部署 怎么验证访问速度慢的原因是什么?以及如何优化?
阿里云用了几个月了,网站很多时候访问速度慢,间歇性 Bad Gate 一下,因为还在开发中,所以没有花时间去解决,现在网站要开始推广使用了,这种稳定性实在太糟糕了,想知道到底是我程序没优化好?还是服务器没维护好?还是阿里云的速度问题?
对于小网站来说 阿里云本身的性能还不至于拖慢访问速度 所以应当先从优化的角度入手
请问该怎样去排查呢?
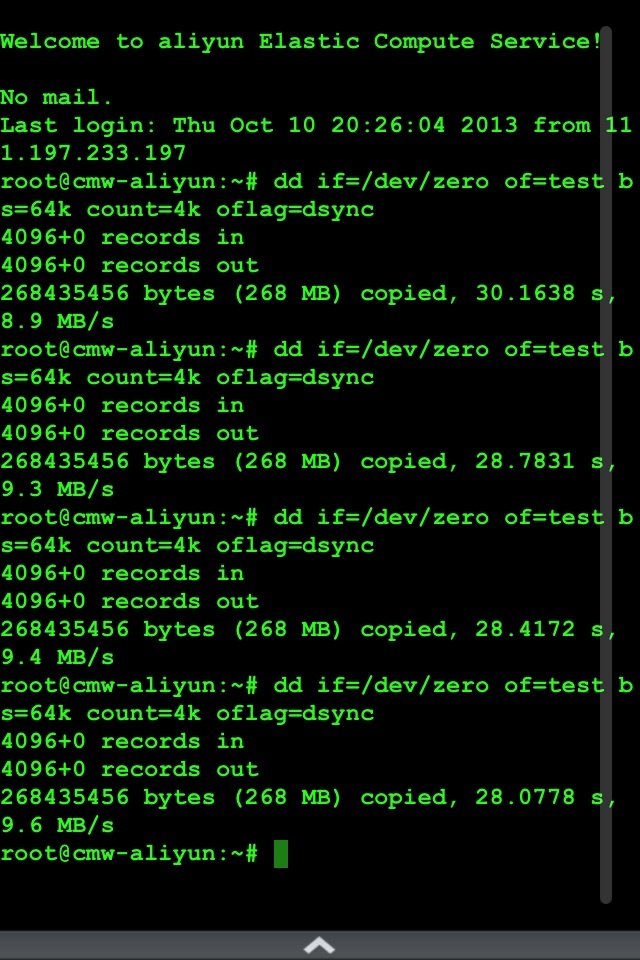
1.磁盘 IO:我用dd if=/dev/zero of=test bs=64k count=4k oflag=dsync 测试了下,在 3~4.5m/s,这能说明问题嘛?
2.数据库存取:用的 mysql,网站数据量小,应该没问题。不过要想查看数据库操作的耗时该怎么做呢?是看 log 里的 ActiveRecord 耗时吗?
3.网站优化:这基本都没做,就是 rails 默认那些……nginx+unicorn 请问基本的优化应该从哪做起?这一块的监测是看 log 中的 Views 耗时吗?
监测
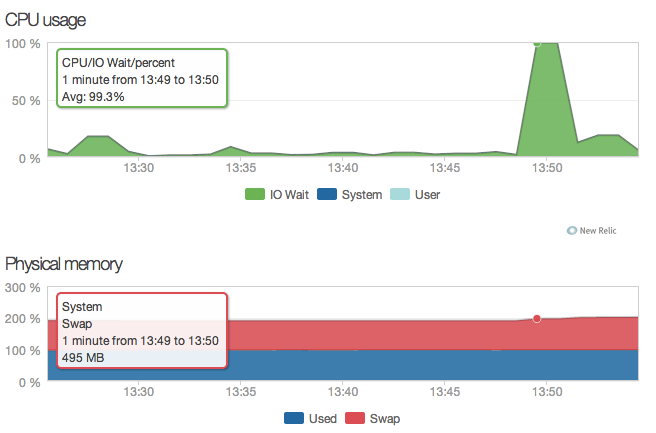
1.使用 newrelc http://newrelic.com ,可以监测程序性能也可监测服务器性能,记得在 My preferences 里把时区改了。 2.Chrome:虽然 newrelic 有 Browser 数据,但毕竟和实际感受不同,建议打开 Chrome 的开发者工具 查看 network 中的时间
优化
1.开启 Gzip:在 nginx 中开启 Gzip 压缩 http://wiki.nginx.org/HttpGzipModuleChs 压缩率 60% 多 感觉速度确实快了 至少到现在为止没有再出现之前那么慢 2.把 js 的 include_tag 放到末尾:感觉一般
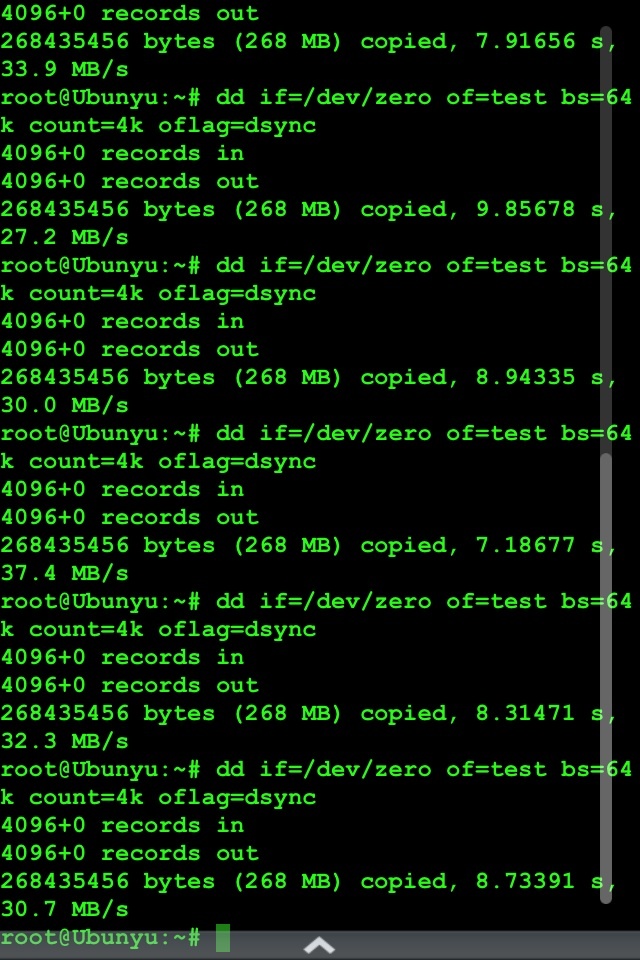
 我自己主要用的服务器 dell 的 r920,raid0 上在 win2008r2 下用 hyper-v 虚拟的 ubuntu,30 多 mb/s,
我自己主要用的服务器 dell 的 r920,raid0 上在 win2008r2 下用 hyper-v 虚拟的 ubuntu,30 多 mb/s,
 最可怜的是前一阵子在 ruby-china 发试用的那个 SendCloud,测试做了两次就做不下去了……一次 885kb/s,一次 952kb/s………
最可怜的是前一阵子在 ruby-china 发试用的那个 SendCloud,测试做了两次就做不下去了……一次 885kb/s,一次 952kb/s………