运维 Puppet Hacking Guide —— Puppet 的启动:守护进程
Acknowledgment
本系列文集是在我受雇于阿里巴巴期间撰写的一系列技术文档重新整理而成,其版权属于阿里巴巴公司以及我本人。经雇主同意,现特许以技术交流为目的,在开源技术社区分享此文集。
因此您可以:在保留原作者 DeathKing 以及阿里巴巴 - 技术保障部署名的情况下,以学习交流为目的,以非盈的形式将本文以电子版或印刷版的形式分发给您的朋友,或者转载到任何一个开源社区;
以下行为是禁止的:
- 以盈利为目的,将文章转载到微信公众号等媒体平台;
- 去掉原作者 DeathKing 以及阿里巴巴 - 技术保障部的署名,以自己的名义发布本文集;
请在转载时,保留以下署名:
- 本系列文章作者 DeathKing
- 阿里巴巴技术保障部

在默认的工作流中,Puppet Agent 会以守护进程的方式运行,每 30 分钟与 Puppet Master 同步一次。为了方面交互式测试,可以在调用 Puppet 时使用 --no-daemonize 选项,这样 Puppet 则会阻止程序的后台化,日志信息会全部输出在终端中。
我们自然而然地会产生如下的疑问:
- Puppet 是如何实现进程的后台化的?
- 调度又是体现在何处?
本文就将解答以上问题。理解后台进程的原理,将有助于我们认识 Puppet Agent 和 Master 的工作原理。
Daemon: 可后台化进程
为了避免长时间占据系统前台,周期性的任务或者网络服务器都应该实现为守护进程,放入系统后台执行。Puppet 提供的 Puppet::Daemon 类实现了可后台化(daemonized)进程。我们把这些在后台执行的、并不直接被用户操控的进程称为守护进程(Daemon Process)。我们将 Daemon 类实现的进程称为是“可后台化的”,是因为程序员可以根据需要选择是否将这个进程放入后台执行,而并非强制将进程放入后台执行。
一个守护进程必须有:
- 一个配置重解析器(Reparser),它需要能够重新解析配置文件并应用到系统,以应对配置文件或清单文件的修改;
- (要么有)能够响应
run方法的代理(Agent); - (要么有)能够响应
stop、start和wait_for_shutdown方法的服务器(Server);
需要强调的是,必须至少为守护进程配置一个代理或服务器,否则 Puppet 会抛出 Puppet::DevError 异常。同时,这里的代理指的是可以被守护进程调用并自主执行的对象(可以将此处的 Agent 非正式地理解为实际的业务代码),而并非 Puppet Agent——后者是一个 Puppet 子命令程序,请读者仔细甄别两者。
代理和配置重解析器都可以按照配置文件中的设定,周期性地运行(Puppet[:filetimeout])。考虑到在代码的执行过程中,配置文件会发生改变。因此配置解析器会在每次运行时重新解析配置文件,以更新其自身和代理的运行周期。
守护进程会调用 server.start 来启动服务器,但服务器应该自己管理运行循环(run loop),以避免阻塞守护进程的运行。同时,服务器需要有一个 wait_for_shutdown 方法来等待线程的结束。
Daemon 的层次观
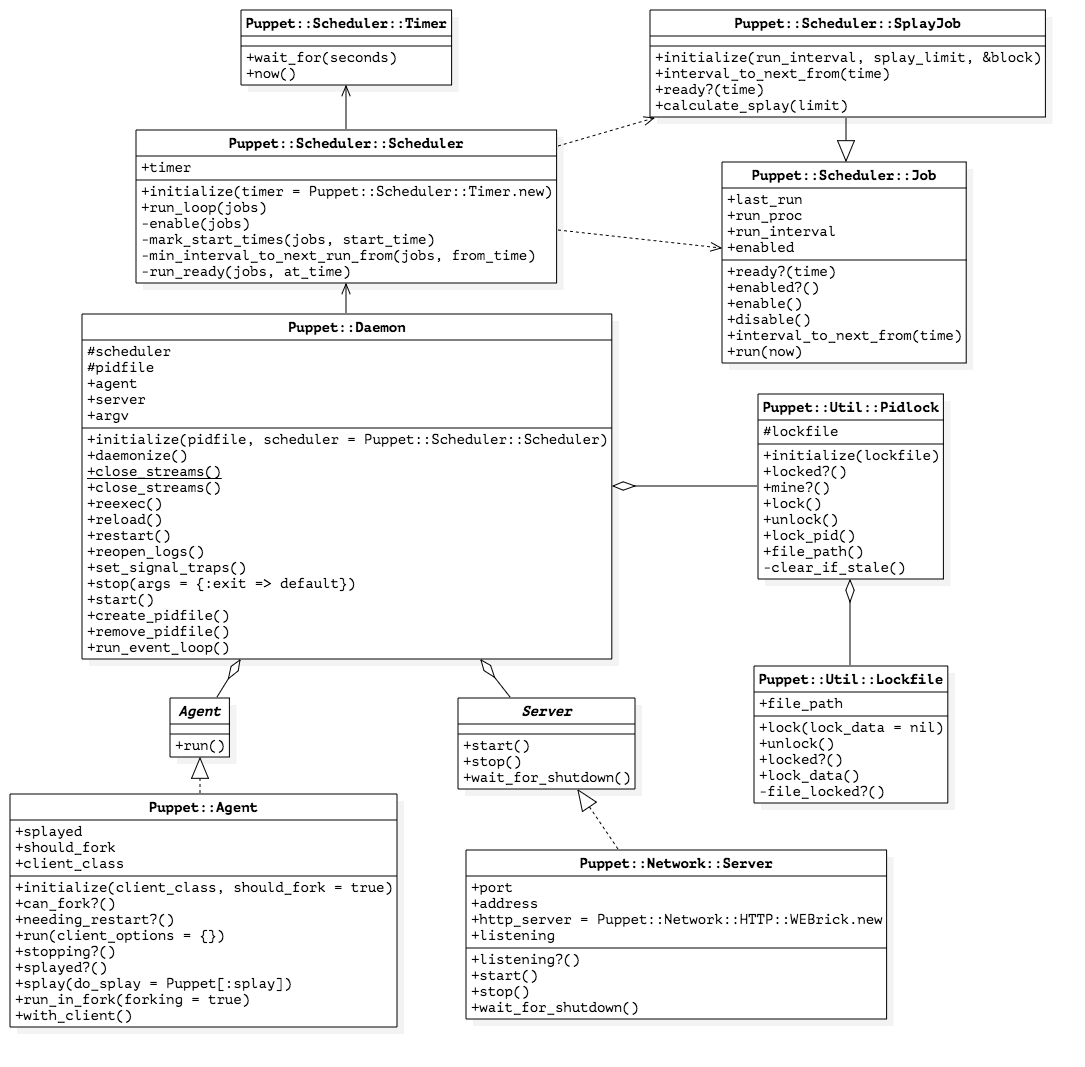
Daemon 的实现用了许多基本组件,Puppet 按照一定的层次组织了这些组件:
- Puppet 子命令应用程序可能会拥有一个守护进程,而守护进程的代码实体可能是一个代理或网络服务器(或者两者都有);
- 守护进程用
Pidlock来管理 PID 文件,Pidlock更底层的实现是Lockfile类; - 守护进程还有一个调度器(Scheduler),该调度器以作业(Job)为基本单位,调度程序运行;
- 调度器有个计时器(Timer),调度器根据计时器的时间戳来检查作业的调度;
- 每个作业负责启动代理或配置重解析器的执行;
请注意第 1 点,对于 Puppet Agent 来说,它可能会为守护进程设置一个 agent ,该代理执行的是实际与 Puppet 通信的业务代码;而对于 Puppet Master 来说,它可能会给一个守护进程设置一个 server ,以提供 HTTP API 服务,使得 Puppet Agent 能够与之通信。对于这两种分别单独设置 agent 或 server 的情况,似乎都很容易理解,那么有没有同时设置 agent 和 server 的情况呢?
答案是肯定的。Puppet 3.X 版本中提供了一个 puppet kick 命令,允许用户远程触发 Puppet Agent 的同步。其具体实现就是,在为 Puppet Agent 的后台进程设置 agent 的同时也设置 server ,从而实现对远程命令的监听。但是这个功能在 Puppet 4.X 以后就被取消了。
下图是一个非正式地 UML 图,它描绘了 Daemon 各组件之间的层次观:
注意
希望 Java 背景的读者注意到这样一个事实:Ruby 中并没有接口(Interface)这一说法,取而代之的是所谓的“鸭子类型”,或者说“面向协议”编程。在本例中,
Daemon类对于代理和服务器有特定的要求,如果按照 Java 程序员的观点,可以理解为我们有Agent和Server两个抽象类,前者包含抽象方法run(),而后者包含抽象方法start()、stop()、wait_for_shutdown(),Puppet 要求传递给Daemon的代理或服务器需要分别实现这两个接口。
虽然我们的 UML 图是按照 Java 的观点来绘制的,但是 Ruby 并不要求有什么继承或实现关系,只要对象具有特定的方法即可。
Daemon 的数据结构及初始化
| 实例变量 | 类 | 初始值 | 说明 |
|---|---|---|---|
| @scheduler | Puppet::Scheduler::Scheduler | Puppet::Scheduler::Scheduler.new | 任务调度器。 |
| @pidfile | Puppet::Util::Pidlock | 由参数传递 | PID 文件。 |
| @agent | {#run} | nil | 代理。 |
| @server | {#stop, #start, #wait_for_shutdown} | nil | 网络服务器。 |
| @argv | Array | nil | 命令行参数。 |
需要注意的是,Daemon 的初始化只完成了对 @pidfile 和 @scheduler 的设置,@agent 、@server 和 @argv 的设置由相应的 setter 方法完成。
daemonize:进程后台化
- 文件:
lib/puppet/daemon.rb
def daemonize
if pid = fork
Process.detach(pid)
exit(0)
end
create_pidfile
# Get rid of console logging
Puppet::Util::Log.close(:console)
Process.setsid
Dir.chdir("/")
close_streams
end
Puppet 通过 fork、detach 方法的组合来实现进程的后台化。
fork 方法为当前进程创建一个子进程,子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。如果不是以传递代码块的方式调用 fork 方法,那么 fork 会返回两次,在父进程中,fork 方法返回子进程的进程 ID 号,而在子进程中,fork 返回 nil 。
当子进程退出以后,某些操作系统仍然会为其维护一个包含了其退出码的数据结构,如果父进程不通过 wait() 及其变种系统调用来收集这些退出状态的话,操作系统中将产生大量的僵尸进程(Zombie Process)。当我们不想显式地等待子进程结束时,可以使用 Process::detach 方法创建一个单独的 Ruby 线程,用来收集子进程的退出码。
父进程调用 exit(0) 结束自己的生命周期,因此 if..end 语句之后的代码,都是由后台进程——也就是我们创建的子进程来执行的。create_pidfile 方法用于为我们的守护进程创建 PID 文件并加锁,主要作用是保证在系统中只存在该守护进程的一个实例,同时也便于系统统一管理这些守护进程。
后续的代码分别完成:
- 不让日志输出到终端;
- 将进程设置为新的会话的领头进程,并与其父进程的会话组和进程组脱离;
- 将路径切换至根目录;
- 关闭
stdin、stdout和stderr以完成进程的后台化;
start:守护进程的运转
start 方法用于启动整个守护进程的实际运转,该方法首先调用 set_signal_traps 设定进程的信号处理,然后调用 create_pidfile 方法创建 PID 文件。需要注意的是,用户可能会使用 --no-daemonize 方法要求 Puppet 不要以守护进程的方式执行,因此虽然 daemonize 方法定义了 PID 文件的创建与加锁,但它很可能没被调用,所以我们也要在 start 方法里面再次调用 create_pidfile 方法,这样可以确保进程的 PID 文件被创建且正确加锁。
- 文件:
lib/puppet/daemon.rb
def start
set_signal_traps
create_pidfile
raise Puppet::DevError, "Daemons must have an agent, server, or both" unless agent or server
# Start the listening server, if required.
server.start if server
# Finally, loop forever running events - or, at least, until we exit.
run_event_loop
server.wait_for_shutdown if server
end
如果没有为守护进程配置代理或服务器,那么 Puppet 抛出一个异常。Puppet 要求服务器的运行循环不能阻塞守护进程的运行,所以调用 server.start 后,Puppet 进入守护进程的运行循环(run_event_loop),该循环会一直占据主线程,直到执行完毕主动退出。最后,server.wait_for_shutdown 会等待服务器的结束。
run_event_loop:主运行循环
- 文件:
lib/puppet/daemon.rb
def run_event_loop
agent_run = Puppet::Scheduler.create_job(Puppet[:runinterval], Puppet[:splay], Puppet[:splaylimit]) do
# Splay for the daemon is handled in the scheduler
agent.run(:splay => false)
end
reparse_run = Puppet::Scheduler.create_job(Puppet[:filetimeout]) do
Puppet.settings.reparse_config_files
agent_run.run_interval = Puppet[:runinterval]
if Puppet[:filetimeout] == 0
reparse_run.disable
else
reparse_run.run_interval = Puppet[:filetimeout]
end
end
reparse_run.disable if Puppet[:filetimeout] == 0
agent_run.disable unless agent
@scheduler.run_loop([reparse_run, agent_run])
end
守护进程的主运行循环通常会创建两个作业(Job),并周期性地调用它们:
-
agent_run:负责调用代理的run方法; -
reparse_run:负责重新解析配置文件,并更新agent_run和reparse_run的运行周期;
这两个作业交由调度器 @scheduler 调度,@scheduler.run_loop 会不断调度传递过来的作业,直到所有作业都变成无效为止。
这里需要提及一下 SplayJob ,如果在配置文件中启动了 splay 选项,那么 Puppet 在创建调度作业时,会则会 SplayJob 作业。SplayJob 作业在到达指定启动时间后,会随机延迟一定时间再启动,这是为了避免成千上万台 Puppet Agent 同时启动所带来的惊群效应——如此高的并发量,将对 Puppet Master 构成相当严峻的挑战!
stop:守护进程的终止
- 文件:
lib/puppet/daemon.rb
def stop(args = {:exit => true})
Puppet::Application.stop!
server.stop if server
remove_pidfile
Puppet::Util::Log.close_all
exit if args[:exit]
end
守护进程的终止比较容易理解,主要是:
-
Puppet::Application.stop!:给当前运行的应用发送停止请求; -
server.stop if server:如果启动了服务器,那么就将其停止; -
remove_pidfile:解锁并移除进程的 PID 文件; -
Puppet::Util::Log.close_all:关闭所有的日志; -
exit if args[:exit]:如果没有特别指明,那么退出进程;
需要说明的是,如果守护进程并不是放在后台执行的,此时守护进程由主线程执行。那么要在调用 stop 时,需要置 exit 一项为 true,避免退出整个 Ruby 解释器;
set_signal_traps:设置信号处理
- 文件:
lib/puppet/daemon.rb
def set_signal_traps
signals = {:INT => :stop, :TERM => :stop }
# extended signals not supported under windows
signals.update({:HUP => :restart, :USR1 => :reload, :USR2 => :reopen_logs }) unless Puppet.features.microsoft_windows?
signals.each do |signal, method|
Signal.trap(signal) do
Puppet.notice "Caught #{signal}; calling #{method}"
send(method)
end
end
end
set_signal_traps 方法调用 Signal.trap 方法为一些主要的信号添加处理程序。Microsoft Windows 系统并不支持 HUP、USR1 和 USR2 信号,所以对于 Windows 系统,不要处理处理信号。