Ruby Ruby GC 自述
众所周知,Ruby(MRI) 中有三大神秘区域:
- GC
- GIL
- 编译/执行
我就是 CRuby 的 GC,虽然大多数人不了解我,或者了解了也没什么卵用。但我还是得向你介绍一下我自己。我在这几年改变了很多。
我是谁
程序员在构建应用程序的时候,或多或少都需要使用内存,在 C/C++ 中,绝大部分使用的内存都需要自己调用 API 去申请,用完了之后还要一点不剩地归还。这是一项繁琐且极易出 bug 的事,为了让程序员在这一过程中被解放出来,我及其众多兄弟就应运而生了。
在 Ruby 中,因为有我,你不用去管内存申请/释放这一过程。这样你可以更加专注于业务本身,节约时间去创造更多美妙的应用。
Ruby 的内存空间
为了实现内存管理的目的,我需要做到两件事情:
- 当你需要内存对象时,我直接给你,用完后你不用管后续。(申请)
- 自动回收没有被使用的垃圾对象。(回收)
为了让你能更清晰地了解上面的过程,我需要简单介绍一下,我是如何管理内存的,这涉及到了 Ruby 的内存空间。
ObjectSpace
我会在 Ruby 堆空间中维护一个对象池,这个对象池也被称作ObjectSpace,你所使用的所有 Ruby 对象都是从这个池子中取出的,而我也会去清理池子中已经没有被使用的对象,达到循环利用的目的。
ObjectSpace对象池是由很多堆页 (page) 构成的,每一个页的大小为 16Kb。每页中包含 408 个槽 (slot)。一个槽对应一个对象,你所使用的每一个对象都在对象池中占有一个槽。这些数据可以通过下面的方式得到:
GC::INTERNAL_CONSTANTS
=> {
:RVALUE_SIZE=>40, # 一个RVALUE结构体40个字节
:HEAP_PAGE_OBJ_LIMIT=>408,
# ...
}
RVALUE 结构体
当然,槽只是一个形象化的抽象表述,你可能更加关心槽里面的对象究竟是如何被表达的,因为 Ruby 中有很多种不同的对象,如何表达它们呢?答案是RVALUE结构体,每一个槽中躺的是一个RVALUE结构体。
//有删减
typedef struct RVALUE {
union {
struct {
unsigned long flags; /* 0 if not used */
struct RVALUE *next;
} free;
struct RBasic basic;
struct RObject object;
struct RClass klass;
struct RFloat flonum;
struct RString string;
struct RArray array;
struct RRegexp regexp;
struct RHash hash;
struct RData data;
struct RStruct rstruct;
struct RBignum bignum;
struct RFile file;
struct RNode node;
struct RMatch match;
struct RVarmap varmap;
struct SCOPE scope;
} as;
} RVALUE;
可以看到,结构体中通过 union 实现不同对象共用同一块内存,这里面包含了 Ruby 大部分的对象类型。一个RVALUE结构体可以表达大多数 Ruby 对象。(布尔/nil/简单立即数有更简单的表达方式)
当对象本身比较小时,比如一个小的字符串hello,它可以被直接嵌入到结构体中。但是如果字符串非常大时,结构体里面就放不下了。这时候,我会到 Ruby 堆中额外申请一块略大的内存,将数据放到这块内存中,然后在RVALUE中只存放这块内存的指针。
以上是我分配及管理对象的方式。接下来,可以介绍一下我是如何进行对象回收的了。
处理垃圾对象
垃圾对象就是已经不会被使用的对象,比如在 Rails 中一次请求中产生的临时对象,当请求完成后,这些对象就不会被再次使用了。它在ObjectSpace所占用的槽就应该让出来给新创建的对象使用。
我这几年的主要改动都是在回收算法上,这是一段有趣的历史,让我们先回到 1.8。
标记清除
从 Ruby1.8 开始 (大概),垃圾回收使用的是标记及清除算法。
当你在申请一个新的对象时,我会到ObjectSpace中去取一个对象给你,但是,我如果发现对象池已经满了,这时候我就会Stop the world,启动 GC(还有其他触发机制),开始标记算法,从根对象开始,递归遍历所有根对象及其引用的对象,将有用的对象标记一下 (修改 RVALUE 中的一个 bit)。这个过程完成之后,就开始清除算法,将所有没有被标记为有用的对象全部回收。
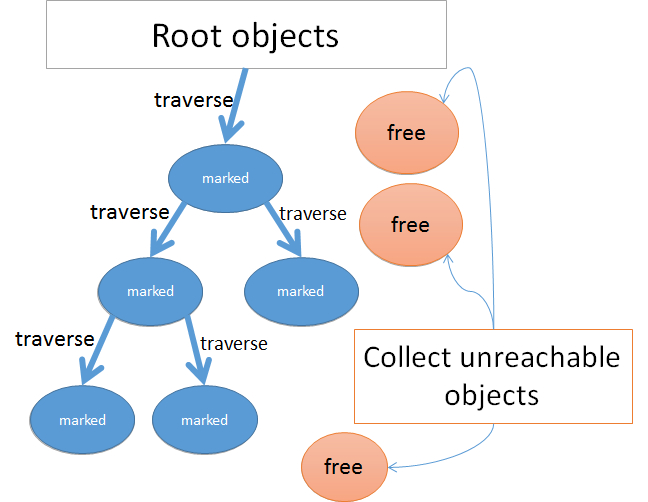
根对象及有用对象
这里有两个点需要进一步解释:
- 什么是根对象?
- 什么对象算是有用的?
根对象是当前 Ruby 程序明显需要的,包括 (不保证完整):
- 全局变量 (类、常量等)
- 本地变量(Ruby 当前堆栈信息)
- C 寄存器及堆栈数据
- 等等其他,进一步可参考这篇文章
有用的对象就是被根对象直接或间接引用的对象。当我标记清除完成之后,程序还要继续执行,如果明显需要的对象被回收了,那程序肯定就出错了。
标记清除缺点
标记&清除算法非常的简单,但是有非常大的缺点:
- 需要递归遍历根对象,如果根对象关联对象很多,那么需要判断栈溢出的情况,这增加了复杂度。
- 需要将所有未被标记的对象清除后,程序才能继续执行。
- 上面两个过程会造成
Stop the world的时间过长,导致程序中断过久。
延迟清除
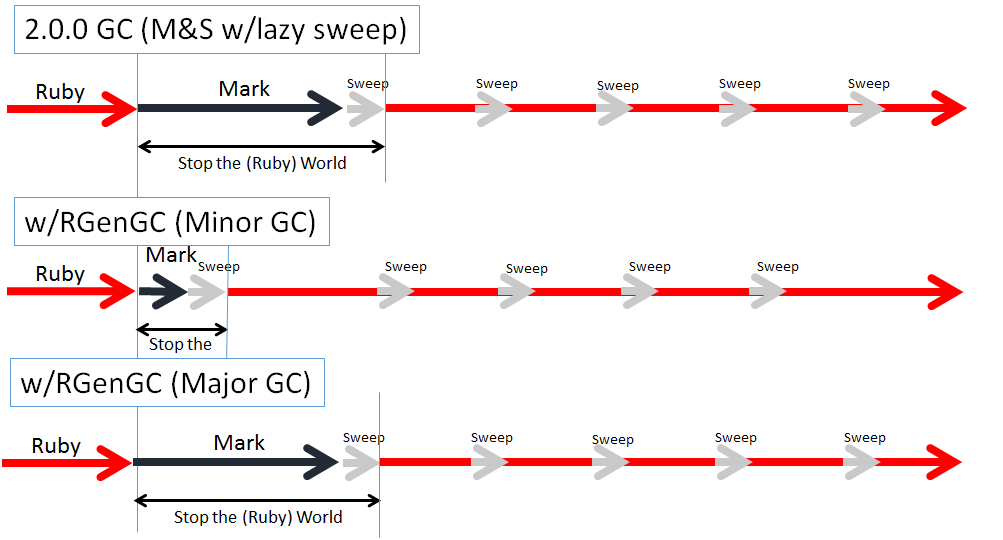
针对清除过程,在 1.9.3 中引入了延迟清除算法,就是在标记完成后,不一次性清除所有无用的对象,将清除的过程分散到后面的操作中,这大大降低了单次清除过程中的中断时间。
对 COW 友好
同样的,在 2.0 中引入了非递归标记算法,优化了标记过程,当然 2.0 中还引入了一个非常棒的特性,它让 Ruby 开始对copy on write变得友好。
了解COW的话,你会知道,当程序 fork 出子进程时,子进程可以共享父进程的数据,只有当父子进程中任意一个修改共享内存的数据时,才会触发复制,这提升了 fork 的性能。
在 Ruby 中 fork 后,一旦我开始运行,我会去标记有用的对象,标记的过程就会修改对象数据 (一个 bit 位),这会直接触发数据复制。COW的优点就不复存在了。
2.0 开始,标记过程中,我会维护相应的bitmap,将对象是否有用的信息映射到bitmap中。这样,我标记对象的时候,就不会去修改对象的数据,只会修改bitmap,这样就只会触发复制bitmap的数据,不会影响到其他 Ruby 对象。
伊甸页
标记的过程就是寻找那些需要进一步存活下去的对象。所有的对象都分布在 ObjectSpace 池的页中,可能存在会有很多页,对象也分散到这些页上。一次标记之后,对象就可以被分为两类,一种是标记存活的,第二种是没有被标记为存活的。
这样可以将 ObjectSpace 中的页也分为两类,一种是至少包含一个存活对象的页,成为伊甸页。第二种页中,对象全部都是未被标记存活的,称为坟墓页 (tomb pages)。
当伊甸页中的对象全部都不会继续存活时,这页会被移动到坟墓页中。当伊甸页中没有空闲的槽时,这些页又会被重新利用。
这样可以降低 ObjectSpace 中的伊甸页的内存碎片。当消耗了太多内存时,坟墓页所占的内存我也可能会还给操作系统,而大部分情况下都不会。因为向操作系统申请内存是非常昂贵的操作,而且说不定我刚归还了内存,你又突然需要它。为了性能,我就暂时保留在堆上了,这也就是很多人说我从来不归还内存给操作系统,其实有些时候,还是会的。(这个点很多资料说的很模糊,可能实际实现很复杂)
回到标记,整个过程还是很慢,接下来介绍关于我的进一步优化。
分代 GC
为了减小标记过程中的长暂停,RGenGC 应运而生。
在 Ruby 中绝大部分对象都是临时的,用完马上就可以被清除,而还有一些对象是会长期存在的。但是,在我之前的工作方式下,我每次都会去遍历所有根对象,包括会长期存在的对象,这很浪费时间。
RGenGC 会区别对待长期存在和短期存在的对象。标记过程会被分成两种,次标记 (minor marking) 针对短期对象,和主标记 (Major marking) 针对所有对象。(各自会维护独立的 bitmap 用作标记数据)
当一个对象在 3 次主标记之后都还存活着,那就会将它提升为老年对象。而每次次标记都只需要遍历新对象,这大大减少了每次标记的目标数据量,也提升了性能。
当次标记后对象池中的槽都还不够用时,会触发主标记 (还有其他触发的方式),主标记会像之前那样遍历所有对象。不过频率会低很多,大部分情况下会是次标记在工作,它非常快。
当新的对象被老年对象引用时,上面的工作方式会导致被老年对象引用的新对象被回收,这会引发问题。为了解决这个问题,一个叫做写屏障(write-barrier) 的技术被引入了。当新对象被老年对象引用时,会将新对象追加到一个remembered set中,次标记每次会去遍历这个 set,让对应拥有写屏障的新对象保持存活。在分代 GC 中也只有拥有写屏障的对象才能被提升为老年对象。

增量 GC( incremental)
因为主标记会一次遍历所有对象,当它执行时,程序还是会有较长的暂停。增量 GC 会将主标记拆分为数个小任务,每个任务分散在 Ruby 的执行中,这样单次的暂停时间就会变得很短。虽然总的标记时间可能还会变长,但是这个交易是值得的。

全量标记的过程和前面介绍的方式一样,从根对象开始依次遍历。增量标记就是每次只选择一个根对象进行遍历标记,这样将大任务拆成了小任务,分批执行。
增量 GC 的难点在于,在所有小标记任务未全部完成期间,如果有新的对象被创建了,而这个新对象又恰好被已经标记过的根对象引用了,那么这个新对象不会被标记为有用,在清除阶段就会被处理掉,这会引发严重问题。增量 GC 用了三色及写屏障的巧妙算法解决了分批执行带来的这一问题:
所有对象刚开始都是白色
直接引用了其他对象的为黑色,被引用的是灰色,灰色会被追加到一个队列中。
依次取灰色对象 (刚开始时没有灰色对象就取根对象) 进行标记,将其直接或间接引用的对象也标记为灰色,到末尾时将自己修改为黑色 (也从队列中剔除)。当所有对象中只有白色和黑色时,标记完成。
直接将白色对象清除掉,黑色是被需要的对象,清除完成。
如果过程中出现了已标记对象引用了新对象,也就是黑色对象引用了白色对象,那么写屏障 (对某种条件进行过滤的代码) 会检测到这种情况,并将该黑色对象修改为灰色对象,这个对象也就会重新走上面的第 3 步,如此便解决了上述增量 GC 的难点。由于篇幅原因,详情可以参考这篇文章。
符号 GC(symbol GC)
Ruby 中 symbol 不会被我回收,这可能会引发问题,最严重的被称为Symbol洪水攻击。在 Rails 中,用户输入的参数会被转为用 symbol 表达,而这些 symbol 又不会被回收,如果有恶意用户一直输入不同的参数的话,Rails 服务的进程就会消耗大量的内存,进而引发应用崩溃。
Ruby2.2 引入了符号 GC。它会回收部分 symbol,比如用户输入产生的,这样就避免了这个问题。
有什么用
花了这么大的篇幅来做自我介绍,究竟有什么用?知道我是如何工作的,也许可以让你写出对我更加友好的代码,这样可以节省内存,减少我执行的次数,进而提升系统性能。
我能告诉你的东西很少,也只有下面这些点:
- 尽量使用最新版本的 Ruby,我的性能会更好。
- 尽量少创建新的对象。复用旧对象。
- 不要一次性创建大量的对象,例如在一次 HTTP 请求中产生大量临时对象。
- 尝试使用 jemalloc 代替 malloc,内存碎片会更低。
- ...
