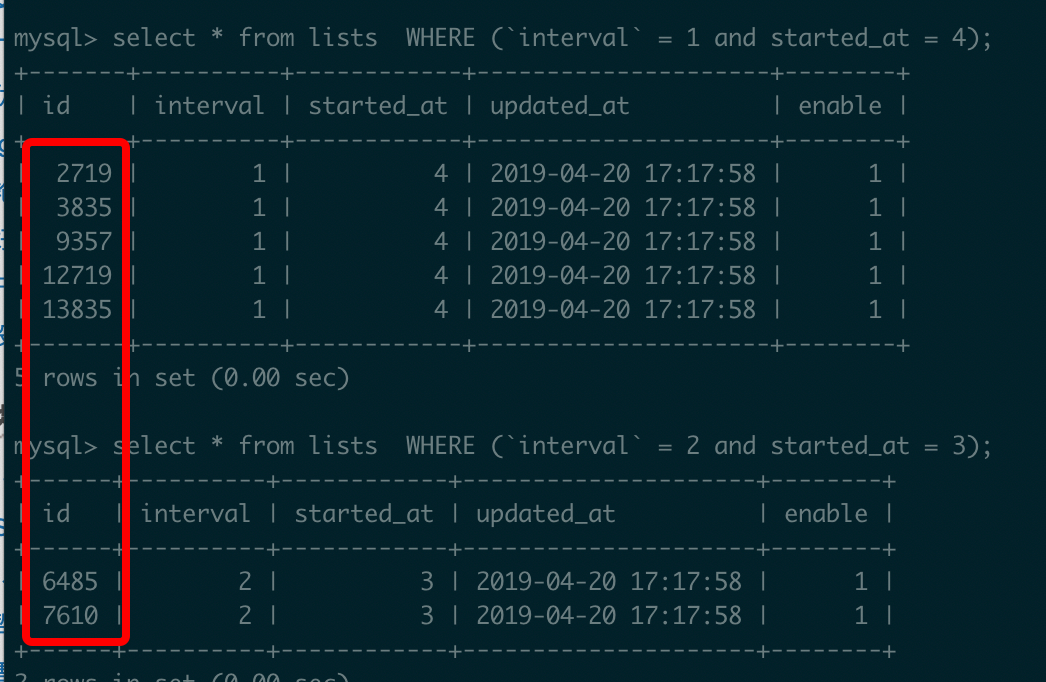
可以看到,两条语句并没有重合的内容,感觉上不符合"常理",那么问题问题来了:
为什么还会产生死锁?
要搞清楚为什么会死锁,必须得知道语句执行的时候到底发生了什么。接下来一步步理清思路,一起来解答这个问题。
保证数据一致性
innodb 支持数据库 ACID 的特性,在数据更新时会保证数据一致性,上文中死锁的 update 语句不管怎么执行,数据库都会保证数据的合法性,不会使数据丢失或错误,那么它怎么来实现这点呢?
简单来说,就是对数据加锁,最小粒度就是行级锁。而锁会明显削弱并发性能,为了提高并发性,MySQL 实现了MVCC,也就是多版本并发控制,实现读不加锁,读写不冲突,它将读取操作分为两种:
- 快照读,不加锁
- 当前读,加锁
快照读就是常规的select语句,读取时不加锁,但有可能读不到最新版本,所以叫快照读。
当前读是读取数据的最新版本,有以下几种情况:
select * from table where ? lock in share mode;select * from table where ? for update;insert into table values (…);insert 可能会触发 unique 检查,也算当前读update table set ? where ?;delete from table where ?;
增删改本质上有两部分: 先将数据读取出来,再对数据进行修改。前一部分读取操作是当前读,需要获取最新版本的数据。为了防止其他并发的事务对数据进行修改,当前读需要对当前数据加上互斥锁,修改完成后才将锁释放,将数据的修改串行化,保证安全。
在数据库事务中,一般会有多条增删改查的语句,事务中数据上下文之间还可能会有相互依赖,这使得锁的情况变得复杂化,对应的事务有四大隔离级别,本文会涉及可重复读和读取已提交两种:
- Repeatable Read (RR) 针对当前读,RR 隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象 (事务期间多次当前读的结果一样)。 快照读通过创建事务级 ReadView 实现读取版本在事务期间不变。
- Read Committed (RC) 针对当前读,RC 隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象 (两次当前读的结果不一样)。 快照读通过创建语句级 ReadView,读取版本在事务期间可能会读到新更新的版本。
RR 和 RC 核心区别在与是否有间隙锁锁住区间,实现可重复读。RC 还有半一致性读等锁优化。
理清楚了背景知识,现在我们知道死锁的原因可能和当前读以及 RR 中的间隙锁有关。接下来从死锁本身的信息出发,梳理出问题的答案。
死锁过程分析
锁产生在当前读,所以需要回到执行计划,查看当前读如何进行。上文中的执行计划中可以看到,MySQL 使用了 index merge,使用两个索引分别读数据,然后将数据进行 intersect(取交集)。也就是说当前读发生在了两个索引上,这就是问题的关键。
接下来分析通过索引进行当前读的过程,以index_interval这个索引为例,这是一个二级索引,在 inndb 中,二级索引是一堆独立的数据,每个二级索引记录会持有一个主键 ID。
UPDATE `lists` SET `updated_at` = *** WHERE (`interval` = 1 and started_at = 4) --事务1
MySQL Server 通过条件 ( interval = 1) 在索引上进行当前读,会将 index_interval 这个二级索引中满足 interval = 1 全部返回,并加上互斥锁,避免数据被其他并发事务修改。(锁住二级索引)
因为要修改的数据是主键所在的行数据 (聚簇索引),所以第二步还需要通过二级索引对应的主键 ID 读取实际的数据。这也是一个当前读,读取之后会对数据加上互斥锁,锁住主键 (就是死锁日志中的 index PRIMARY ··· Record lock)。
为什么锁了二级索引还要锁住对应的主键呢?因为一个主键 ID 可能会被多个二级索引持有,其他二级索引过来的当前读也可能会修改主键索引。
如果隔离级别是 RR 的话,还需要用间隙锁锁住区间,示意图如下:
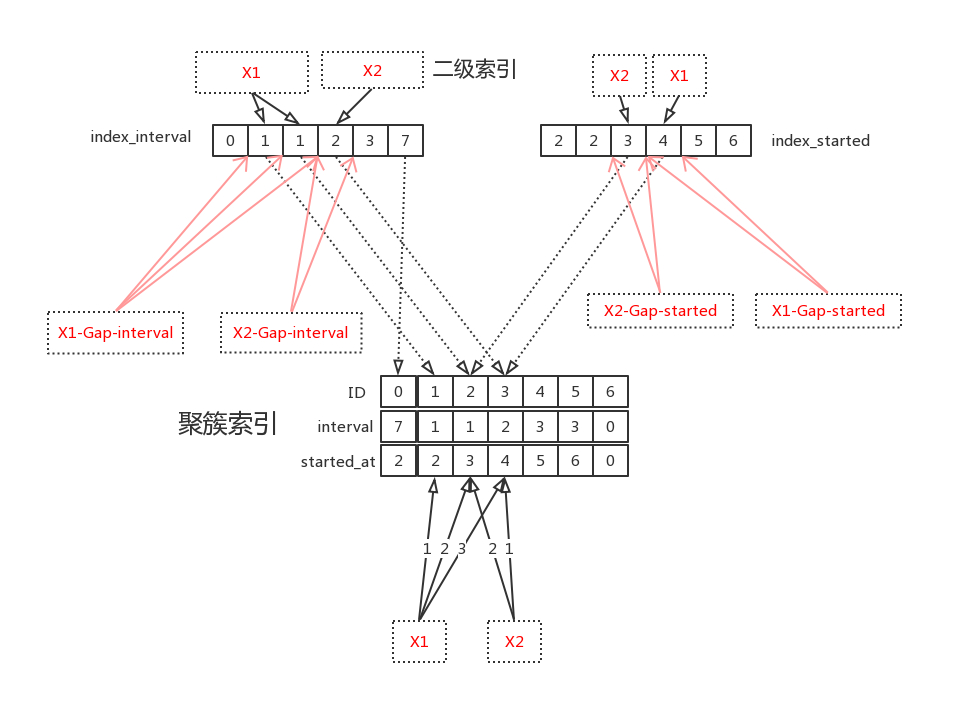
上图为锁示意图,其中 X1 表示事务 1 的互斥锁,同理事务 2,X1-Gap 表示事务 1 的间隙锁,同理事务 2,RC 级别下忽略间隙锁。
间隙锁用来锁住区间,防止在满足条件的区间中有新的数据插入进来,RR 下会导致幻读,比如事务 1:
UPDATE `lists` SET `updated_at` = *** WHERE (`interval` = 1 and started_at = 4) --事务1
UPDATE `lists` SET `updated_at` = *** WHERE (`interval` = 2 and started_at = 3) -- 事务2
通过 interval 进行当前读时,上图可见 index_interval 索引中只有一条数据,需要防止新的 interval=1 的数据插入进来,所以需要锁住区间。
因为二级索引是有序的,下一个 interval=1 的记录只会插入在 [0,1],[1,1],[1,2] 这三个位置 (X1-Gap-interval),所以将这三个间隙锁住,即可防止幻读。
以上交待了锁:互斥锁、间隙锁,以及锁施加的位置:二级索引、主键。搞清楚了这些细节后,接下来要进一步顺着执行计划搞清楚加锁的顺序。
设定两个条件:
- 假设执行计划先读 index_interval,再读 index_started (不重要)
- 假设数据库中的数据关系如上图(重要)
则事务 1 加锁的顺序依次是:
- interval [1,1]
- interval-Gap [0, 1], [1, 1], [1, 2]
- 主键 [1, 2]
- started_at [4]
- started-Gap [3, 4], [4, 5]
- 主键 [3]
事务 2 加锁的顺序依次是:
- interval [2]
- interval-Gap [1, 2], [2, 3]
- 主键 [3]
- started_at [3]
- started-Gap [2, 3], [3, 4]
- 主键 [2]
由以上可以看出,事务 1 和事务 2 对主键加锁的方向是相反的!!! 当出现以下时序即可出现死锁:
| 1. 事务 1 - 锁住主键 2 | |
| 2.事务 2 - 锁住主键 3 | |
| 3.事务 1 - 准备锁主键 3 -- 等待锁释放 | |
| 4. 事务 2 - 准备锁主键 2 -- 等待锁释放 |
死锁成功出现,这也是上文死锁出现的原因!!!
通过以上分析可知,死锁出现的原因和 index merge 有很大的关联,因为当前读锁住了一些本次 update 根本不需要的记录,而两条 update 语句锁住的无用记录刚好有重合的数据,同时因为数据分布的原因导致加锁的顺序刚好相反,导致死锁的发生。这一点在MySQL5.6 就有 bug 提出,index merge 增大了死锁的可能性。(5.7 还可以重现)
解决方案
通过上面的梳理,如果没有使用 index merge 则本案的死锁情况可以避免。所以加上一组联合索引即可解决本文场景下的死锁问题。(执行计划得用组合索引)
alter table lists add index u_started_at_interval(`started_at`, `interval`)
如上的二级索引有两层,第一层以 started_at 为序,第二层以 interval 为序,结构示例如下:
100(2,3,5,7,9), 101(70), 105(34,35,37,80) ···
100, 101, 105 为第一层 started_at, 括号内的为第二层,彼此都有序。当执行计划使用这个联合索引进行当前读时,因为二级索引有序,相同的条件当前读加锁的顺序是一样的,不会出现交叉,不同条件的当前读不会有重合的主键数据,这就避免了上面数据交叉且加锁顺序相反的情况,避开了死锁。
死锁的场景复杂多变,本案例只是九牛一毛,加联合索引的方案也只是减少了某种数据分布情况下的死锁概率。