Ruby Ruby 2.2 中的增量式垃圾回收
Ruby2.2 中的增量式垃圾回收
本文是 http://engineering.heroku.com/blogs/2015-02-04-incremental-gc?utm_source=rubyweekly&utm_medium=email 的翻译。鄙人是 Ruby 新手,英语渣,如果翻译有不妥之处还请轻喷。。。。别把我打死了
本文介绍了 被引入 Ruby2.2 中的增量式 GC。我们将这个算法称为 RincGC。与 Ruby2.1 相比 RincGC 缩短了 GC 的停顿时间。 关于作者:Koichi Sasada 和 Nobu,Matz 一起为 Heroku 工作 同时也是 C Ruby 核心成员。先前,他编写了 Ruby 的虚拟机(YARV)。 他为 Ruby2.1 引入了 分代垃圾回收。Koichi Sasada 为 Ruby2.2 实现了增量式 GC 并撰写了此文。
背景
Ruby 使用 GC 来自动回收未被使用的对象。归功于 GC,Ruby 程序员不需要手动释放对象,也无需担忧对象释放的 bug。 初版的 RubyGC 使用了标记 - 清除算法。标记 - 清除算法是最简单的垃圾回收算法之一,它包含了两部分:
- 标记:遍历所有的活动的对象并标记为“活动对象”。
- 清除:未被标记的作为未使用的对象被回收。
标记 - 清除算法是基于被遍历的对象都是活动的对象的前提。标记 - 清除算法简单有效。
这个简单有效保守的垃圾回收技术使 C 扩展的编写变得容易。Ruby 因此获得了很多有用的扩展类库。然而,也由于标记 - 清除算法,使 Ruby 采用其他 GC 算法如复制收集变得困难。 现在由于采用了 FFI 技术 (foreign function interface),编写 C 扩展类库已经变得不那么重要了。当初 Ruby 由于享有拥有许多扩展类库并提供了许多基于 C 扩展的特性而获得了巨大的优势。并使 Ruby 解释器变得更为的流行。 虽然标记 - 清除算法能很好地工作,但同时它也有几个问题。最重要的两个问题是“吞吐量”(throughput) 和“停顿时间”(pause time)。过高的 GC 开销会减慢你的程序运行速度。换言之,较低的吞吐量增加了你的应用运行时间。 每次 GC 执行时,会暂停你的 Ruby 应用。长时间的停顿会影响用户体验。(UI/UX?)
Ruby2.1 引入了分代垃圾回收来解决“吞吐量”问题。分代 GC 将堆分成了多个空间对应于不同的世代(就 Ruby 而言,我们将堆分成了“新生代”和“老年代”两代。)新生成的对象会被标记为“新生代对象”并放入“新生代空间”。 在存活过几次 GC 之后(Ruby2.2 中 3 次),“新生代对象”会变成“老年代对象”并被移入“老年代空间”。在 OOP 中,我们知道大部分对象英年早逝(哈哈,恶搞一下)。有鉴于此,我们只需要对“新生代空间”进行 GC 操作。 如果“新生代空间”没有剩余空间了,我们就会对“老年代空间”做 GC 操作。针对“新生代代”的 GC 操作,称之为“小 GC”(minor GC)。同时对“新生代”和“老年代”做 GC 操作的称之为“主 GC”(major GC)。 我们实现了做个定制的分代 GC 算法,称之为"RGenGC"。更多关于"RGenGC"的信息,参见 RGenGC at my talk at EuRuKo and slides。
因为小 GC 非常快速,所以 RGenGC 改进了 GC 的动态吞吐量。然而主 GC 会长时间的停顿,其停顿长度与 Ruby2.0 及其更早的版本的 GC 停顿时间相当。大部分的 GC 都是小 GC, 少数几个 Major GC 可能造成你的应用长时间停顿。
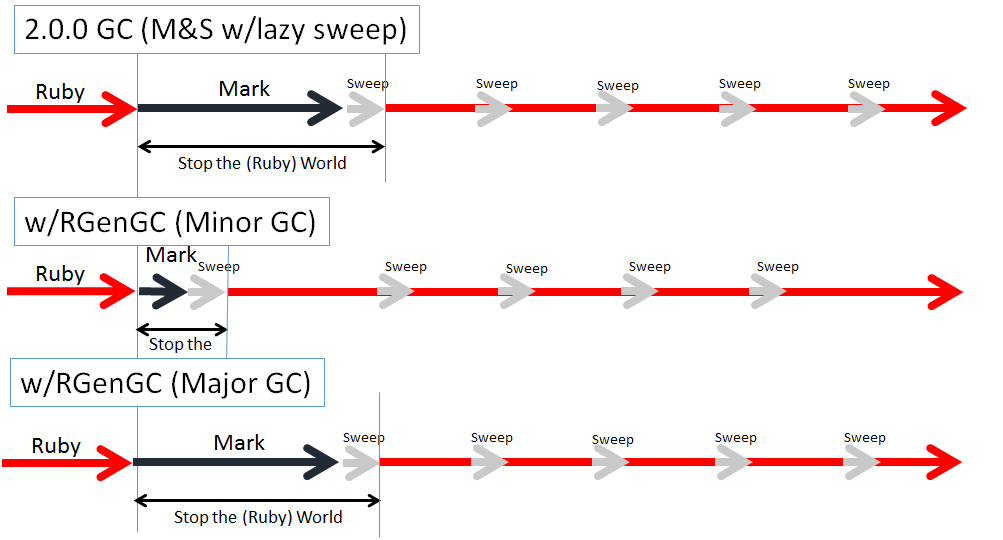
为了解决长时间的停顿,增量式 GC 算法是个知名的解决方案。
增量式 GC 的基本概念
增量式 GC 算法将 GC 处理过程分解成细颗粒度的处理过程并插入到 Ruby 的进程处理过程中。增量式 GC 会在一个周期内用多个短时间停顿以代替一个长时间的停顿。总的停顿时间相同 (或略长 因使用增量式 GC 引起的较高的 GC 开销。),但是每个 GC 造成的停顿都很短。这使得总体的性能更稳定。
Ruby 1.9.3 中引入的一个“惰性清除”GC,它降低了清除阶段的停顿时间。惰性清除的要点在于不是一次而是多次执行清除。惰性清除降低了单个清除过程造成的停顿时间。算是半个增量式 GC 算法。 现在,我们要使主 GC 的标记阶段增量化。
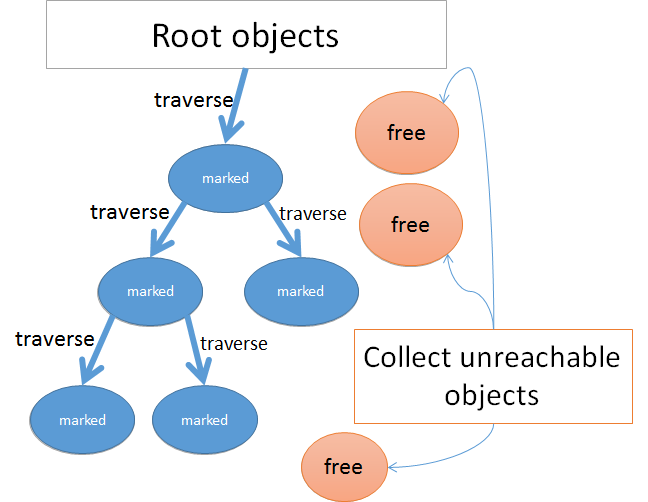
让我们介绍三个术语以解释增量标记:“白对象”即没有被标记的对象。“灰对象”被标记了但可能有指向“白对象”,“黑对象”被标记且没有指向任何“白对象”。 通过这三种颜色,我们可以像这样解释标记与清除算法:
- 所有存在的对象会被标记为白色
- 诸如堆栈上的有着明确引用对象会被标记为灰色
- 选取一个灰色对象,遍历每一个它指向的对象并标记为灰色,最后将源头的对象标记为黑色。重复上述步骤,直至只剩下黑色与白色对象。
- 回收白色对象,因为被使用的对象都是黑色的。 为了使上述过程 增量化,我们必须将第三步增量化。我们需要做到,选取一些灰色对象遍历标记然后返回执行 Ruby 代码,然后再继续增量标记阶段,如此往复。
要做到增量标记就有一个问题:黑色对象可能在 Ruby 执行的过程中指向了白色对象。这个问题是由于黑色对象是定义表明它不会指向白色对象。为了防止此类问题,我们需要使用“内存屏障”(write-barrier) 来侦测“黑对象”向“白对象”创建了引用。 例如 一个数组对象 ary 已经被标记为黑色
ary = []
# GC runs, it is marked black
如果我们运行了代码,会有一个对象 obj = Object.new 标记为白色
ary << obj
# GC has not run since obj got created
现在一个黑色对象 有了一个指向白色对象的引用。如果没有灰色对象指向 obj,那在标记阶段结束的时候,obj 会被标记为白色并被错误的回收了。回收正在使用的对象是一个致命的 bug,我们需要避免的大错。 内存屏障在每一次一个对象获取另一个新对象的引用时会被调用。当一个引用从黑色对象指向白色对象时,内存屏障会探测到。内存屏障会将黑色对象标记为灰色对象(灰变白)。内存屏障完整的解决了这类灾难性的 GC BUG。 以上是关于增量式 GC 算法的基本概念。如你所见,不是太难。也许你会想问“为什么 Ruby 还不使用呢?”
Ruby 2.2 的增量式 GC
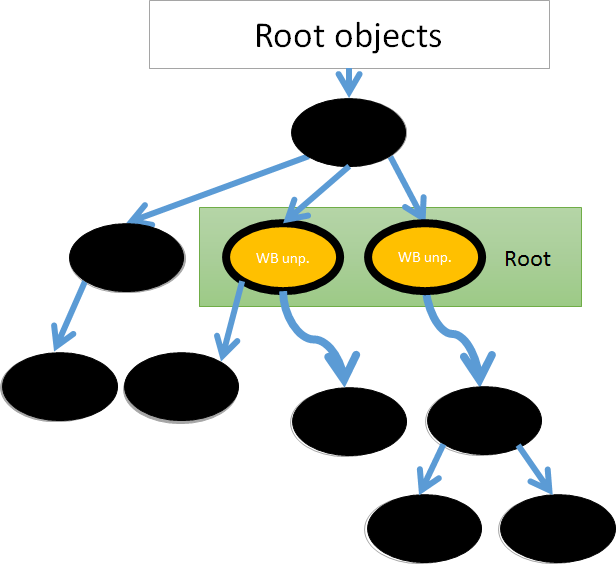
要在 Ruby 解释器 (CRuby) 中实现增量式标记有一个大问题:缺少内存屏障。CRuby 没有足够的内存屏障。 在 Ruby2.1 中实现的分代垃圾回收同样也需要内存屏障。为了引入分代垃圾回收,我们发明了一种叫做“write barrier unprotected objects“的新技术。这意味着我们将所有的对象分为 "write barrier protected objects" (protected objects) and "write barrier unprotected objects" (unprotected objects)。我们保证所有来自被保护对象的引用是可控的。我们无法保证 来自未受保护的对象的引用也可控。通过引入”未保护对象“,使我们能够实现 Ruby2.1 的分代垃圾回收。 通过使用未受保护对象,我们也能够使用增量式 GC。
- 将所有存在的对象标记为白色。
- 将所有有着明确引用的活动对象标记为灰色(包括堆栈上的对象)。
- 选取一个灰色对象,遍历每个它所引用的对象并标记为灰色,将源头的对象标记为黑色。重复上述步骤,直至只剩下黑色与白色对象。这步骤是增量式完成的。
- 黑色未受保护对象可以指向白色对象,并立即扫描所有来自未被保护的黑色对象。
- 回收白色对象 因为正在被使用的对象都被标记为黑色。 通过引入第四步骤,我们能够保证没有正在使用的白色对象。

不幸的是,第四步可能会引入我们希望避免的长时间停顿。然而,这个停顿时间与正在使用的内存屏障的未受保护对象的数量有关。在 Ruby 语言中,大部分的对象都是 String ,Array,Hash 或是 由用户定义的纯 Ruby 对象。他们都是使用的内存屏障的受保护对象。所以使用的内存屏障的未受保护对象所引起的长时间停顿,并不会在实际使用中引起问题。
因为没人抱怨 minor GC 的暂停时间,所以我们只为 Major GC 引入增量式标记。增量式 GC 上的最长的停顿时间也比 minor GC 的停顿时间短。如果你对 minor GC 的停顿时间没意见,那你更不需要担心 major GC 的停顿时间了
我在实现增量式 GC 的过程中也耍了一个小花招。我们获取了一系列“黑色且未受保护的”对象。为了实现快速的 GC,我们预备了一个“未受保护”的位图用来表示哪些是未受保护的对象,一个“标记“位图用来表示哪些对象是被标记了的。 我们通过使用两张位图的逻辑乘积来获取“黑色且未受保护的”对象。
增量式 GC 的暂停时间评估
为了能测量由 GC 造成的停顿时间,让我们使用 gc_tracer gem。gc_tracer gem 引入了 GC::Tracer 模块来捕获 每次 GC 事件时 GC 相关的参数。gc_tracer 会将每个参数输入到文件中。
GC 事件如下所示:
start
end_mark
end_sweep
newobj
freeobj
enter
exit
如我之前所描述的,Ruby 的 GC 分为两部分“标记阶段”和“清除阶段”。“start”事件表示“开始标记阶段”而“end_mark”表示“标记阶段结束”。“end_mark”同时也表示“开始清除阶段”。当然,“end_sweep”在表示结束“清除阶段的同时也表示一个 GC 处理过程的结束。 “newobj”和“freeobj”很容易理解:关于对象的分配和释放的事件。 我们使用“enter”和“exit”事件来测量停顿时间。增量式 GC(增量式的标记 和 惰性清除)引入了标记和清除两个阶段。“enter”事件表示 “进入 GC 相关事件”而“exit”事件表示“退出 GC 的相关事件”。 下图展示了当前增量式 GC 的事件持续时间
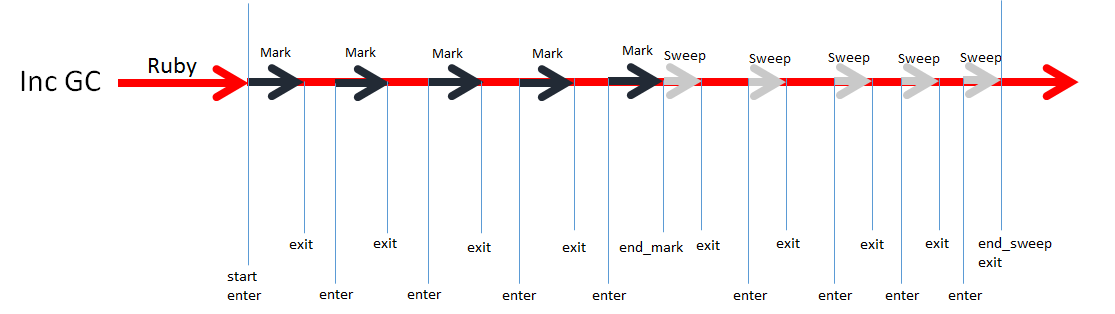
GC 事件
我们能够测量出每个事件的当前时间(在 Linux 机器上,当前时间是 gettimeofday() 的结果)。所以我们能够通过“enter”和“exit”时间 来测量 GC 停顿时间。 我以 ko1-test-app 为基准来做测试。ko1-test-app 是一个由我们的英雄 "Aaron Patterson" 为我编写的简单 Rails 应用。为了使用 gc_tracer,我添加了一个像这样的 rake rule“test_gc_tracer”。
diff --git a/perf.rake b/perf.rake
index f336e33..7f4f1bd 100644
--- a/perf.rake
+++ b/perf.rake
@@ -54,7 +54,7 @@ def do_test_task app
body.close
end
-task :test do
+def test_run
app = Ko1TestApp::Application.instance
app.app
@@ -67,6 +67,22 @@ task :test do
}
end
+task :test do
+ test_run
+end
+
+task :test_gc_tracer do
+ require 'gc_tracer'
+ require 'pp'
+ pp GC.stat
+ file = "log.#{Process.pid}"
+ GC::Tracer.start_logging(file, events: %i(enter exit), gc_stat: false) do
+ test_run
+ end
+ pp GC.stat
+ puts "GC tracer log: #{file}"
+end
+
task :once do
app = Ko1TestApp::Application.instance
app.app
然后执行了 bundle exec rake test_gc_tracer KO1TEST_CNT=30000。指定 30000,表示我姐们将会模拟 30000 个请求。我们 会在一个名为“log_XXX”的文件中找到结果。该文件应包含如下内容
type tick major_by gc_by have_finalizer immediate_sweep state
enter 1419489706840147 0 newobj 0 0 sweeping
exit 1419489706840157 0 newobj 0 0 sweeping
enter 1419489706840184 0 newobj 0 0 sweeping
exit 1419489706840195 0 newobj 0 0 sweeping
enter 1419489706840306 0 newobj 0 0 sweeping
exit 1419489706840313 0 newobj 0 0 sweeping
enter 1419489706840612 0 newobj 0 0 sweeping
...
在我的测试环境中,共有 1142907 行。
“type”字段表示 事件类型 而 tick 表示当前时间(gettimeofday() 的结果,elapesd time from the epoc in microseconds) 我们能通过此信息获知 GC 造成的停顿时间。通过开头两行,我们能测量出一个 10us 的停顿时间。 下面的脚本展示了每个停顿时间
enter_tick = 0
open(ARGV.shift){|f|
f.each_line{|line|
e, tick, * = line.split(/\s/)
case e
when 'enter'
enter_tick = tick.to_i
when 'exit'
st = tick.to_i - enter_tick
puts st if st > 100 # over 100 us
else
# puts line
end
}
}
这里有太多行了,所以该脚本打印出了超过 100us 的停顿时间。 下面的图表展示了测试结果。 我们在分代垃圾回收中可能有 7 个长时间的停顿。它们应该是由 MajorGC 造成的。最长的停顿时间大约 15ms。然而,增量式 GC 降低了最长停顿时间 大约 2ms。太棒了。
总结
Ruby 2.2 引入了增量式 GC 算法以缩短由于 GC 造成的停顿时间。 需要注意的是增量式 GC 不是万能的。如我所描述的,增量式 GC 不会影响”吞吐量“。这意味着它对由于一个过长的请求的响应所造成的长时间响应 并由此引起的多个 majorGC 无能为力。总体上的 GC 停顿时间并没有因为增量式 GC 而缩短。