require 'rubygems'
require 'nokogiri'
require 'open-uri'
uri = "http://www.hao123.com/"
doc = Nokogiri::HTML(open(uri),nil.'utf8')
#html=open('hao123.html').read
#doc= Nokogiri::HTML(html,nil,'utf8');
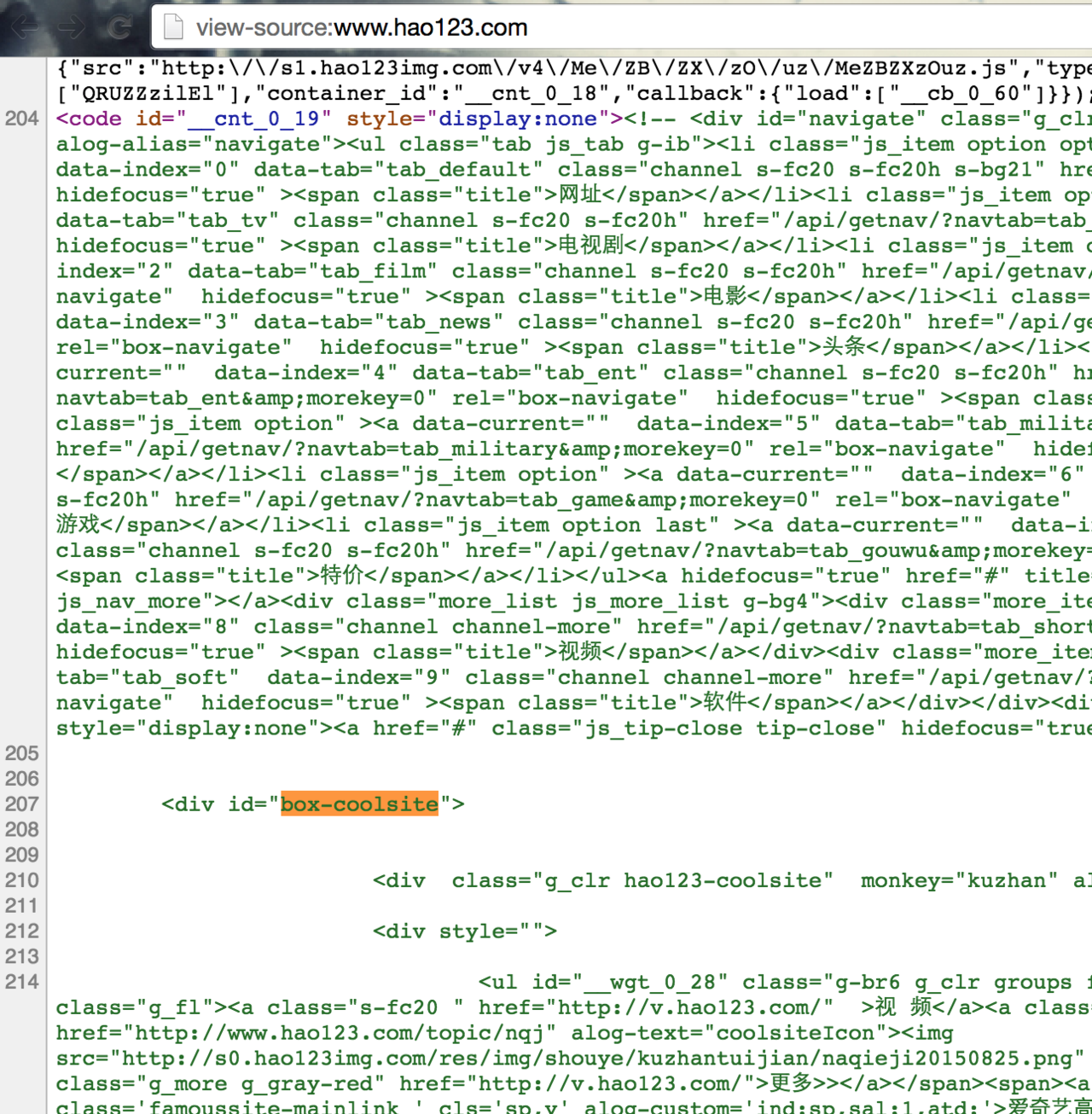
sites=doc.at("#box-coolsite")
puts sites
要取得 主体部分的站点列表,但是取不出来,用 hpricot 也是一样