数据库 PostgreSQL 的异步操作接口,以及 Ruby 中对应实现
我们团队一直在用 padrino 框架做开发,数据库操作,是用 sequel 这个轻量级库。 在开发中遇到数据 IO 的瓶颈,就想把数据库操作改为异步的,来提升代码性能。
原以为 sequel 默认都是同步方式来操作数据库,但看了源码和说明,才发现 sequel 默认都是在用异步接口:
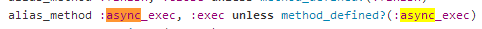
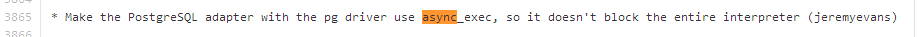 那为啥在使用过程中,一点都没感到异步的快感?
那为啥在使用过程中,一点都没感到异步的快感?
于是就扒了一下 sequel 依赖的那些库:
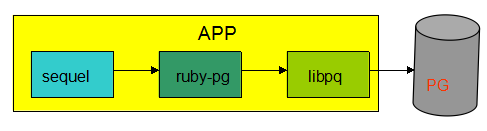 libpq,是 Pg 官方提供的操作接口代码库,C 写的;
ruby-pg,是用 ruby 和 C 写的 gem,实现对 libpq 的拓展,从而实现 ruby 对 Pg 的操作接口;
sequel,是 ruby 写的轻量级 ORM,它实现了数据库连接管理,以及 sql 的生成。涉及数据库接口方面工作,都是依赖 ruby-pg。
libpq,是 Pg 官方提供的操作接口代码库,C 写的;
ruby-pg,是用 ruby 和 C 写的 gem,实现对 libpq 的拓展,从而实现 ruby 对 Pg 的操作接口;
sequel,是 ruby 写的轻量级 ORM,它实现了数据库连接管理,以及 sql 的生成。涉及数据库接口方面工作,都是依赖 ruby-pg。
libpq 本身,确实支持同步和异步两种操作方式:
http://www.postgresql.org/docs/current/static/libpq-async.html
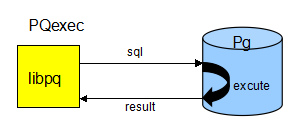
一个数据库连接,就是一条 TCP 连接,libpq 是客户端,Pg 是服务端,
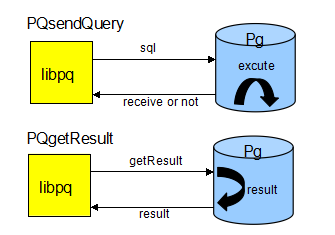
同步方式,libpq 将指令发送到 Pg,Pg 指令执行完成,将结果发回,libpq 收到结果后,才继续执行下面的代码:
 异步方式,libpq 只是把指令发送到 Pg,返回发送结果的标志,想要获取执行结果,需要自己去轮询:
异步方式,libpq 只是把指令发送到 Pg,返回发送结果的标志,想要获取执行结果,需要自己去轮询:
下面看看 ruby-pg:https://github.com/ged/ruby-pg
ruby-pg 对 Pg 的操作,是依赖 libpq 实现的,其中也包含异步操作接口。
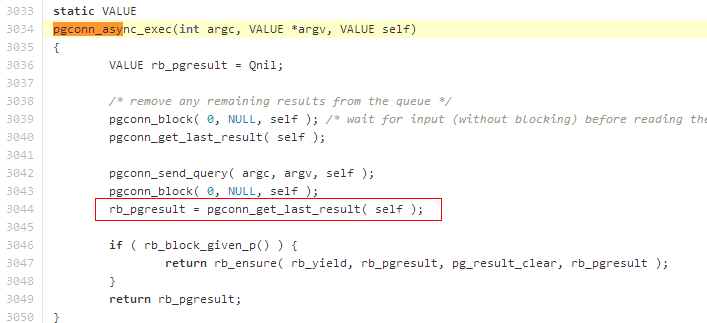
但是,经过 ruby-pg 的封装,异步接口,已经和同步效果一样,看代码:
https://github.com/ged/ruby-pg/blob/master/ext/pg_connection.c#L3034
 https://github.com/ged/ruby-pg/blob/master/ext/pg_connection.c#L2997
https://github.com/ged/ruby-pg/blob/master/ext/pg_connection.c#L2997
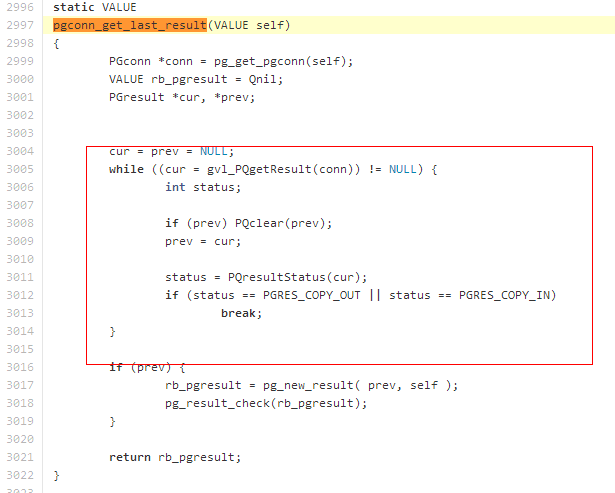 可以看到,在 send_query 之后,紧接着,就实现了一个轮询方法,去 get_result,这个轮询会导致调用程序阻塞,直到获得返回结果。
使用 Pg 中的 pg_sleep(seconds) 来模拟指令执行,通过代码来验证:
可以看到,在 send_query 之后,紧接着,就实现了一个轮询方法,去 get_result,这个轮询会导致调用程序阻塞,直到获得返回结果。
使用 Pg 中的 pg_sleep(seconds) 来模拟指令执行,通过代码来验证:
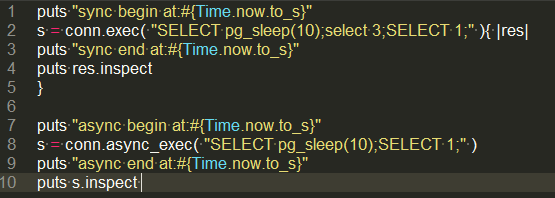 结果 exec 和 async_exec 都在 10 秒后结束,异步和同步的函数,确实都会阻塞 ruby 的解释器。
结果 exec 和 async_exec 都在 10 秒后结束,异步和同步的函数,确实都会阻塞 ruby 的解释器。
也就是说,想要在 ruby 实现对 Pg 的异步操作数据库,ruby-pg 本身不支持。 还是要自己实现个 libpq 的拓展,就把 ruby-pg 中那个轮询的循环去掉就行。
 。
。