算法 请教,多参考项的随机分组?
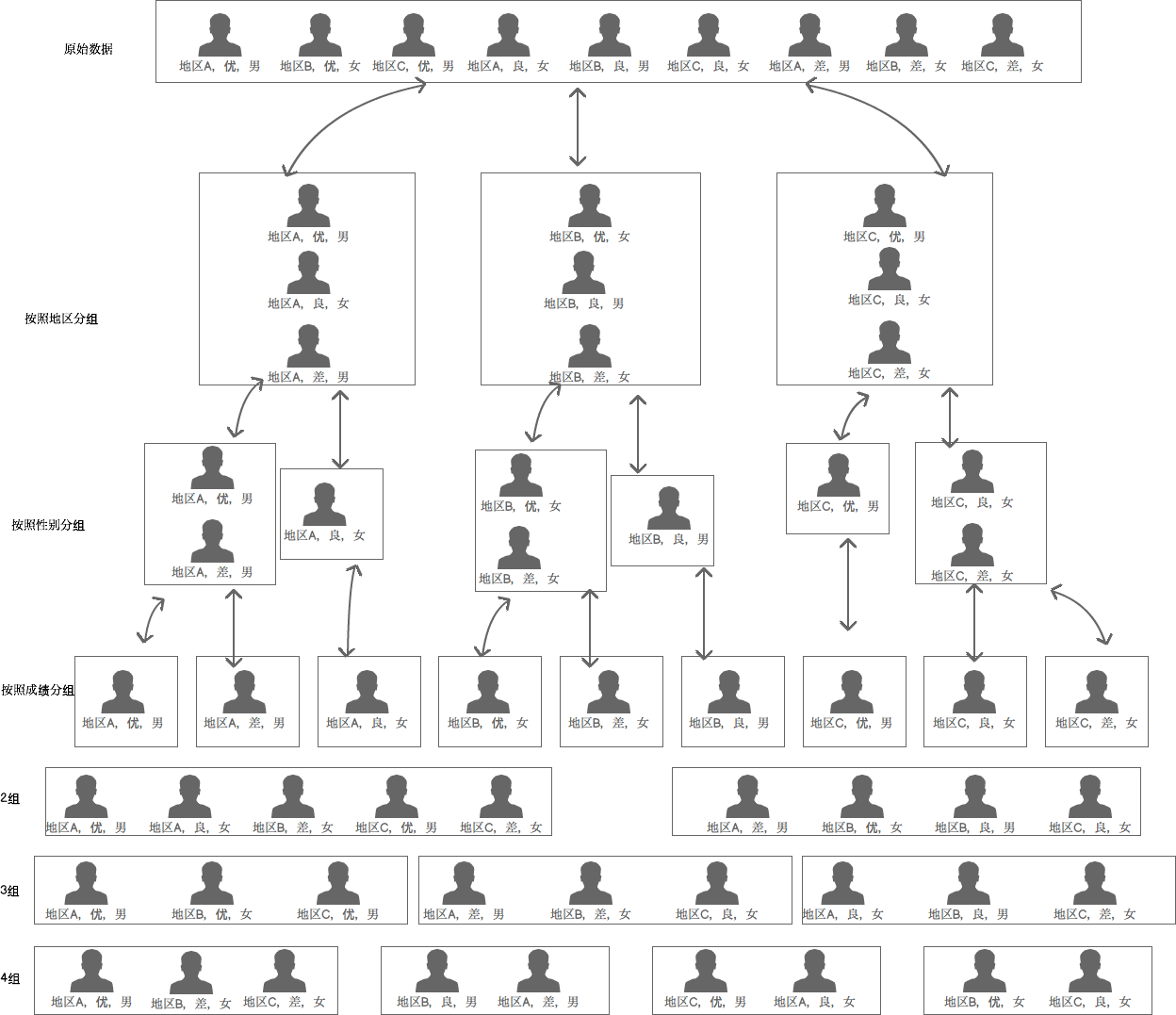
问题大概是这样的:有这样一群人,分别来自 A,B,C 地区,毕业于 M,N,O 等大学,综合评价分别是优、良、差,性别当然是男和女 -_- 1.如何考虑学校,地区,综合评价,性别把他们更分散的分成几组?比如不要同一学校扎堆,同一地区扎堆等 2.是否存在一种算法,可以让我再加入/减少其他参考项,比如年龄分为老中青 3.这种问题是否由典型例题,比如斐波那契数列就来自兔子 向大家请教
我也在知乎请教大家了 http://www.zhihu.com/question/23999896