运维 Puppet 扩展研究 - 使用 Log.io 作为即时日志输出
绪言
手里有一系列 Puppet Hacking Guide 文集,但这些都只是从“原理剖析”的层面上来解释 Puppet 的内部运行原理,虽然给出了很多有用的扩展建议,但并没有“动真格地”给出一个扩展的实例。这篇文章,就是根据一个真实的需求来扩展 Puppet。但需要说明的是,这个扩展只是为了证成“需求是可以实现的”。之所以这么说,一方面是为糟糕的代码质量开脱,另一方面,是想要强调,本文所描述的并不是最终的解决方案,希望读者不要生搬硬套!
离职前,我在团队内部做了关于《Puppet Hacking Guide - 设计理念及运行原理》的内部技术分享,在会后 Q&A 环节,我的主管提出了这么一个需求,转述如下:
考虑 Puppet 的整个运行流程,当 Agent 端在完成整个部署后,才会向报告服务器发送报告。我们希望 Agent 在部署每一个资源后,能够马上将信息(尤其是错误信息)发送给服务器,以便尽快做出应急处理等。
由于这两个月一直在读 Puppet 源码,所以对它的运行原理还是相当熟悉的,当时想了一下,说感觉不难。然后隔天上午看了悠哉悠哉看了下 Puppet 日志处理的相关源码,吃过午饭后花了半小时把这个需求实现了。比较巧合的是,那天上午逛 GitHub 的时候,偶然看到了 Log.io 这个项目,然后就决定暂时先拿 Log.io 搞。这里将整个思考过程和解决方案记录下来,以供后人将这个需求整合入现有系统时参考。
一图胜千言,上个图:
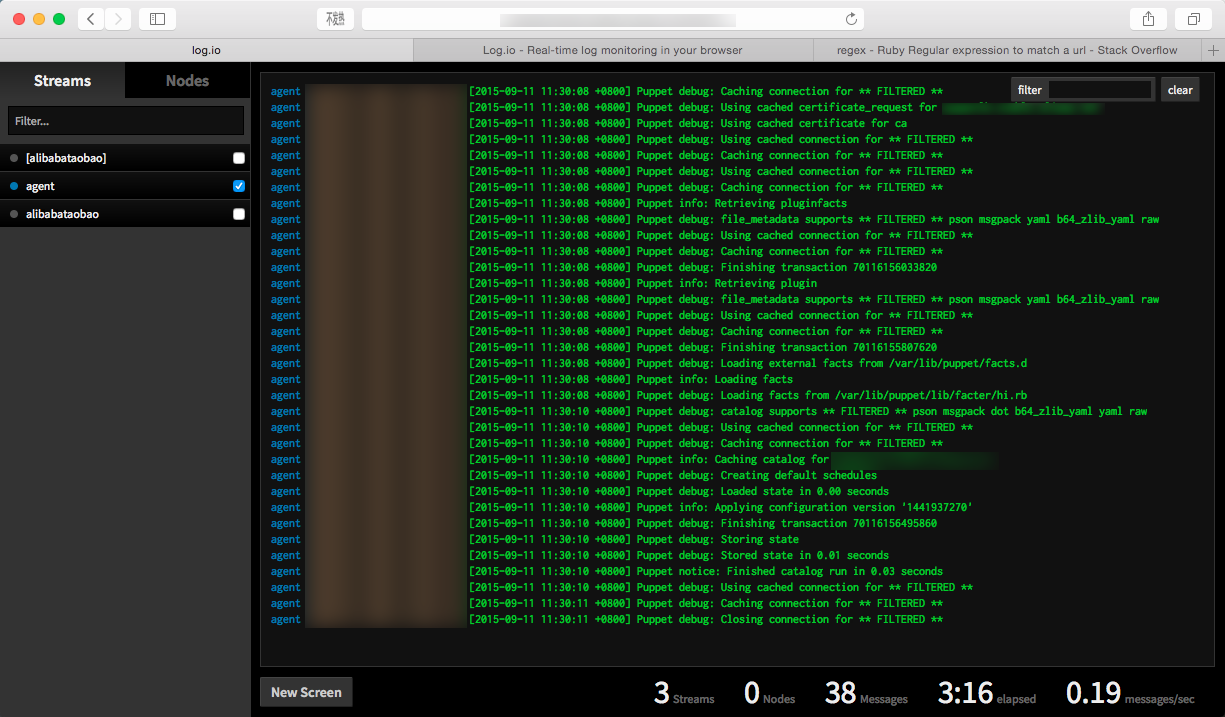
启:突破口
参加过分享会的同学可能对这张 slide 已经没有什么印象了,但是这张幻灯片里面有个关键点,是实现这个需求的突破口:
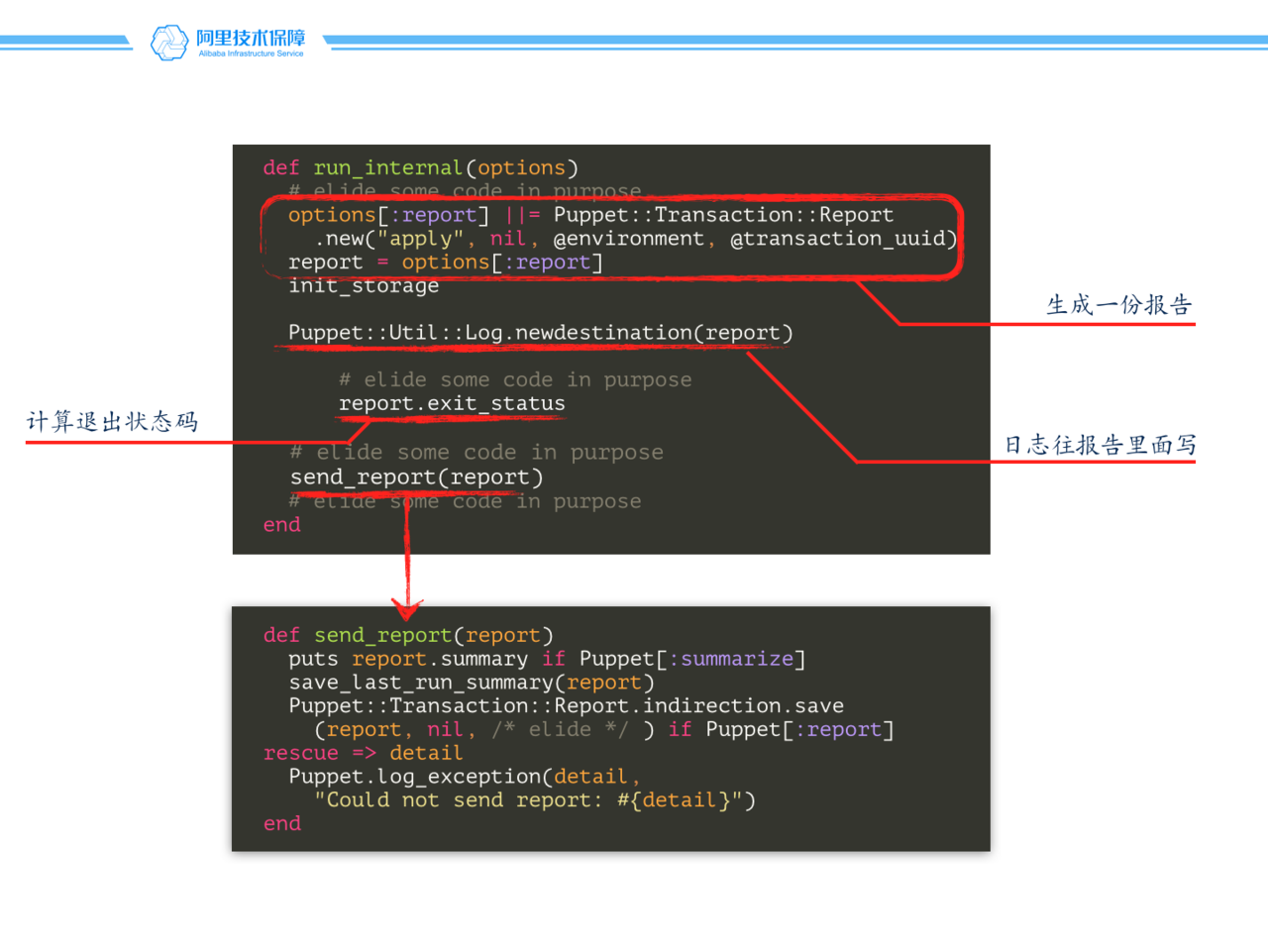
关键点就是 Puppet::Util::Log.newdestination(report) 这句代码,正如我注释里写的那样,这段代码是为日志系统“添加”一个新的目的的,也就是每次日志系统的 IO 输出都会向这个 report 对象输出一份。我们的思路就是:编写一个新的日志目的地,当然,就是往远端服务器写日志!
承:Puppet 日志系统原理
Puppet 日志系统是这样处理新消息的:
def Log.newmessage(msg)
return if @levels.index(msg.level) < @loglevel
queuemessage(msg) if @destinations.length == 0
@destinations.each do |name, dest|
dest.handle(msg)
end
end
具体来说:
- 如果日志的等级小于当前等级,那么我们直接忽视它(比如调试信息
debug级的日志,不应该出现在产品级环境中); - 如果当前没有日志输出目的地的话,我们就将日志缓存在一个队列里面;
- 调用日志目的地的
handle方法,来处理日志;
这段代码给我提供了两个关键信息:
- 同样一条日志,可能会写往多个目的地;
- 重要的是
handle方法,我们编写的目的地需要响应handle这个方法;
实际上,打开文件 lib/puppet/util/log/destinations.rb ,我们可以发现 Puppet 自己定义的几个目的地,下面举几个比较有意思的例子;
# Log to a transaction report.
Puppet::Util::Log.newdesttype :report do
attr_reader :report
match "Puppet::Transaction::Report"
def initialize(report)
@report = report
end
def handle(msg)
@report << msg
end
end
Puppet::Util::Log.newdesttype :file do
require 'fileutils'
# 有意省略了部分代码
def handle(msg)
@file.puts("#{msg.time} #{msg.source} (#{msg.level}): #{msg}")
@file.flush if @autoflush
end
end
Puppet::Util::Log.newdesttype :array do
match "Puppet::Test::LogCollector"
def initialize(messages)
@messages = messages
end
def handle(msg)
@messages << msg
end
end
file 是文件读写,report 是往一个 Report 对象里面写,array 就更有意思啦,可以往一个数组里面写,也就是把日志暂存在内存里面。不过我们再次看到,关键的关键是 handle 方法,我们实现 handle 方法就好。
到了这里,我们不得不提一下实现这个需求的另一个工具:Log.io,这是一个基于 Node.js 和 socket.io 的“实时日志监控系统”。
Log.io 的部署和使用都很简单,如果要发送一条日志,那么先通过 TCP 套接字连接上服务器,然后按照下面的格式发送消息:
+log|my_stream|my_node|info|this is log message\r\n
所以我们的 handle 方法将日志信息按格式写入这样的一个 TCP 连接即可,我实现的代码大致入戏下:
Puppet::Util::Log.newdesttype :logio do
require 'socket'
def send_message(msgstr)
@connection.write "#{msgstr}#{ENDLINE}"
end
def send_log(msg)
send_message build_log(msg)
end
def build_log(msg)
time = get_log_time(msg)
message = filter_message(msg)
"+log|#@stream|#@node|#{msg.level}|[#{time}] #{msg.source} #{msg.level}: #{message}"
end
def handle(msg)
send_log msg
end
def get_log_time(msg)
msg.time.strftime(self.class.time_format)
end
# Maybe you wanto filter some message such as password stuff?
# This method should have type Puppet::Util::Log -> String
def filter_message(msg)
msgstr = msg.to_s
# all another filter methd should have type String -> String
escape_message(msgstr)
end
def escape_message(msgstr)
msgstr.gsub(ENDLINE, NEWLINE)
end
def send_close
send_message(build_close_message)
end
def build_close_message
"-node|#@node"
end
def close
send_close
close_connection
end
def close_connection
if @connection
@connection.close
@connection = nil
end
end
end
函数拆分得有点散,主要是为了实现复用和扩展,这里说一下我的考虑:
- 由于 Log.io 支持几种不同的消息(比如,发送日志、流的注册、节点退订等),所以在我的实现里,最基本的语义是“发送一条 Log.io 消息”,Log.io 消息被定义为“一条字符串 + 结束符\r\n”,发送消息由
send_message方法实现; - 发送日志,则交由
build_log方法构建一条格式化的日志,考虑到可能想要过滤一些敏感信息,因此定义了一个filter_message方法,来实现敏感信息的过滤。现在这个方法中只是调用了escape_message方法,将日志中出现的\r\n替换为\n,避免系统错误地将一条日志分为多条(我感觉这个设定是没有必要的……),后期可以根据需要添加过滤方法,过滤在日志系统中出现的敏感信息(文章开头的那个图,我就是定义了一个filter_domain方法,将所有的域名信息都替换为** FILTERED **); - 可以通过覆盖
get_log_time方法来自定义日志时间的格式化,不过这个的变动似乎不大; - 最后是关闭 TCP 连接,在实际关闭之前,调用
send_close方法,向服务器发送一个节点退订的消息(似乎发不发影响都不大?);
下面说下初始化的问题。
我们定义每个日志输出目的地时,使用的是 Puppet::Util::Log.newdesttype 方法,这个方法用到了 Ruby 元编程的技巧,用来动态地创建一个类;
def self.newdesttype(name, options = {}, &block)
dest = genclass(
name,
:parent => Puppet::Util::Log::Destination,
:prefix => "Dest",
:block => block,
:hash => @desttypes,
:attributes => options
)
dest.match(dest.name)
dest
end
# Create a new log destination.
def Log.newdestination(dest)
# 有意省略了部分代码
begin
if type.instance_method(:initialize).arity == 1
@destinations[dest] = type.new(dest)
else
@destinations[dest] = type.new
end
# 有意省略了部分代码
end
end
注意到 if type.instance_method(:initialize).arity == 1 这句代码,会检查我们自定义目的地类的 initialize 方法的参数数目,initialize 方法要么是单参的,要么是无参的。单参的时候,传递过来的是一个对象,也就是我们通过 newdesttype 只是一个中介,最终的目的地是输出化时传递给 initialize 方法的那个对象。要理解这个设定比较复杂,我们就值考虑 initialize 方法是无参时候的情况,这时候,我们定义的 newdesttype 就应该是实际的目的地了。
我的实现中是这样实现的
Puppet::Util::Log.newdesttype :logio do
attr_accessor :stream, :node
DEFAULT_SERVER = "logio".freeze
DEFAULT_PORT = 28777
DEFAULT_STREAM = "agent".freeze
@time_format = "%Y-%m-%d %H:%M:%S %z".freeze
class << self
attr_reader :time_format
def time_format=(str)
@time_format = str.dup.freeze
end
end
def initialize
Puppet.settings.use :agent
setup_log Puppet[:logio_stream], Puppet[:logio_node]
setup_connection
end
def setup_connection
server = Puppet[:logio_server] || DEFAULT_SERVER
port = Puppet[:logio_port] || DEFAULT_PORT
@connection = TCPSocket.new(server, port)
end
def setup_log(stream, node)
@stream = stream || DEFAULT_STREAM
@node = node || Puppet[:certname]
end
end
稍微解释一下我的考虑:
- 由于 Log.io 发送日志消息的时候有几个必要的要素:节点名、Stream 名、日志信息,而为了发这么一条日志,我们还需要知道 Log.io 的主机名、端口号等信息,现在我们没办法从参数中取得这样的信息,那么我们只能求助于
puppet.conf文件(这样做带来的结果就是给用户有带来了更大的灵活性) - 默认的 Log.io 主机名为
logio,这样也可以通过改 Hosts 文件来实现 Log.io 主机的定位 - 提供了一个
setup_log方法,这样程序员还有机会设置发送日志的节点名和订阅的 Stream 名
为了在 puppet.conf 文件中启用这些配置项,我们还需要在 defaults.rb 文件中加入下面的代码,这些代码是自注释的(你一看就知道大概是啥意思了):
module Puppet
define_settings(:agent,
:logio => {
:default => false,
:type => :boolean,
:desc => 'Whether to use Log.io to record live log for each resource.'
}
)
define_settings(:agent,
:logio_server => {
:default => "logio",
:type => :string,
:desc => 'The domain or hostname or the ip address of Log.io server.'
}
)
define_settings(:agent,
:logio_port => {
:default => 28777,
:desc => 'The port of Log.io server.'
}
)
define_settings(:agent,
:logio_node => {
:default => "$certname",
:type => :string,
:desc => "The node name which used to identify the host on Log.io"
}
)
define_settings(:agent,
:logio_stream => {
:default => "agent",
:type => :array,
:desc => "On which stream this host push to, may be a single stream or a group of streams
split by ',' symbol."
}
)
end
转:怎么使用呢?
这个需要根据具体需求具体判断。因为我们只关心资源应用阶段的日志,所以我把它放到了 lib/puppet/configurer.rb 文件里面的 run_interal 方法中,读者可以看到有一行形如 Puppet::Util::Log.newdestination(report) 地代码,而我们只加了一行 Puppet::Util::Log.newdestination(:logio) 。如果你关心的是整个启动过程,那么你可以把这行代码加在尽可能早的地方。
class Puppet::Configurer
# 有意省略了部分代码
def run_internal(options)
# We create the report pre-populated with default settings for
# environment and transaction_uuid very early, this is to ensure
# they are sent regardless of any catalog compilation failures or
# exceptions.
options[:report] ||= Puppet::Transaction::Report.new("apply", nil, @environment, @transaction_uuid)
report = options[:report]
init_storage
Puppet::Util::Log.newdestination(report)
Puppet::Util::Log.newdestination(:logio) # <-- 使用我们定义的日志目的地
为什么我要把这节放到“转”呢?实际上,我并不满意这个扩展。在之前我通过编写 gem 来扩展 Puppet,我甚至没有修改一行 Puppet 源码!然而这次的扩展,我们不得不修改 run_internal 的源码,添加一行代码。这让我感觉很不爽。
Puppet 有一个 Plugin Hook 机制,它会尝试搜索一个 plugin_init.rb 的文件,加载并在适当的实际,调用其中的钩子方法(碍于时间关系,这里就不深入讨论了,有兴趣的同学可以读下 lib/puppet/application.rb 文件中 plugin_hook 方法的源码)。我们似乎可以可以通过在在这个文件中加点 Trick,以实现在不修改 Puppet 源码的基础上,实现我们的功能。但是 Puppet 搜索这个文件的机制有点操蛋,它只搜索 $LOAD_PATH ,并不会搜索所有安装的 gems 的路径还有编写的 Puppet 模块的路径,导致我们的这个想法也随之告吹。
所以,如果哪位对 Puppet 有更深入研究的同学知道如何更绿色地扩展这个需求,一定要让我知道!!!
总结
碍于时间关系,这篇文章并没有条理清晰地讲解我们整个思考过程,也没有像之前系列文章那样,仔细地考察 Puppet 的底层原理,但它描绘了一个骨架,一种可行性。有智慧的人总能找到他所需要的东西!
对于 Puppet 日志系统,似乎有很多可以改进的地方,比如可以将日志记录派发到一个后台队列,异步地执行(尤其是涉及到网络操作的日志系统),这样对于有多个日志目的地的系统,性能提升还是很明显的。
我们这个简单的解决方案还有很多要改进的地方,比如:
- Puppet 本身有个 HTTP 连接缓存池,不过它是构建在应用层的,我们这里用到的是 TCP 连接,处在更加底层的传输层。我们可以模仿 Puppet HTTP 连接缓存池的实现,自己实现一个 TCP 连接的缓存池;
- 错误处理。目前我们的实现没有考虑网络通信的错误处理,不是很健壮。
目前相关项目已通过公司开源项目开源流程和对外披露流程,具体代码可以在以下 Repo 找到: