-
rails 里面的枚举类型 at 2019年05月30日
不过是有 true 或者 false,查询或者更新的时候还要写 scope 或者 update 例如上面的例子还要写下面的内容才能实现相同的效果:
scope :enabled, -> { where(enabled: true) } scope :disabled, -> { where(enabled: false) } def enabled! update(enabled: true) end def disabled! update(enabled: false) end其实无所谓了,只是想偷个懒

-
mysql 为什么不走索引? at 2018年11月18日
多谢大神指点
-
mysql 为什么不走索引? at 2018年11月17日
家里还有两亩地呢
-
mysql 为什么不走索引? at 2018年11月17日
谢谢胡的解答。北京要饭的成本太高,不被饿死就不错了。
-
mysql 为什么不走索引? at 2018年11月17日
《数据库索引设计和优化》这本书不知道有没有介绍走索引的依据。先看看吧
-
mysql 为什么不走索引? at 2018年11月17日
是可以这样做;但还是想知道走索引和不走索引到底是根据什么判断的
-
mysql 为什么不走索引? at 2018年11月16日
明白了。就是说 InnoDB 的索引虽然采用的 B+tree 结构,大原则上也遵循最左匹配;但是真正执行查询的时候,会根据实际情况,不一定会走索引。有一问题咨询一下,如果 SQL 已经被缓存了(Mysql 开启了查询缓存),是不是也不走索引了,而是拿到缓存的数据直接返回应用层。
-
mysql 为什么不走索引? at 2018年11月16日
不管学什么语言,数据库的东西都需要掌握
-
mysql 为什么不走索引? at 2018年11月16日
Go 已经看了一点儿了,在大学的时候就学的 java,那个时候还是 jdk6.0,现在都 9 了吧,已经赶不上了
-
mysql 为什么不走索引? at 2018年11月16日
这不是找不到工作嘛,闲的蛋疼就看看咯;而且身体也不舒服,在家休息的呗
-
mysql 为什么不走索引? at 2018年11月16日
在添加数据前,执行了三次都是不走索引的
-
mysql 为什么不走索引? at 2018年11月16日
但好像也不是数据量的问题,把数据再清除后,再执行还是走索引

-
mysql 为什么不走索引? at 2018年11月16日
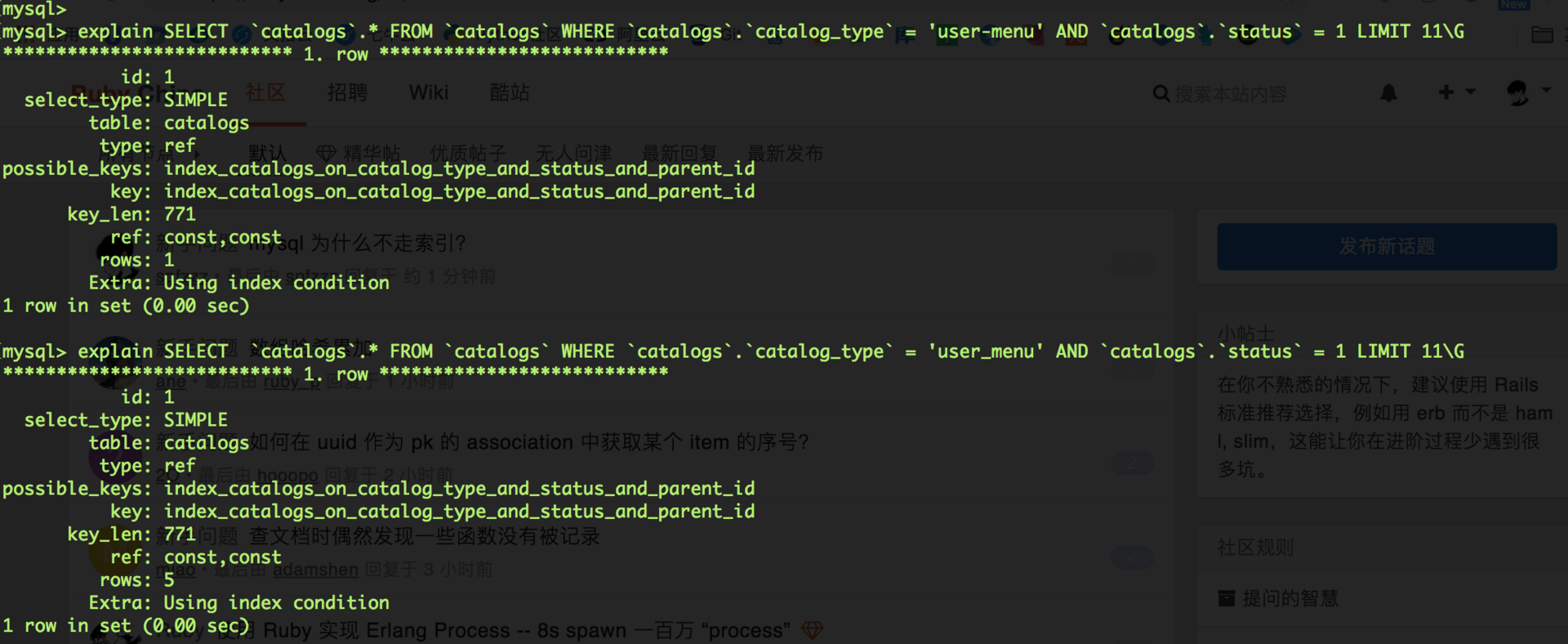
-
mysql 为什么不走索引? at 2018年11月16日
应该是数据太少了,增加了数据后,在执行都走索引了
-
mysql 为什么不走索引? at 2018年11月16日

-
给已存在的类添加类方法和实例方法 at 2018年11月07日
但是还是不明白,Ruby 为什么要把类方法单独放在单例类中,这样做有什么好处?
-
给已存在的类添加类方法和实例方法 at 2018年11月07日
非常感谢提醒,刚翻看了很久没看的《Ruby 元编程》一书,才回想起来 class 关键字的含义
-
给已存在的类添加类方法和实例方法 at 2018年11月07日
平时自定义的类当然是 Class 的对象,这里说的 Ruby 对象偏向于指自定义类 new 出来的对象,同时也包括自定义类;对象里面保存类的指针和实例变量的值的数组。自定义类有两个身份:类和对象。
-
rails5.1.6 production 环境下 server 和 console 的区别和疑问 at 2018年09月29日
解决了:是主从同步数据的问题

-
一个 rails console 的问题 at 2017年03月10日
我就是 bundle install 成功后,执行的