分享 基于地址位置,查询附近的人 ,解决方案及性能分析 [已更新, 详见下面的结论]
1、场景介绍
对于很多 LBS 应用来说,让用户寻找周围的好友 可能 都是一个必不可少的功能,下面 我们就以这个功能为例:
- 显示我附近的人
- 由近到远排序
- 显示距离
对于以上的问题,目前解决方案有很多种,比如:
a. 基于 MySQL 数据库 b. 采用 GeoHash 索引,基于 MySQL c. MySQL 空间存储(MySQL Spatial Extensions) d. 使用 MongoDB 存储地理位置信息 e. 使用 PostgreSQL 存储地理位置信息
关于 a、b、c, 这篇文章 已经很好的说明了,这里就不一一赘述,下面我们主要是基于方案 d 深入探讨一些东西。
2、使用 MongoDB 存储地理位置信息
MongoDB 原生支持地理位置索引,可以直接用于位置距离计算和查询。查询结果默认将会由近到远排序,而且查询结果也包含目标点对象、距离目标点的距离等信息。
而且 geoNear 是 MongoDB 原生支持的查询函数,所以性能上也做到了高度的优化,完全可以应付生产环境的压力。
3、MongoDB 索引介绍
2d index:
使用 2d index 能够将数据作为 2 维平面上的点存储起来,在 MongoDB 2.2 以前 推荐使用 2d index 索引。 现在 MongodDB 2.6 了,推荐使用 2dspere index
2dsphere index:
2dsphere index 支持球体的查询和计算,同时它支持数据存储为GeoJSON 和传统坐标。
4、性能测试
先说说 测试环境:
Mac Pro(处理器 Intel Core i5、2.4 GHz、2 核、16G 内存) + Mongo 2.6 + Rails4.1.4
model 代码:
class User
field :location, type: Array
index({ location: "2d"}, { background: true })
# 或者 index({ location: "2dsphere"}, { background: true })
class << self
def nearby(coordinate, max_distance=5)
# 5公里内, 符合条件的记录, 默认取100个。同时会按照距离的远近 进行排序。
self.geo_near(coordinate).max_distance(max_distance.fdiv 6371).spherical.distance_multiplier(6371000)
end
end
end
使用 命令1的 查询时间:
User.nearby([117.490219, 40.962954]).count
# 5公里内, 符合条件的记录, 默认取100个。同时会按照距离的远近 进行排序。
# 距离 存在 attributes["geo_near_distance"] 中, example:User.nearby([117.490219, 40.962954]).first["geo_near_distance"]
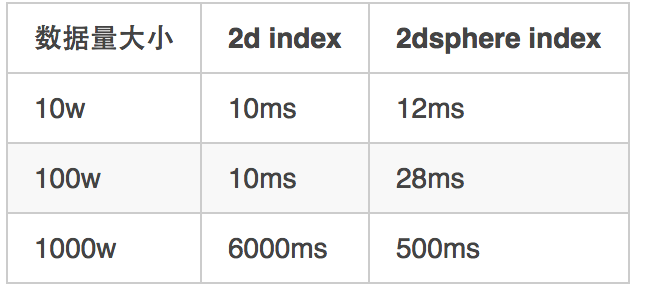
通过测试发现,使用 2d index 在数据量 变大的过程中,查询时间 会变的 非常慢,而使用 2d sphere index 基本可以控制在 0.5s 左右。这里 留下一个问题: 为什么会是这样的?
使用命令2:
User.where(:location => {"$within" => {"$centerSphere" => [[116.490219, 42.962954], (5.fdiv(6371) )]}}).count
# 5公里内, 符合条件的记录、默认会选出所有符合条件的结果。
# 缺点是 需要自己进行排序, 且需要自己计算 geo_near_distance。
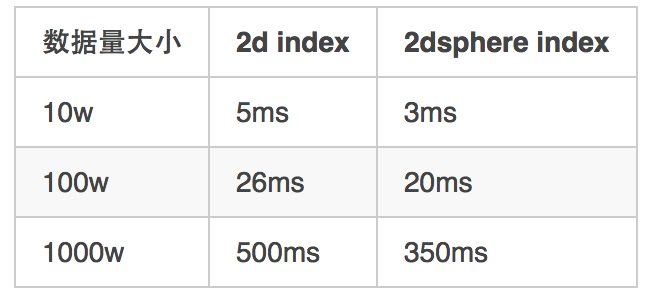
命令2 因为不需要 对 符合条件的结果 进行排序,所以 查询时间 相比 命令1的 查询时间 大大减少。
备注: 每 1w 条 数据的插入时间是 8s 左右。
5、其他的一些 概念的东西
MongoDB 查询地理位置默认有 3 种距离单位: 米 (meters) 平面单位 (flat units,可以理解为经纬度的“一度”) 弧度 (radians)
2d 索引能同时支持$center 和$centerSphere, 2dsphere 索引支持$centerSphere。 关于距离单位,$center 默认是度,$centerSphere 默认距离是弧度。
6、使用 PostgreSQL 存储地理位置信息
关于 PostgreSQL 和 Rails 的结合,可以参考 我同事@windstill的文章, 这里就不具体描述了
测试环境介绍:
Mac Pro(处理器 Intel Core i5、2.4 GHz、2 核、16G 内存) + PostgreSQL 9.3.5 + PostGis2.1.3(PostgreSQL 的扩展) + Rails4.1.4
备注:postgis完整实现了opengis 的 Simple Features标准之中的空间对象模型和函数
测试命令
User.select("users.*, st_distance(location, 'point(116.458104 39.966293)') as distance").where("st_dwithin(location, 'point(116.458104 39.966293)', 10000)").order("distance")
# 查找10公里 内结果, 并按照距离进行排序
测试结果:

7、结论
关于地理位置的计算,其实 Mysql、MongoDB、PostgreSQL 都支持,只不过 MongoDB 和 PostgreSQL 支持的更好一些。 而且通过 测试我们可以发现 MongoDB 在数据量 变大的时候,查询的瓶颈 会变的越来越大。反过来看 PostgreSQL,它的查询时间基本是随着 数据量的增长,而线性增长的。
所以 如果你的应用 数据量不大 或者说在百万级别的话 可以考虑用 MongoDB。但是如果数据量是千万级别或者更高的话,推荐使用 PostgreSQL。
当然了 由于我们这个项目业务既 需要 事务,又需要 Geo 计算,所以选择 PostgreSQL 作为我们的主数据库。
8、留坑
后期 会在使用 PostgreSQL 使用一段 时间后,深入的总结一些关于它的东东...


 其实我想问的是生产中获取坐标哪个服务更好用……
其实我想问的是生产中获取坐标哪个服务更好用……