分享 图片是怎么被搜索出来的?
相信大伙平时都有搜索图片的经验,我们只要输入文字,就能通过搜索引擎搜索出相关的图片。
这是因为网站上很多的图片其实都被标签化了,我们搜索图片的时候实际上是匹配它们的标签,本质上是通过语义化的匹配来实现。
不知道大家有没有发现,其实我们的相册也有类似的功能。

这就有点神奇了哈,我们并没有对我们的照片进行标签化,机器是怎么做到对我们的照片进行自动归类的?
以我有限的认知来说,其实可以通过语义化向量的方式去实现。我们抛开大模型的能力先不讨论,毕竟粗暴一点其实我们完全可以让大模型去遍历所有图片,然后从文字总结中抽取标签。然而这种方式成本太高了,目前效率也比较低。
针对图片的向量化,我们其实可以借助目前比较流行的 CLIP,它是一个能够同时理解图片以及文字的预训练模型,主要是通过对比学习(Contrastive Learning)的方式。
其实你可以把它看成是一个经过训练,并且能理解图片内容的一个模型,它以“文字”的形式(语义)对图片的内容进行总结。
CLIP 可以通过向量化的方式把图片的语义进行存储,有点类似我们熟悉的标签。当然这种“文字”对普通用户来说是黑盒子,我们无从得知。我们把“cat”当作一个语义,下次遇到语义相近的图片,就能把它们归成一类。
这里我准备三张图片:
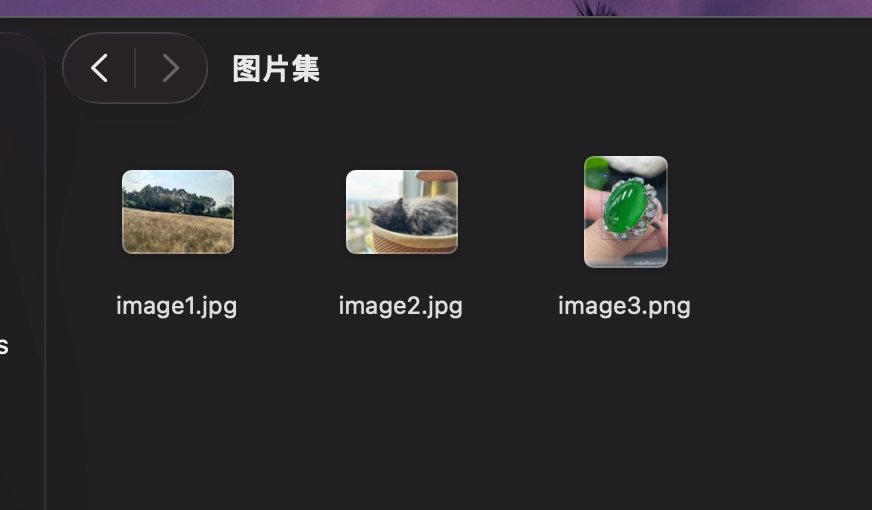
分别是大草坪,猫咪还有一个玉石。根据 CLIP 的官方文档,我们可以通过编写 Python 脚本对图片进行向量化。
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 分别读取3张图,预处理
image1 = preprocess(Image.open("./image/image1.jpg")).unsqueeze(0).to(device)
image2 = preprocess(Image.open("./image/image2.jpg")).unsqueeze(0).to(device)
image3 = preprocess(Image.open("./image/image3.jpg")).unsqueeze(0).to(device)
# 将所有图片合并成一个批次
images = torch.cat([image1, image2, image3], dim=0)
# 搜索关键词 cat
text = clip.tokenize('cat').to(device)
with torch.no_grad():
# 获取图片和文字的特征
image_features = model.encode_image(images)
text_features = model.encode_text(text)
# 归一化后的余弦相似度
image_features_norm = image_features / image_features.norm(dim=-1, keepdim=True)
text_features_norm = text_features / text_features.norm(dim=-1, keepdim=True)
cosine_similarities = (image_features_norm @ text_features_norm.T).squeeze()
# 用 tensor 计算 logits
logit_scale = model.logit_scale.exp()
logits = logit_scale * cosine_similarities
# 转换为 numpy 用于打印
cosine_similarities_np = cosine_similarities.cpu().numpy()
print("=" * 50)
print("归一化的余弦相似度")
print("=" * 50)
print(f"image1: {cosine_similarities_np[0]:.4f}")
print(f"image2: {cosine_similarities_np[1]:.4f}")
print(f"image3: {cosine_similarities_np[2]:.4f}")
# Softmax概率分布
probs = torch.softmax(logits, dim=0).cpu().numpy()
print("\n" + "=" * 50)
print("Softmax概率分布")
print("=" * 50)
print(f"image1: {probs[0]:.4f} ({probs[0]*100:.2f}%)")
print(f"image2: {probs[1]:.4f} ({probs[1]*100:.2f}%)")
print(f"image3: {probs[2]:.4f} ({probs[2]*100:.2f}%)")
在上述代码中,我分别对三张图片进行向量化,假设我的搜索关键词是“cat”,那么关键的代码就是
cosine_similarities = (image_features_norm @ text_features_norm.T).squeeze()
大致可以理解成,从图片的角度来看(有三张图片)我跟“cat”这个单词的匹配度如何。最终打印出来的结果大概是这样:

从归一化余弦相似度来看,image2 的得分最高,觉得自己跟“cat”这个单词较为匹配。更直观的我们可以看下面的 softmax,image2 有 99.94% 的几率跟“cat”匹配。
我们只要设置一个合适的阀值,就能把其他两个不相干的筛掉,留下 image2,作为“cat”搜索的结果。
假设说我们能够把图库里面所有图片都进行语义的向量化,构建一个本地的向量数据库,其实就能够比较容易地构建出一个图片搜索工具了。
当然,这只是计算机视觉比较基础的应用场景,后面我会分享更多的心得体会。几天前我用 Cursor 生成了一个图片搜索工具,具体可以参考我的 Github: https://github.com/lanzhiheng/vm_search 。
公众号:CXO 成长记