Gem Sidekiq 任务调度流程分析
sidekiq是 Ruby 中一个非常优秀而且可靠的后台任务处理软件,其依赖 Redis 实现队列任务的增加、重试以及调度等。而 sidekiq 从启动到开始不断处理任务、定时任务以及失败任务的重试,都是如何调度的呢?遇到问题的时候,又该如何调优呢?
注意
- 今天的分析所参考的 sidekiq 的源码对应版本是 4.2.3;
- 今天所讨论的内容,将主要围绕任务调度过程进行分析,无关细节将不赘述,如有需要,请自行翻阅 sidekiq 源码;
- 文章内容真的很长,请做好心理准备(借用下我在 SegmentFault 博客自动生成的目录树,话说好想给社区也实现一个,很贴心很方便)。

你将了解到什么?
- sidekiq 的任务调度机制:定时任务、重试任务的检查机制,队列任务的排队以及队列权重对处理优先级的影响;
- sidekiq 的中间件机制以及在此基础上实现的任务重试机制。
先抛结论
时序图
对于复杂的调用关系,我习惯用时序图帮助我理解其中各部分代码之间相互协作的关系(注意:为了避免太多细节造成阅读负担,我将参数传递以及返回值等冗杂过程去除了,只保留与任务调度相关的关键调用):
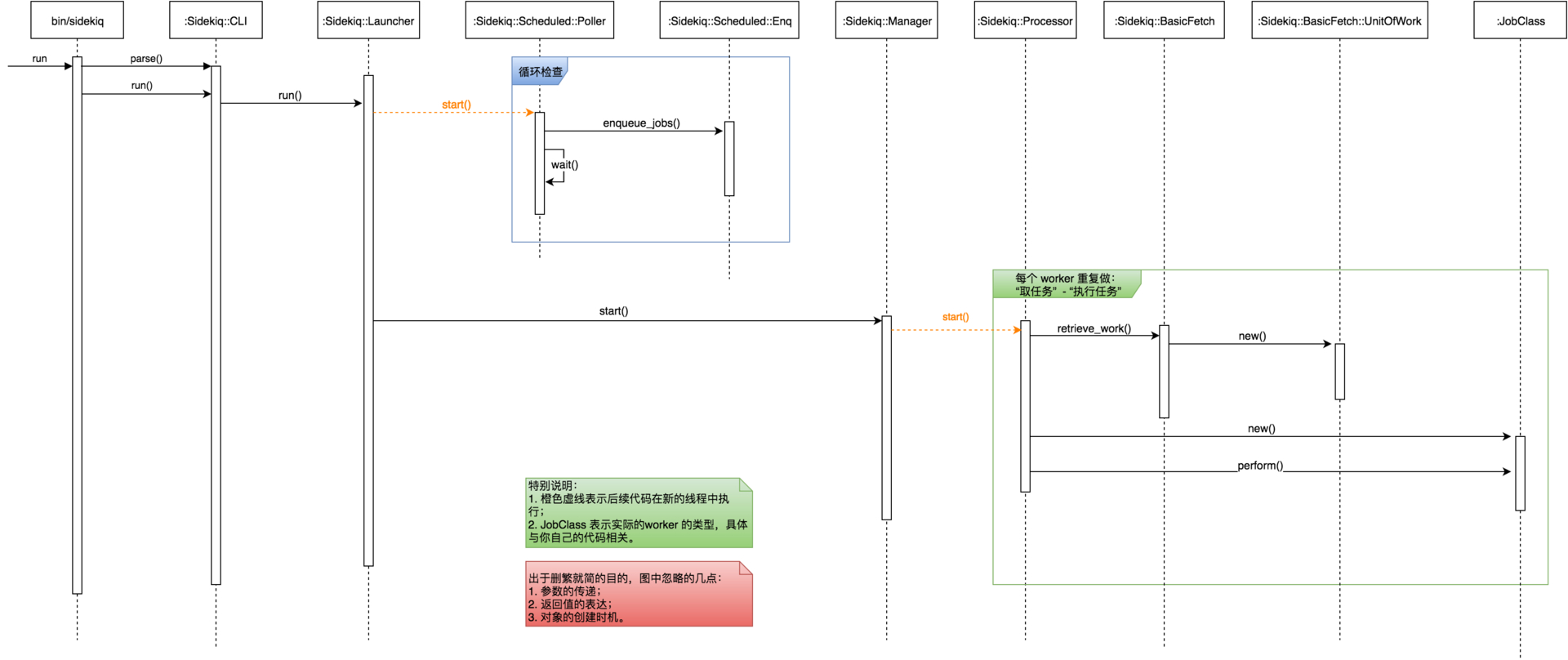
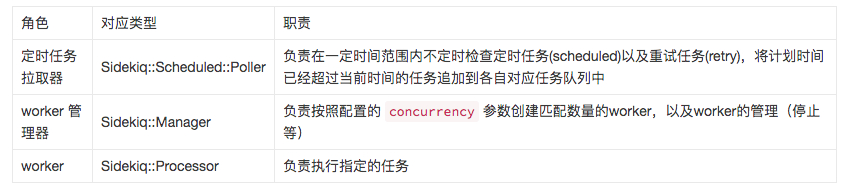
人话
Sidekiq 整个任务调度过程中依赖几个不同角色的代码共同协作,其分工如下:
源码之旅 —— 启动
当我们在执行 sidekiq 时,源码中的 bin/sidekiq.rb 文件便是第一个开始执行的文件,让我们看看里边的主要代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/bin/sidekiq#L9-L12
begin
cli = Sidekiq::CLI.instance
cli.parse
cli.run # <===== 这边走
# ...
紧靠 begin 后边的两行代码首先创建 Sidekiq::CLI 类的一个实例,接着调用实例方法 #parse 解析 sidekiq 的配置参数,其中包括队列的配置、worker 数量的配置等,在此不展开了。接着实例方法 #run 将带着我们继续往下走,让我们继续看 lib/sidekiq/cli.rb 里边的代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/cli.rb#L46-L106
def run
# 这里打印控制台欢迎信息、打印日志以及运行环境(不同 Rails 版本)加载等
require 'sidekiq/launcher'
@launcher = Sidekiq::Launcher.new(options)
begin
launcher.run # <===== 这边走
# 进程接收到的信号处理以及退出处理
end
上面的代码主要是实例化了一个 Sidekiq::Launcher 的对象,紧随其后又调用了实例方法 #run,所以让我们继续顺藤摸瓜,看看 Sidekiq::Launcher#run 方法到底做了哪些事情?
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/launcher.rb#L24-L28
def run
@thread = safe_thread("heartbeat", &method(:start_heartbeat))
@poller.start
@manager.start
end
#run 方法首先通过 safe_thread 创建了一个新的线程,线程主要负责执行 start_heartbeat 方法的代码,从方法名称上,我们猜测其主要是心跳代码,负责定时检查 sidekiq 健康状态,跟之前一样,这里不往下挖,我们继续看后边的两行代码:
@poller.start
@manager.start
这里的 @poller 跟 @manager 都是什么呢?让我们回头看一下,前面讲到 lib/cli.rb 的 #run 方法会负责创建 Sidekiq::Launcher 的实例,那让我们看下后者的 initialize 方法定义:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/launcher.rb#L17-L22
def initialize(options)
@manager = Sidekiq::Manager.new(options)
@poller = Sidekiq::Scheduled::Poller.new
@done = false
@options = options
end
可以看到,实际上,@manager是在创建 Sidekiq::Launcher 实例的过程中同步创建的 Sidekiq::Manager 的实例,同理,@poller 是同步创建的 Sidekiq::Scheduled::Poller的实例。那我们按照代码执行顺序,先看下 @poller.start 也就是 Sidekiq::Scheduled::Poller#start 方法的定义:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L63-L73
def start
@thread ||= safe_thread("scheduler") do
initial_wait
while !@done
enqueue
wait
end
Sidekiq.logger.info("Scheduler exiting...")
end
end
这里看到,#start方法也创建了一个线程,在线程里执行了两个部分代码:1. 初始化等待;2. 循环里的 enqueue 与 wait。这都是什么呢?
注意: #start 方法在线程创建完成后就立刻返回了,至于 #start 方法里的逻辑,请移步后面章节“继续深挖 Sidekiq::Scheduled::Poller#start”作更深一步分析。这里,我们先继续接着看看 #start 方法返回后接下来执行的 @manager.start 方法又做了什么:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/manager.rb#L45-L49
def start
@workers.each do |x|
x.start
end
end
这里的 @workers 又是什么?一个数组?怎样的数组?我们回顾下,前面说在创建 Sidekiq::Launcher 实例的过程中同步创建了 Sidekiq::Manager 的实例,让我们就看看 Sidekiq::Manager 的 #initialize 方法:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/manager.rb#L31-L43
def initialize(options={})
logger.debug { options.inspect }
@options = options
@count = options[:concurrency] || 25
raise ArgumentError, "Concurrency of #{@count} is not supported" if @count < 1
@done = false
@workers = Set.new
@count.times do
@workers << Processor.new(self)
end
@plock = Mutex.new
end
可以看到,在创建了 Sidekiq::Manager 的实例之后,又同步创建了多个 Sidekiq::Processor 的实例,实例的个数取决于 options[:concurrency] || 25,也就是配置的 :concurrency 的值,缺省值为 25。至此,我们知道,sidekiq 中的 worker 的数量就是在此其作用的,Sidekiq::Manager 按照配置的数量创建指定数量的 worker。
往回看刚才的 #start 方法中:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/manager.rb#L46-L48
@workers.each do |x|
x.start
end
简言之,就是 Sidekiq::Manager 在 start 的时候只做一件事:分别调用其管理的所有 worker 的 #start 方法,也就是 Sidekiq::Processor#start。继续往下走:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L60-L62
def start
@thread ||= safe_thread("processor", &method(:run))
end
又是我们熟悉的 safe_thread 方法,同样是创建了一个新的线程,意味着每一个 worker 都是基于自己的一个新线程的,而这个线程里执行的代码是私有方法 #run 里的代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L66-L77
def run
begin
while !@done
process_one
end
@mgr.processor_stopped(self)
rescue Sidekiq::Shutdown
@mgr.processor_stopped(self)
rescue Exception => ex
@mgr.processor_died(self, ex)
end
end
可以发现,又是一个 while 循环!而这个循环体里只调用了一个 #process_one 实例方法,顾名思义,这里是说每个 worker 在没被结束之前,都重复每次处理一个新的任务,那这个 #process_one 里又做了什么呢?怎么决定该先做哪个任务呢?别急,请看后面章节“继续深挖 Sidekiq::Processor#process_one”。
小结
sidekiq 在启动后(此处可借文章开头的时序图辅助理解):
- 首先创建了
Sidekiq::CLI的实例,并调用其run方法; -
Sidekiq::CLI的实例在#run的过程中,创建了Sidekiq::Launcher的实例,并调用其run方法; -
Sidekiq::Launcher的实例在创建后,同步创建了一个Sidekiq::Scheduled::Poller的实例以及Sidekiq::Manager的实例,而在其执行#run的过程中,则分别调用了这两个实例的start方法; -
Sidekiq::Scheduled::Poller的实例在执行start过程中,创建了一个内部循环执行的线程,周而复始地执行enqueue->wait; -
Sidekiq::Manager的实例在创建后,同步创建若干个指定的 worker,也就是Sidekiq::Processor的实例,并在执行start方法的过程中对每一个 worker 发起start调用; -
Sidekiq::Processor实例在执行start方法的过程中创建了一个新的线程,新的线程里同样有一个while循环,反复执行process_one。
以上就是 Sidekiq 的主要启动过程,以下分别针对 Sidekiq::Scheduled::Poller 以及 Sidekiq::Manager 展开源码分析。
定时任务拉取器的工作 Sidekiq::Scheduled::Poller#start
经过前面较表层的代码分析,我们接下来继续展开 Sidekiq::Scheduled::Poller#start 方法的探索之旅,首先重温下其代码定义:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L63-L73
def start
@thread ||= safe_thread("scheduler") do
initial_wait
while !@done
enqueue
wait
end
Sidekiq.logger.info("Scheduler exiting...")
end
end
可以看到,#start 方法的核心就是中间的 while 循环,在循环前面,执行了 #initial_wait 方法,让我们先看看这个方法到底是干些什么的:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L133-L143
def initial_wait
# Have all processes sleep between 5-15 seconds. 10 seconds
# to give time for the heartbeat to register (if the poll interval is going to be calculated by the number
# of workers), and 5 random seconds to ensure they don't all hit Redis at the same time.
total = 0
total += INITIAL_WAIT unless Sidekiq.options[:poll_interval_average]
total += (5 * rand)
@sleeper.pop(total)
rescue Timeout::Error
end
结合注释理解,原来私有方法 #initial_wait 只是为了避免所有进程在后续逻辑中同时触发 Redis IO 而做的设计,如果对大型系统有过架构经验的童鞋就会明白,这里其实就是为了防止类似雪崩之类的系统故障出现。让当前进程随机等待一定范围的时间,从而就可以跟其他进程错开了。
在理解完 initial_wait 之后,我们接着看到循环体里的代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L68-L69
enqueue
wait
enqueue?干嘛呢?为什么是入队列呢?带着疑问往下看:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L75-L86
def enqueue
begin
@enq.enqueue_jobs
rescue => ex
# ...
end
end
这里看到 #enqueue 代码非常简单,只是调用了实例变量 @enq 的 #enqueue_jobs 方法而已,那么,@enq 是什么类型的实例呢?它的 #enqueue_jobs 方法又做了什么呢?让我们回过头来看一遍 Sidekiq::Scheduled::Poller 的 #initialize 方法:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L45-L50
def initialize
@enq = (Sidekiq.options[:scheduled_enq] || Sidekiq::Scheduled::Enq).new
@sleeper = ConnectionPool::TimedStack.new
# ...
end
原来缺省情况下,@enq 就是 Sidekiq::Scheduled::Enq 的实例。而代码上看的话,sidekiq 支持用户通过 :scheduled_enq 配置项自定义 @enq 的类型,但是官方文档未对此参数提及以及说明,这里其实是一种策略模式的实现,用户自定义的类型必须实现 enqueue_jobs 方法。我估计,是 sidekiq pro 里边才会用到的配置项吧。
知道了 @enq 的类型后,让我们继续看下 Sidekiq::Scheduled::Enq#enqueue_jobs 方法的定义:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L11-L33
def enqueue_jobs(now=Time.now.to_f.to_s, sorted_sets=SETS)
# A job's "score" in Redis is the time at which it should be processed.
# Just check Redis for the set of jobs with a timestamp before now.
Sidekiq.redis do |conn|
sorted_sets.each do |sorted_set|
# Get the next item in the queue if it's score (time to execute) is <= now.
# We need to go through the list one at a time to reduce the risk of something
# going wrong between the time jobs are popped from the scheduled queue and when
# they are pushed onto a work queue and losing the jobs.
while job = conn.zrangebyscore(sorted_set, '-inf'.freeze, now, :limit => [0, 1]).first do
# Pop item off the queue and add it to the work queue. If the job can't be popped from
# the queue, it's because another process already popped it so we can move on to the
# next one.
if conn.zrem(sorted_set, job)
Sidekiq::Client.push(Sidekiq.load_json(job))
Sidekiq::Logging.logger.debug { "enqueued #{sorted_set}: #{job}" }
end
end
end
end
其实这里这个方法的寓意,通过代码里的注释都已经很明晰了,不过我觉得还是有几个点需要强调下。
首先,在无参数调用 #enqueue_jobs 方法时,定义中的参数 now 缺省为当前时间,而 sorted_sets 缺省为 Sidekiq::Scheduled::SETS 的值,其值定义为:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L8
SETS = %w(retry schedule)
也就是数组 ["retry", "schedule"],而这两个队列名称所对应的队列就是 sidekiq 的重试以及定时任务队列,在 sidekiq 里边,重试任务以及定时任务本质上都是 scheduled jobs,这两个队列使用了特殊的 Redis 的数据结构,进入队列的任务以其执行时间作为数据的 score,写入 Redis 之后按照 score 排序,也就是按任务的计划时间排序。
接着往下看:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L14-L30
Sidekiq.redis do |conn|
sorted_sets.each do |sorted_set|
while job = conn.zrangebyscore(sorted_set, '-inf'.freeze, now, :limit => [0, 1]).first do
if conn.zrem(sorted_set, job)
Sidekiq::Client.push(Sidekiq.load_json(job))
Sidekiq::Logging.logger.debug { "enqueued #{sorted_set}: #{job}" }
end
end
end
end
可以看到,sidekiq 分别针对 "retry" 和 "schedule" 队列做了一个循环,循环体里每次通过 Redis 的 ZRANGEBYSCORE命令取出一个计划时间小于等于当前时间的任务,并且调用 Sidekiq::Client 的 .push 方法将此任务加到指定队列中(job 中包含队列名称等信息,在此不展开,有兴趣的同学请自行阅读 Sidekiq::Client 的代码)。
至此,可以明白,enqueue_jobs 就是分别从 "retry" 和 "schedule" 队列中取出已经到达计划时间的任务,将其一一加入原来队列。注意,定时任务以及重试任务的计划时间只是计划加进执行中队列的时间,并非执行时间,执行的时间就只能取决于队列的长度以及队列执行速度了。
接着往回点,继续看 enqueue_jobs 之后的 wait 方法:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L90-L100
def wait
@sleeper.pop(random_poll_interval)
rescue Timeout::Error
# expected
rescue => ex
#...
end
这里的 wait 方法只是做一个休眠,休眠的实现依赖于 @sleeper 的 #pop 方法调用,回顾 Sidekiq::Scheduled::Poller 的 #initialize 方法的实现可以确认 @sleeper 是 ConnectionPool::TimedStack 的实例,而后者是 Ruby gem connection_pool 里的实现,其 pop 方法会阻塞当前代码的执行,直到有值返回或者到达指定的超时时间,这里 sidekiq 利用了其阻塞的特性,作为 wait 方法休眠器的实现。
而代码里的休眠时间则不是固定的,依赖 #random_poll_interval 方法的实现:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L103-L105
# Calculates a random interval that is ±50% the desired average.
def random_poll_interval
poll_interval_average * rand + poll_interval_average.to_f / 2
end
其实现依赖一个 #poll_interval_average 方法的返回值,顾名思义,这个方法将决定定时任务定期检查的平均时间周期。让我们继续深挖下去:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L107-L122
# We do our best to tune the poll interval to the size of the active Sidekiq
# cluster. If you have 30 processes and poll every 15 seconds, that means one
# Sidekiq is checking Redis every 0.5 seconds - way too often for most people
# and really bad if the retry or scheduled sets are large.
#
# Instead try to avoid polling more than once every 15 seconds. If you have
# 30 Sidekiq processes, we'll poll every 30 * 15 or 450 seconds.
# To keep things statistically random, we'll sleep a random amount between
# 225 and 675 seconds for each poll or 450 seconds on average. Otherwise restarting
# all your Sidekiq processes at the same time will lead to them all polling at
# the same time: the thundering herd problem.
#
# We only do this if poll_interval_average is unset (the default).
def poll_interval_average
Sidekiq.options[:poll_interval_average] ||= scaled_poll_interval
end
这个方法的重要性通过其几倍于代码的注释就可以看出来,大概意思是,sidekiq 为了避免在进程重启后,有大量的进程同时密集地访问 redis,所以设计了这个机制,就是每个进程对定时任务的检查都是按照一个公式来计算的,保证每个进程两次检查之间的平均休眠时间能够在一个范围内动态变化,从而将所有进程的 Redis IO 均匀错开。
从代码上看,sidekiq 的这个平均拉取时间支持配置项配置,但是目前也并没有在 wiki 上有所提及。而缺省情况下,其值由方法 #scaled_poll_interval 决定:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/scheduled.rb#L124-L131
def scaled_poll_interval
pcount = Sidekiq::ProcessSet.new.size
pcount = 1 if pcount == 0
pcount * Sidekiq.options[:average_scheduled_poll_interval]
end
正如前面一段代码的注释所说,缺省情况下,sidekiq 认为定时任务拉取器的平均休眠时间正是:
sidekiq 进程数量 x 平均拉取时间 average_scheduled_poll_interval
而 :average_scheduled_poll_interval 的缺省配置是 15 秒:
# https://github.com/mperham/sidekiq/blob/master/lib/sidekiq.rb#L25
DEFAULTS = {
# ...
average_scheduled_poll_interval: 15,
# ...
所以回过头来,在没有相关自定义配置的情况下,假设你只开启了一个 sidekiq 进程,那么 sidekiq 的定时任务拉取器的拉取时间平均间隔为 1 x 15 = 15 秒,那按照上面的 #random_poll_interval 方法的定义,则实际每次拉取的时间间隔则是在 7.5 秒到 22.5 秒之间!
小结
从这个章节的分析,我们可以明白 Sidekiq 对定时任务和重试任务是一视同仁的,其处理流程都是:
- 所有定时任务(包括重试任务,本质上重试任务也是定时的,后边会单独讲解)以其计划时间为 score,加入特殊的
"retry"或"schedule"有序队列中; - sidekiq 的定时任务拉取器从
"retry"和"schedule"队列中一一取出已到达计划时间的任务,将其加入该任务计划的队列中,后续的执行则跟其他普通队列中的任务一致; - 拉取器休眠一定时间(
random_poll_interval)后,从步骤 2 重新开始,周而复始。
所以,定时任务的计划时间不是确切的任务时间!只是允许加回队列的时间,具体执行时间还得另外看队列长度以及队列处理速度!
Sidekie worker 的秘密:Sidekiq::Processor#process_one
前面我们分析过 sidekiq 的 worker 的核心代码就是在线程里循环执行 #process_one 方法,那么这个方法到底做了些什么啊?别急,现在就来一探究竟:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L79-L83
def process_one
@job = fetch
process(@job) if @job
@job = nil
end
代码中,#process_one 先通过 #fetch 方法获取一个任务,当任务获取成功后,就将其作为参数调用 #process 方法,完成对任务的处理;如果没有获取到任务,则直接重新尝试获取新的任务。
首先让我们看看 #fetch 方法的实现:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L96-L104
def fetch
j = get_one # 吐槽一下这个 `j` 变量,命名真的不敢恭维,这个库就这里写得不雅
if j && @done
j.requeue
nil
else
j
end
end
#fetch 方法通过 #get_one 方法从队列中获取任务,当获取到任务后,判断当前 worker 是否已经停止 (@done 为 true),是则将任务重新压回队列。
让我们接着看 #get_one 方法的实现:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L85-L94
def get_one
begin
work = @strategy.retrieve_work
(logger.info { "Redis is online, #{Time.now - @down} sec downtime" }; @down = nil) if @down
work
rescue Sidekiq::Shutdown
rescue => ex
handle_fetch_exception(ex)
end
end
核心代码则是 work = @strategy.retrieve_work,为了了解 @strategy,我们仍旧往回看#initialize 方法的定义:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L32-L40
def initialize(mgr)
# ...
@strategy = (mgr.options[:fetch] || Sidekiq::BasicFetch).new(mgr.options)
# ...
end
又是一个策略模式,缺省下,使用了 Sidekiq::BasicFetch 生成实例,并且通过实例变量 @strategy 引用。
回到前面的 @strategy.retrieve_work,让我们继续看看 Sidekiq::BasicFetch#retrieve_work 的实现:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/fetch.rb#L35-L38
def retrieve_work
work = Sidekiq.redis { |conn| conn.brpop(*queues_cmd) }
UnitOfWork.new(*work) if work
end
通过上面的代码,可以知道 Sidekiq::BasicFetch 的取任务逻辑比较直接,是通过 Redis 的 BRPOP 命令从“所有队列”中阻塞地取出第一个任务:
BRPOP is a blocking list pop primitive. It is the blocking version of RPOP because it blocks the connection when there are no elements to pop from any of the given lists. An element is popped from the tail of the first list that is non-empty, with the given keys being checked in the order that they are given.
所以,理解了 BRPOP 命令的工作细节之后,我们把注意力缩放到 #queues_cmd 方法上:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/fetch.rb#L40-L53
def queues_cmd
if @strictly_ordered_queues
@queues
else
queues = @queues.shuffle.uniq
queues << TIMEOUT
queues
end
end
首先,代码中检查了 @strictly_ordered_queues 这个实例变量的值,让我们回头看下这个变量的值的来源,也就是 #initialize 方法的定义:
# https://github.com/mperham/sidekiq/blob/d8f11c26518dbe967880f76fd23bb99e9d2411d5/lib/sidekiq/fetch.rb#L26-L33
def initialize(options)
@strictly_ordered_queues = !!options[:strict]
@queues = options[:queues].map { |q| "queue:#{q}" }
if @strictly_ordered_queues
@queues = @queues.uniq
@queues << TIMEOUT
end
end
end
缺省情况下,此值为 false。所以让我们看 #queues_cmd 方法的 else 分支里的代码:
queues = @queues.shuffle.uniq
而这里的 @queues 就是来自 options[:queues] 中的配置: options[:queues].map { |q| "queue:#{q}" }。那么,这个 options[:queues] 的值又是什么呢?
让我们一步一步沿着调用链上参数往回走:
-
Sidekiq::BasicFetch.new的参数options来自 worker 在Sidekiq::Processor#initialize方法中的参数mgr的options属性; - worker 的 mgr 参数正是
Sidekiq::Manager的实例,其options属性则是Sidekiq::Launcher创建Sidekiq::Manager实例时传入的options变量; - 而
Sidekiq::Launcher#initialize接收到的options变量则是更外层的Sidekiq::CLI的实例方法options的值; - 而
Sidekiq::CLI的实例的options则是在其接收到#parse调用时设置的。 为了节省篇幅,省略这里其中的太多调用栈,我们直接看最根源代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/cli.rb#L389-L399
def parse_queues(opts, queues_and_weights)
queues_and_weights.each { |queue_and_weight| parse_queue(opts, *queue_and_weight) }
end
def parse_queue(opts, q, weight=nil)
[weight.to_i, 1].max.times do
(opts[:queues] ||= []) << q
end
opts[:strict] = false if weight.to_i > 0
end
可以看到,sidekiq 在解析 :queues 的相关配置时,按照每个队列以及其权重,生成了一个重复次数等于队列权重的队列的新数组,假设用户提供如下配置:
:queues:
- default
- [myqueue, 2]
则此处生成的 options[:queues] 则为 ["default", "myqueue", "myqueue"]。所以,这里权重主要用于后边确定各个不同队列被处理到的优先权的比重。
了解了 @queues 的来源之后,我们回到最开始讨论的地方:
queues = @queues.shuffle.uniq
也就是说,每次 worker 在请求新的任务时,sidekiq 都按照原来的 @queues 执行 shuffle 方法,而 shuffle 则表示将数组元素重新随机排序,亦即“洗牌”。结合前面的权重,那么每个队列洗牌后排在第一位的概率与其权重挂钩。最后的 #uniq 方法确保队列名称没有重复,避免 Redis 在执行 BRPOP 命令时重复检查同一队列。这里使用 BRPOP 还有个好处就是,加入当前面优先的队列里边没有任务时,可以依次将机会让给后面的队列。
而后边的:
queues << TIMEOUT
则是在命令末尾追加超时设定,即 Redis 的 BRPOP 命令最多阻塞 2 秒,超时则直接放弃。
了解了任务的获取之后,我们接着看 sidekiq 如何处理获取到的任务,回到 retrieve_work 的代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/fetch.rb#L36-L37
work = Sidekiq.redis { |conn| conn.brpop(*queues_cmd) }
UnitOfWork.new(*work) if work
看到在获取到任务之后,任务通过 Sidekiq::BasicFetch::UnitOfWork 结构体实例化后返回给调用方。
直接回到 Sidekiq::Processor#process_one:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L79-L83
def process_one
@job = fetch
process(@job) if @job
@job = nil
end
可以明白,@job 就是返回的 UnitOfWork 实例,那么 process(@job) 会做些什么呢?
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L118-L152
def process(work)
jobstr = work.job
queue = work.queue_name
@reloader.call do
ack = false
begin
job = Sidekiq.load_json(jobstr)
klass = job['class'.freeze].constantize
worker = klass.new
worker.jid = job['jid'.freeze]
stats(worker, job, queue) do
Sidekiq.server_middleware.invoke(worker, job, queue) do
# Only ack if we either attempted to start this job or
# successfully completed it. This prevents us from
# losing jobs if a middleware raises an exception before yielding
ack = true
execute_job(worker, cloned(job['args'.freeze]))
end
end
# ...
上面代码中,sidekiq 从 work 中获取任务的相关信息,包括队列名称,任务对应的类型(job['class'.freeze])、任务调用所需的参数等,根据这些信息重新实例化任务对象,并且将实例化的任务对象 worker 以及任务参数都传递给对 execute_job 的调用。让我们看看 #execute_job 的实现:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L154-L156
def execute_job(worker, cloned_args)
worker.perform(*cloned_args)
end
看到了吧?我们最熟悉的 #perform 方法!这下知道我们为什么需要在每个 sidekiq Worker 或者 ActiveJob 的 Job 类中定义这个方法了吧?因为这个方法就是最终任务执行时所需调用的方法,这就是约定!
至此,任务的调度过程就到此为止了,剩下的就是周而复始的重复了。
小结
经过上面的分析,我们可以明白 sidekiq 中 worker 的工作流程:
- 按照所有队列以及其权重,每次重新排列待处理队列顺序,高权重的队列有更高的优先级;
- 将重新排好的队列顺序传递给 Redis 的 BRPOP 命令,同时设置 2 秒超时;
- sidekiq 将从队列中获取到的任务实例化,并且根据携带的参数调用了任务的
#perform方法。
等等,上面都只是正常流程,那如果任务执行过程中出错了怎么办???重试的机制是如何运转的呢?
重试机制:基于中间件的实现
注意:阅读本章节前,建议先阅读官方 Wiki 的 Error Handling。
细心的童鞋肯定发现了上面的 Sidekiq::Processor#process 方法中有个关键的代码:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/processor.rb#L131-L137
Sidekiq.server_middleware.invoke(worker, job, queue) do
# ...
execute_job(worker, cloned(job['args'.freeze]))
end
这个 server_middleware 是什么呢?让我们来简单过一下吧:
全局搜索了代码,发现 Sidekiq.server_middleware 的来源是:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq.rb#L140-L144
def self.server_middleware
@server_chain ||= default_server_middleware
yield @server_chain if block_given?
@server_chain
end
缺省情况下,.server_middleware 依赖 .default_server_middleware 的实现:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq.rb#L146-L154
def self.default_server_middleware
#...
Middleware::Chain.new do |m|
m.add Middleware::Server::Logging
m.add Middleware::Server::RetryJobs
end
end
可以明白 Sidekiq.default_server_middleware 返回一个 Middleware::Chain 实例,并且调用了其 #add 方法将 Middleware::Server::Logging 以及 Middleware::Server::RetryJobs 两个中间件加到中间件的 Chain 上。此中间件的实现以及实现类似 rackup,有兴趣的童鞋自行阅读源码,在此不展开,让我们直接跳到 Middleware::Server::RetryJobs 的 call 方法中:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/middleware/server/retry_jobs.rb#L73-L84
def call(worker, msg, queue)
yield
rescue Sidekiq::Shutdown
# ignore, will be pushed back onto queue during hard_shutdown
raise
rescue Exception => e
# ignore, will be pushed back onto queue during hard_shutdown
raise Sidekiq::Shutdown if exception_caused_by_shutdown?(e)
raise e unless msg['retry']
attempt_retry(worker, msg, queue, e)
end
让我们聚焦方法的最后一行代码 attempt_retry(worker, msg, queue, e),此处表示当执行中的任务出现异常时,除去停机的因素以及禁用了重试机制后,尝试进行下次重试运行:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/middleware/server/retry_jobs.rb#L88-L137
def attempt_retry(worker, msg, queue, exception)
max_retry_attempts = retry_attempts_from(msg['retry'], @max_retries)
# ...
count = if msg['retry_count']
msg['retried_at'] = Time.now.to_f
msg['retry_count'] += 1
else
msg['failed_at'] = Time.now.to_f
msg['retry_count'] = 0
end
# ...
if count < max_retry_attempts
delay = delay_for(worker, count, exception)
logger.debug { "Failure! Retry #{count} in #{delay} seconds" }
retry_at = Time.now.to_f + delay
payload = Sidekiq.dump_json(msg)
Sidekiq.redis do |conn|
conn.zadd('retry', retry_at.to_s, payload)
end
else
# Goodbye dear message, you (re)tried your best I'm sure.
retries_exhausted(worker, msg, exception)
end
raise exception
end
从上面的代码中看出,sidekiq 在捕捉到异常后,首先检查此任务此前是否已经重试过,是的话,则在重试累计次数上加 1,更新最后重试时间;否则初始化重试累计次数为 0,设定初次失败时间。接着,sidekiq 检查重试累计次数是否超过限定最大重试次数,是的话则放弃重试,任务从此不再重试,进入 Dead 状态,sidekiq 抛出异常;否则计算任务下次重试时间,将任务按照计划的下次重试时间加到 retry 有序队列中,最后抛出异常。关于重试任务的检查跟执行,请阅读前面的相关章节,接下来我们主要分析 sidekiq 如何计算任务的下次重试时间 delay。
让我们展开对 #delay_for 方法的探索:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/middleware/server/retry_jobs.rb#L172-L174
def delay_for(worker, count, exception)
worker.sidekiq_retry_in_block? && retry_in(worker, count, exception) || seconds_to_delay(count)
end
首先了解下 worker.sidekiq_retry_in_block? 的定义:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/worker.rb#L32
base.class_attribute :sidekiq_retry_in_block
其定义了每个 Worker 类的 sidekiq_retry_in_block 属性,而其又可以通过 Worker 类的 #sidekiq_retry_in 方法完成赋值:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/worker.rb#L96-L98
def sidekiq_retry_in(&block)
self.sidekiq_retry_in_block = block
end
回过头来,前面的
worker.sidekiq_retry_in_block? && retry_in(worker, count, exception) || seconds_to_delay(count)
表示当具体的 Worker 配置了 :sidekiq_retry_in_block 时,则直接使用这个配置的 block 执行的值作为失败任务下次重试的时间间隔;否则使用缺省的计算公式:
# https://github.com/mperham/sidekiq/blob/5ebd857e3020d55f5c701037c2d7bedf9a18e897/lib/sidekiq/middleware/server/retry_jobs.rb#L177-L179
def seconds_to_delay(count)
(count ** 4) + 15 + (rand(30)*(count+1))
end
其中 count 为任务累计重试次数,从公式上看,随着失败重试次数的累计增加,任务的下次重试时间间隔也会指数式增长,按照官方文档说法:
Sidekiq will retry failures with an exponential backoff using the formula (retry_count ** 4) + 15 + (rand(30) * (retry_count + 1)) (i.e. 15, 16, 31, 96, 271, ... seconds + a random amount of time). It will perform 25 retries over approximately 21 days.
更多失败任务重试的相关配置请看文档:Error Handling: Configuration。
小结
- sidekiq 在执行任务时,通过自行实现的中间件架构以及对应的简单的中间件,及时捕捉失败的任务,针对允许再次重试的任务,按失败次数计算新的重试时间,缺省为指数增长的时间间隔;
- 用户可以通过配置修改缺省的公式,也可以指定最大重试次数等。
注意:结合失败任务捕捉处理以及重试任务的检查,缺省情况下,一个首次失败任务下次重回队列(不是执行)的理论最大时间间隔大概是 67.5 秒!(固定的 15 秒 + 最大随机时间 30 秒 + 最大理论检查时间 22.5 秒)。所以,如果你的任务很重要,又需要尽快重试,就需要对几部分时间的相关配置参数进行调优了哦!在我自己的工作中,我针对某个队列任务设置的 sidekiq_retry_in 公式为线性时间,即 1s、2s、...50s,然后在重试检查那里设置了 :poll_interval_average 为 5 秒,新的下次执行时间理论最大时间间隔就是 8.5 秒!不过这些配置需要慎重调整,综合考虑业务以及业务量,既要尽可能保证任务尽早处理完,又得保证 Redis 没被 IO 压垮。
总结
关于 sidekiq 项目代码
- sidekiq 的源码比较简洁,很少看到长方法定义,大部分方法都在几行之内,读的过程中非常舒服;
- sidekiq 的注释也很充足,比较重要又比较核心的代码都有大量详细的注释跟例子,除此之外大部分重点在 Wiki 中都有提及,非常好的一份代码库;
- sidekiq 将 Redis 的各种数据结构用得都恰到好处,可以通过 sidekiq 加深对 Redis 的印象以及学习到如何恰当高效地结合 Redis 实现业务逻辑;
- 正是因为 sidekiq 将 Redis 充分利用以及高度结合,我终于理解 sidekiq 的作者为什么表示 sidekiq 不考虑其他数据库了;
- sidekiq 的代码没有太多花俏的代码,非常推荐各位童鞋仔细研读。
关于源码阅读
- 带着问题去阅读,效率通常很高;
- 读的过程中适当放弃无关细节,只追击与问题相关的线索;
- 有些文档中没有提及的配置项,往往都藏匿在代码之中;
- 只有充分了解了工具的运行机制,在遇到问题调优的时候才能得心应手。
最后
如果你能从头看到这里,那么非常感谢你的时间,毕竟这篇文章确实不短,尽管我已经尽量去除无用的部分,一些代码也直接跳过了,但是系统得了解一个框架或者一个软件,确实也是很多细节。
这是今年第二篇博客,今年的产出远不比去年,然而去年的产出远不比千年,所以,可能这篇也是今年最后一篇了。洋洋洒洒两三万字,从下午两三点写到现在,七个多小时,难得可以静下心来写这么多,哎,这两年心态太浮躁,技术路上,还是继续保持“stay foolish, stay hungry”的好。
