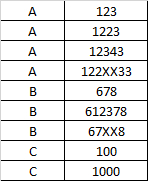
CSV 应该有个 header 的,可以利用inject,像这样:
data = [
{h1: 'A', h2: '123'},
{h1: 'A', h2: '1223'},
{h1: 'A', h2: '12343'},
{h1: 'A', h2: '123XX33'},
{h1: 'B', h2: '678'},
{h1: 'B', h2: '612378'},
{h1: 'B', h2: '67XX8'},
{h1: 'C', h2: '100'},
{h1: 'C', h2: '1000'}
]
data.inject({}) { |r, e| r[e[:h1]] = Array(r[e[:h1]]) << e[:h2]; r }
#=> {"A"=>["123", "1223", "12343", "123XX33"], "B"=>["678", "612378", "67XX8"], "C"=>["100", "1000"]}
# or
data.map{|x| Hash[*x.values]}.inject(&lambda{|x,y| x.merge(y){ |_, o, n| [o, n].flatten }})
#=> {"A"=>["123", "1223", "12343", "123XX33"], "B"=>["678", "612378", "67XX8"], "C"=>["100", "1000"]}