-
目前项目安装新的 gem 包后 bundle install 一直报错,“Could not verify the SSL certificate for https://gems.ruby-china.com/.”? at 2021年10月09日
 换个浏览器试试看
换个浏览器试试看 -
目前项目安装新的 gem 包后 bundle install 一直报错,“Could not verify the SSL certificate for https://gems.ruby-china.com/.”? at 2021年10月09日
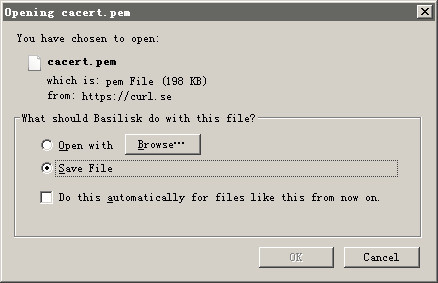
@1370740521 用浏览器下载 http://curl.haxx.se/ca/cacert.pem 保存到某个目录 比如 c:\ca
然后设置环境变量
set SSL_CERT_FILE=c:\ca\cacert.pem -
【深圳】云长科技 2021 年诚聘 Flutter 工程师 1~2 名 at 2021年10月08日
所有的多端方案都是鸡肋,从 ionic 到 taro。追求定制性和体验就用原生,有 as instant run,现在原生的开发要比多端更简单,效率更高 多端方案只是写个 helloword 的页面很快 越到后面越难,再想回头已经回不去了,最后做着做着做成闲鱼那样一沱翔,任凭用户随便骂,直接躺地上装死,因为马云也没办法啊

-
目前项目安装新的 gem 包后 bundle install 一直报错,“Could not verify the SSL certificate for https://gems.ruby-china.com/.”? at 2021年10月08日

项目完工以后写工作总结:相比而言 rails 开发效率太高了
-
proc 中可以改变外部变量的值吗? at 2021年10月05日
加了这个 print 就停不下来,只是想在 call_proc 中使用,对其他代码无影响
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年10月03日
在 class << self 里面的类方法里面,有办法访问类的普通成员变量吗?aa 是定义在 A 下面的 class << self 只定义了 bb 比如 如果在 class << self 要访问 A下面 aa 怎么写?
class A attr_accessor :aa def initialize @aa=10 end def ten puts self.object_id dup.five end def five puts self.object_id @aa / 2 end class << self attr_accessor :bb def getbb @bb = 200 end def getaa @aa end end end a = A.new p a.five p a.ten p a.five p A.getbb p A.getaa -
远程办公,新加坡上市公司招聘 JAVA--30K~50K 欢迎来撩 at 2021年09月30日
-
YJIT 把 ActiveRecord 的速度提升了 1.37 倍 at 2021年09月30日
意义对每个人都是不同的,对码畜来说,让老板加内存条解决Rails 内存占用比较有意义,而对土憋老板来说 让码畜加班干活到11点而不付一分钱的加班费比较有意义 而 Linus 觉得写完代码炮轰 cpp 太烂有意义 统一的意义只有在西部世部的机器人写代码中才有。
有主张没办法是逃避问题,转移焦点的典型话术,这种情况一般是参加成功学培训多了,什么只要努力免费加班,就能加薪,只要努力挖煤,就能有一天当上煤老板。只要添转加瓦,Ruby 就有一天能做大做强之类的。
就我的个人观点,ruby 即没有必要做大做强 在可以预见的将来也不可能做大做强。 ruby 需要解决的是特定领域的特定问题,比如像金数据那样解决 form 表单的问题 象 sequel 那样初期解决项目原型快速迭代的问题
Rails3 在只专注后端,google 可以流畅访问的时侯,是可以实现项目原型快速迭代的,但是现在的 rails 版本捆绑着一堆强藕合东西,在众所周知的玻璃墙越架越高,各种花式限流的阻挠之下, 用 rails 实现快速迭代已经不再具有优势,反而低并发,高内存占用成为项目一定规模以后的棘手的难题。
现在技术领域有一个令人不安的趋势,资本提供一个主流解决方案 这个主流方案中的的出现的任何问题都应该回避,任何跟资本导向不利的方向都是被 diss 的,很象 weibo 上看不见,摸不着的各种红杠杠。你在够烂社区说最常用的 slice 都有很严重的坑,旁边马上跳出来一个码农说你态度有问题。 资本不仅控制着码农用什么技术 还在控制着码农用什么版本的技术 现在正在力图精细控制码农的面部表情,象西部世界那样让高级机器人写高级代码,生产另一批低级机器人写码畜们所写的那种 repeat 的代码正在一步步成为现实。 我说的不仅是 ruby 社区 而是所有技术社区都是这种趋势。资本控制下的码农不再去主导技术的发展,而是蜕化成一个跑龙套的,关心态度比关心技术问题本身更重要,更关心正能量,友善的态度,关心拉帮结派,拜山头,认大哥,交投名状 任何不随大流的都先揪出来批斗一番 至于讨论的技术问题是什么 根本不重要。 以前是在技术支持行业特别流行这个观念,你可以不解决客户面临的任何实际技术问题,但你一定要态度好,能讨客户欢心是最重要的,因为最终是客户掏钱买服务,客户花钱买个开心也是挺值的。 现在这个观念蔓延到了开发领域,技术本身不重要,需要解决的问题也不重要,重要的是要随大流,要有看齐意识,虽然大哥不发钱,但一定要紧跟大哥的步伐,要圈在笼子里千万不要到处乱跑,外面的世界太险恶了。
在形成资本控制的技术牢笼以后。老罗说的猴子不吃香焦的故事一遍一遍地重复上演 被圈在笼子里老猴子们已经习惯了不吃香焦 有新猴子胆敢吃香焦,老猴子们围上来不是解释1,2,3吃香蕉具体有那些坏处 而是上来就是一顿暴打。最大的梦想就是做大笼子,笼子要招新猴子,一定要招不吃香蕉的新猴子才可以
很不巧的的,我不是那种热衷听成功学讲座然后来回说车轱辘话回避实际问题的人 我是寻求解决方案的人 我最喜欢最热衷的事就是打破砂锅问到底,不见黄河不死心。回到主题 我想问的是
- rails 的高内存占用的终极解决方案是什么,是不是象码农那样一看 ide 内存不够了,按 reset 重启电脑就行了?
- rails 项目规模级超过 1000w 的后续解决方案是什么 是不是一劈两半,分裂两个 500w 的 rails 项目,让 rails 的天花板始终处于 1000w 以下
- 在人口结构421,玻璃墙越架越高的前提下,ruby 圈人很少 ruby 社区吸引新人的方案是什么,靠大哥说得对,你看我态度好浑身上下每个毛孔都散发着正能量 来吸引新人入圈吗?
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月30日
这个写法很少见啊,我搜 self 都没见过 你在哪看到这个写法
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
用 MyApp 是对的
require "rack" handler = Rack::Handler::WEBrick class Base class << self def route @route ||= Hash["get" => {}] end def request @req end def get(path, &block) route["get"][path] = block end end end class MyApp < Base get "/" do print request.inspect "access request" end get "/favicon.ico" do File.open "favicon.ico",&:read end end class RackApp def call(env) dup._call(env) end def _call(env) path = env["PATH_INFO"] method = env["REQUEST_METHOD"].downcase MyApp.instance_variable_set :@req, Rack::Request.new(env) cb = MyApp.route[method][path] resp = cb.call [200, { "Content-Type" => "text/html" }, [resp]] end end handler.run RackApp.new另外提高程序的运行速度是在特定的场景下有前提的 比如机器轻负荷并且任务单元互相独立没有依赖关系的情况 典型的象迅雷下载文件的场景,但你在一台重负荷的机器上用多线程安装 gem 并不会提高程序运行速度,反而可能降低速度。不要迷信一些书上的结论,可能写书的老先生是20年前 mfc 桌面软件流行的时候写的,现在的应用场景与以前完全不同了,在 web 环境下,response 是完全依赖 request 的,你不可能没解析完 request,就把 response 发出去。技术问题要看需求场景和实际数据,比如同样的机器多进程/多线程在机器负荷不同的情况下结果完全不同,高负荷的机器上,多进程的并发数是高于多线程的,如果你只会背书,除了说一些貌似正确的废话,面对实际问题,只会一脸蒙逼了
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
多线程的问题太多了,框架线程安全了,并不能保证所用的 gem 都是线程安全的 主流的浏览器多 Tab 浏览开始用的多线程,到最后都搞不定了内存问题,无一例外地都换成了多进程结构
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
多线程的是为了省内存啊,多进程和多线程除了内存还有啥不同?
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
rack 的 call 不是并发安全的吗?
-
YJIT 把 ActiveRecord 的速度提升了 1.37 倍 at 2021年09月29日
1 楼说的对,你也说得没错,我来总结一下,公司用 rails 的主要目的就是开头走个过场,rails 领进门,修行在 java,翻译成白话就是 传说中的导流量 导完流量后 原地解散的 Rails 团队再去 ruby 社区添砖加瓦,还能利用起来,最后把 ruby 社区做大做强 一点都不带浪费的。 做大做强 ruby 社区以后还可以打打拳去微博怼社会话题 顺便给微博导流量。多年以后,回顾 ruby 码农的一生,一生都在导流量 如果不是正在导流量,就在正走在去往导流量的路上
-
YJIT 把 ActiveRecord 的速度提升了 1.37 倍 at 2021年09月29日
如果 ruby 社区不用区分 ruby 内存/rails 内存/gem 内存 仅仅是内存困扰的的话,按 1 楼说的方案用 java 可是极好的,rails 团队原地解散,指望老板加内存来实现给 ruby 添砖加瓦根本不靠谱,老板都是用现成的,直接用现成的 java 的砖瓦,java 的砖瓦海了去了 相对 rails crud 甩 ruby 10 条街不止
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
上面的例子 不考虑 实例的情况 就是自定义的类不用 new 的用法
比如 下面这段代码,Base/MyApp 都不运行 new 也正常读到 params 只是 block 中要写成
Base.requestrequire "rack" handler = Rack::Handler::WEBrick class Base class << self def route @route ||= Hash["get" => {}] end def request @req end def get(path, &block) Base.route["get"][path] = block end end end class MyApp < Base get "/" do print Base.request.inspect # print request.inspect "access request" end end class RackApp def call(env) dup._call(env) end def _call(env) # req = Rack::Request.new(env) path = env["PATH_INFO"] method = env["REQUEST_METHOD"].downcase Base.instance_variable_set :@req, Rack::Request.new(env) cb = Base.route[method][path] resp = cb.call [200, { "Content-Type" => "text/html" }, [resp]] end end handler.run RackApp.new -
YJIT 把 ActiveRecord 的速度提升了 1.37 倍 at 2021年09月29日
困扰内存的不是 ruby 是 rails
很多人 ruby/rails 傻傻分不清 只能重回幼儿园看图识 ruby
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
-
YJIT 把 ActiveRecord 的速度提升了 1.37 倍 at 2021年09月29日
原来的 rails 团队就地解散。语言是码农的工具,码农是老板的工具,就象 obj/instance 是 class 的实例,class 是 Class 的实例一样
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月29日
按 class 是 Class 的一个实例的说法,Class 的实例 class XXX 中的 attribute 用 @req来表示实例变量是可以的,实际上写 getter/setter 都能正常访问 也不报错
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月28日
用
Base.class_variable_set :@req, Rack::Request.new(env)报错 ERROR NameError: `@req' is not allowed as a class variable name
用
Base.class_variable_set :@@req, Rack::Request.new(env)是可以的但定义类的时侯 不管是实例方法 或者类方法 getter/setter @req 都是正常的,只是同一个名字,不同的 object_id 这算不算坑?
test.rb
class Test attr_accessor :req class << self def setter val @req = val end def getter @req end def request @req end end end #Test.class_variable_set :@req,"foo" Test.setter "foo" p Test.getter p Test.request t = Test.new t.req = "bar" p t.req -
(可远程)【成都】澳昇能源 2021 年诚聘 ruby 工程师 at 2021年09月28日
前司用的 Rails 几?
-
元编程是用 eval 实现的吗? at 2021年09月28日
有没有人觉得 ruby 的元编程很象 c 里面的宏 基类定义一 堆复杂的方法 相当于 define 宏
#define DECLARE_DYNAMIC(class_name) \ public: \ static const CRuntimeClass class##class_name; \ virtual CRuntimeClass* GetRuntimeClass() const; \然后在子类中传参数
class CMyClass:public CObject { DECLARE_DYNAMIC(CMyClass) };继承的时侯相当于宏展开 然后有子类 class 名称 有方法名,有接收的参数,然后用 send 就可以随便调用了 客户代码只接收必要的参数,其他成员变量就用 class_variable_set/instance_variable_set 动态添加 方法就用 class_eval/instance_eval/module_eval 动态添加
-
在 block 中怎么访问到类的 attr_accessor ? at 2021年09月28日
attr_accessor 的用法是针对实例方法的,如果 Base 不想生成实例,只用类方法实现(写在 class<< self 中) req=的 setter 要带 env 参数 这个 env 参数只能从 rackapp 的 call 中才能获取 怎么样实现 类似 req= 的功能?
-
(可远程)【成都】澳昇能源 2021 年诚聘 ruby 工程师 at 2021年09月27日
成都不会超过 15k 去面试有超过的在这里回贴
-
对于简单脚本,感觉 perl 写得舒心一点 at 2021年09月27日
ruby 最 happy 除了嵌套的 end 太多容易串行
module Web module Controllers module Home class Index include Web::Action def call(params) print “开始写代码" if params else end end end end end end -
元编程是用 eval 实现的吗? at 2021年09月27日

类里面既不是 attributes 又不是 initialize/method 中间的这段代码的正式术语叫什么?
-
include Singleton 和 class << self 有什么区别 at 2021年09月26日
但是长得都一样,怎么区分呢?靠感觉吗?
-
如果应用没有负载均衡之类的需求,只是单机部署,用 puma 和 nginx 起服务是不是没有区别呢? at 2021年09月26日
nginx+ rack 专业的工具做专业的事
妄想用银弹解决一切的想法是错误的,只会让自己掉进坑里爬不出来