Rails 内容审核(头像审核、昵称审核)技术对比,阿里云内容安全审核 api 和大模型 LLM 的 PK 对比
一、背景与目标
1.1 为什么需要做对比
内容审核是社区、电商等业务的基础能力,需对用户上传的头像/图片和昵称/文本进行合规检测。我们之前一直使用的是阿里云的内容审核 api 来检测的,但是偶尔会有检测出错的情况,尤其是头像的广告引流,偶尔会有识别不出来的情况。因此考虑使用大模型能力来做个测试对比:
- 传统审核 API:如阿里云 profilePhotoCheck、text_scan 等
- LLM 多模态审核:通过通义、GPT、Claude 等大模型的提示词限制来判断(我们是通过 Dify 工作流来提供的 api 接口来服务业务系统)
不同方案在耗时、费用、准确度上差异显著,需要系统对比后做出技术选型。
1.2 对比目标
- 梳理各方案(阿里云、通义、GPT、Claude 等)的价格与准确性
- 通过实际测试,验证阿里云 API 与 Dify + LLM 的耗时、费用、准确度
- 给出最终选型与实施建议
二、先直接给出结论
| 场景 | 选型 | 理由 |
|---|---|---|
| 图片审核 | Dify + qwen-vl-flash | 费用约 7 元/万张,低于阿里云 15 元;耗时优于 qwen-vl-plus;准确度满足需求 |
| 昵称审核 | Dify + qwen-plus-latest | 费用约 2.6 元/万次,低于阿里云 7.5 元;对引流、联系方式等更敏感 |
| 兜底/强合规 | 阿里云 | 延迟低、稳定,可作为主流程失败或高并发时的补充 |
三、方案调研
3.1 昵称/文本审核:准确性与价格
| 方案 | 准确性 | 价格 (元/万次) |
|---|---|---|
| 通义 qwen-plus | 高 | 约 3.4 |
| 通义 qwen-max | 最高 | 约 50–60(按 250 input + 80 output token 估算) |
| 通义 qwen-turbo | 中高 | 约 1.1 |
| DeepSeek-V3 | 中 | 约 7.6 |
| GPT-4o | 精确率高、召回率低 | 约 4–5 |
3.2 头像/图片审核:准确性与价格
| 方案 | 准确性 | 价格 (元/万张) |
|---|---|---|
| Qwen-VL-Max | 最高 | 约 19.8 |
| 阿里云 profilePhotoCheck | 高(专项) | 15 |
| Qwen-VL-Plus | 中高 | 约 9.6 |
| Qwen-VL-Flash | 中高 | 约 7(实测) |
| Claude 3.5 Sonnet | 高 | 约 200–300(按单张约 $0.003–0.004 换算) |
| GPT-4o vision | 高 | 约 20–45(随分辨率与 token 波动) |
3.3 阿里云现有方案(对比基准)
| 类型 | 价格 (元/万次或元/万张) |
|---|---|
| 文本审核(增强版) | 约 7.5 |
| 图片/头像审核(profilePhotoCheck) | 约 15 |
四、我们的实际对比测试
4.1 测试设计
- 图片:来自我们实际生产数据的用户头像
- 昵称:30 组预设样本(含正常、敏感、边界)
4.2 图片审核实测
4.2.1 qwen-vl-plus vs qwen-vl-flash(50 张图,统一 q100 jpg)
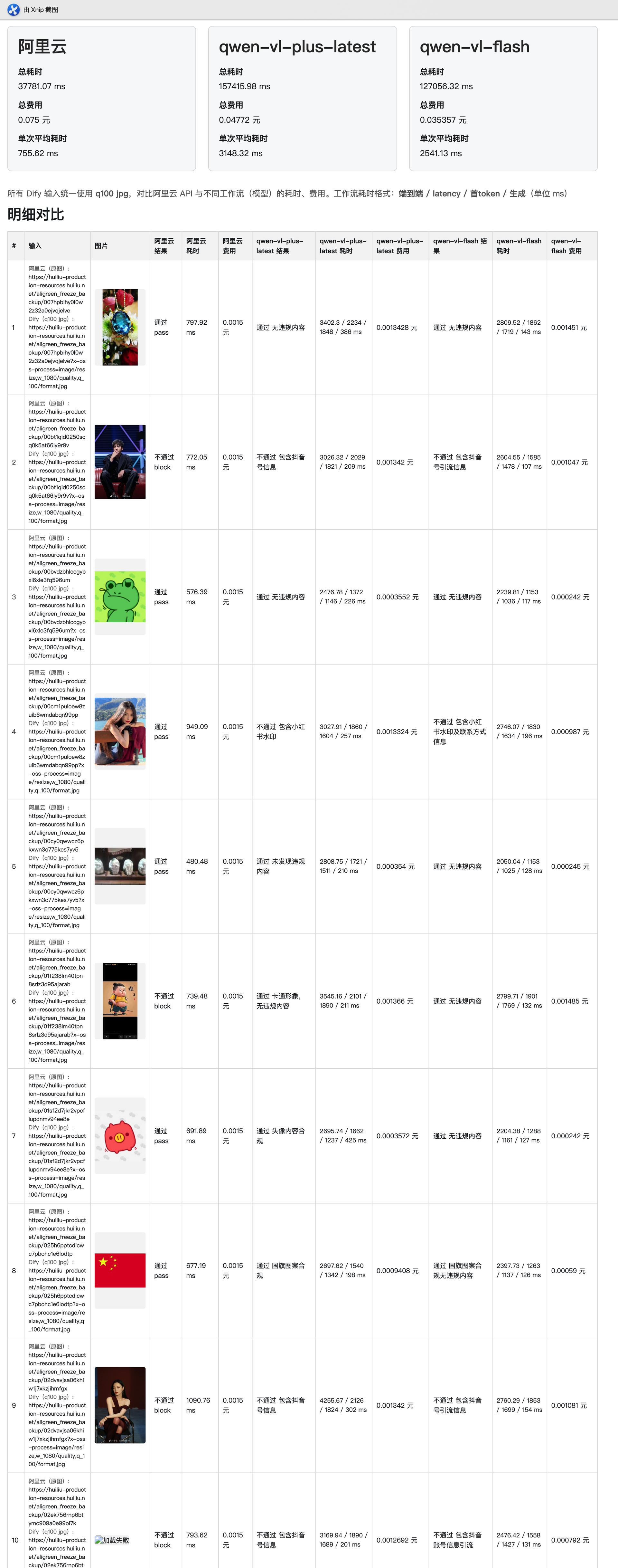


- 注意这张图,引流内容不容易被发现,阿里云 api 就检测通过了,大模型精准识别
| 方案 | 总耗时 (ms) | 总费用 (元) | 单次平均耗时 (ms) | 万张预估费用 (元) |
|---|---|---|---|---|
| 阿里云 | 37,781 | 0.075 | 756 | 15 |
| qwen-vl-plus-latest | 157,416 | 0.048 | 3,148 | 9.6 |
| qwen-vl-flash | 127,056 | 0.035 | 2,541 | 7 |
结论:qwen-vl-flash 费用更低、耗时更短、准确率和 qwen-vl-plus-latest 相当,选型为图片审核方案。
4.2.2 原图 vs 800px 宽格式化为 jpg(image/resize,w_800/quality,q_90/format,jpg
)(80 张图,同一 Dify 工作流)
- 做这个对比是因为现在用户的手机拍照随便都是 5M 起步,如果用原图的话,大模型先下载图片再转成输入 token 就比较大,比较慢了,所以先格式化为宽 800 的 jpg(十几 M 的图片变几百 K)用作大模型输入。
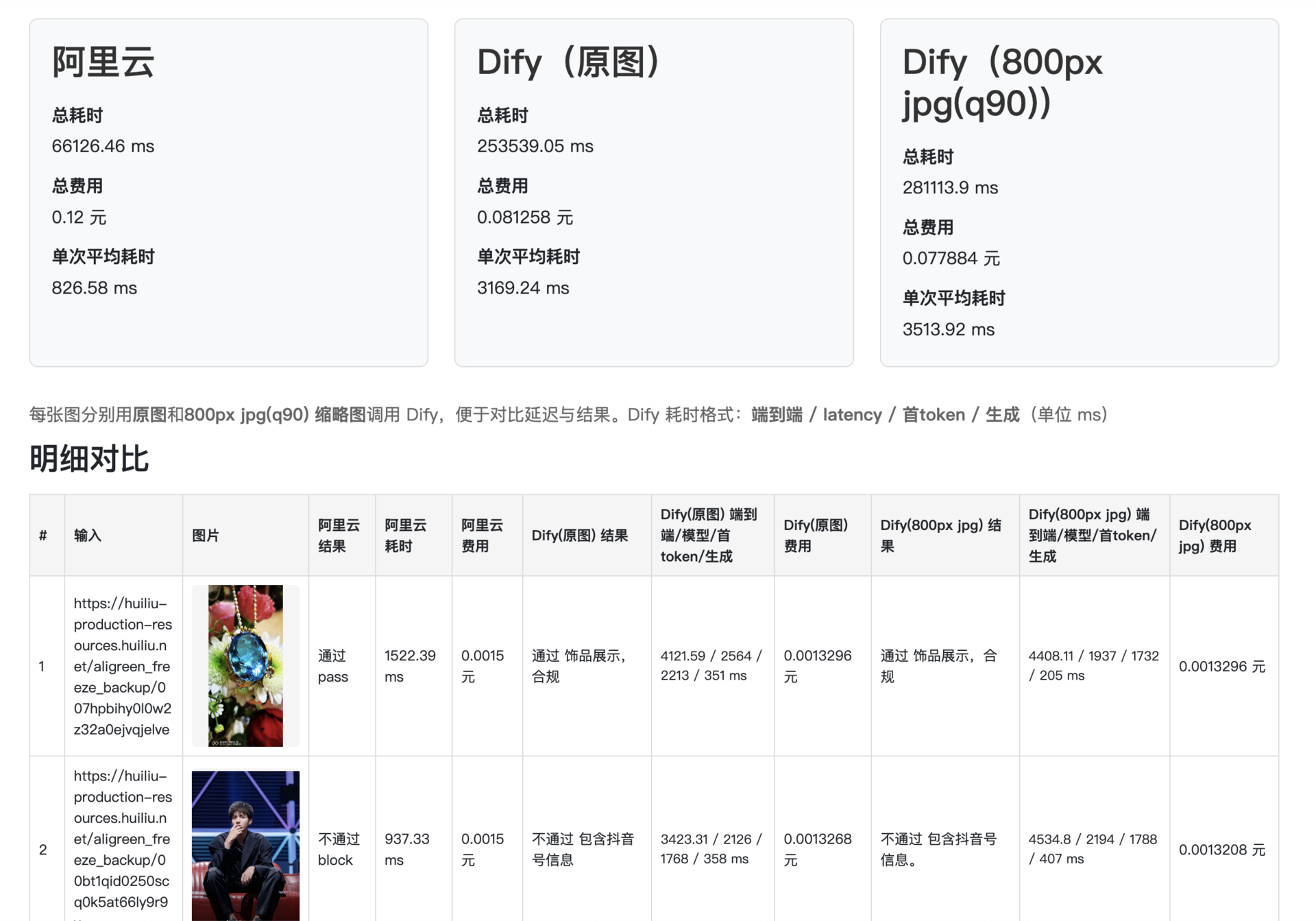
| 方案 | 总耗时 (ms) | 总费用 (元) | 单次平均耗时 (ms) | 万张预估费用 (元) |
|---|---|---|---|---|
| 阿里云 | 66,126 | 0.12 | 827 | 15 |
| Dify 原图 | 253,539 | 0.081 | 3,169 | 10.1 |
| Dify 800px jpg(q90) | 281,114 | 0.078 | 3,514 | 9.7 |
- 说明: 上面这个测试的原图我们保存时候已经转过格式压缩过了,所以这个对比其实是失败的,没有测试出 几兆那种原图和格式化后的图在费用上的差异,写出来只是给大家提供一下思路。
- 结论:最终采用 800px jpg q90 jpg 作为统一输入,兼顾清晰度与体积。
4.3 昵称审核实测(30 组,使用 qwen-plus-latest)
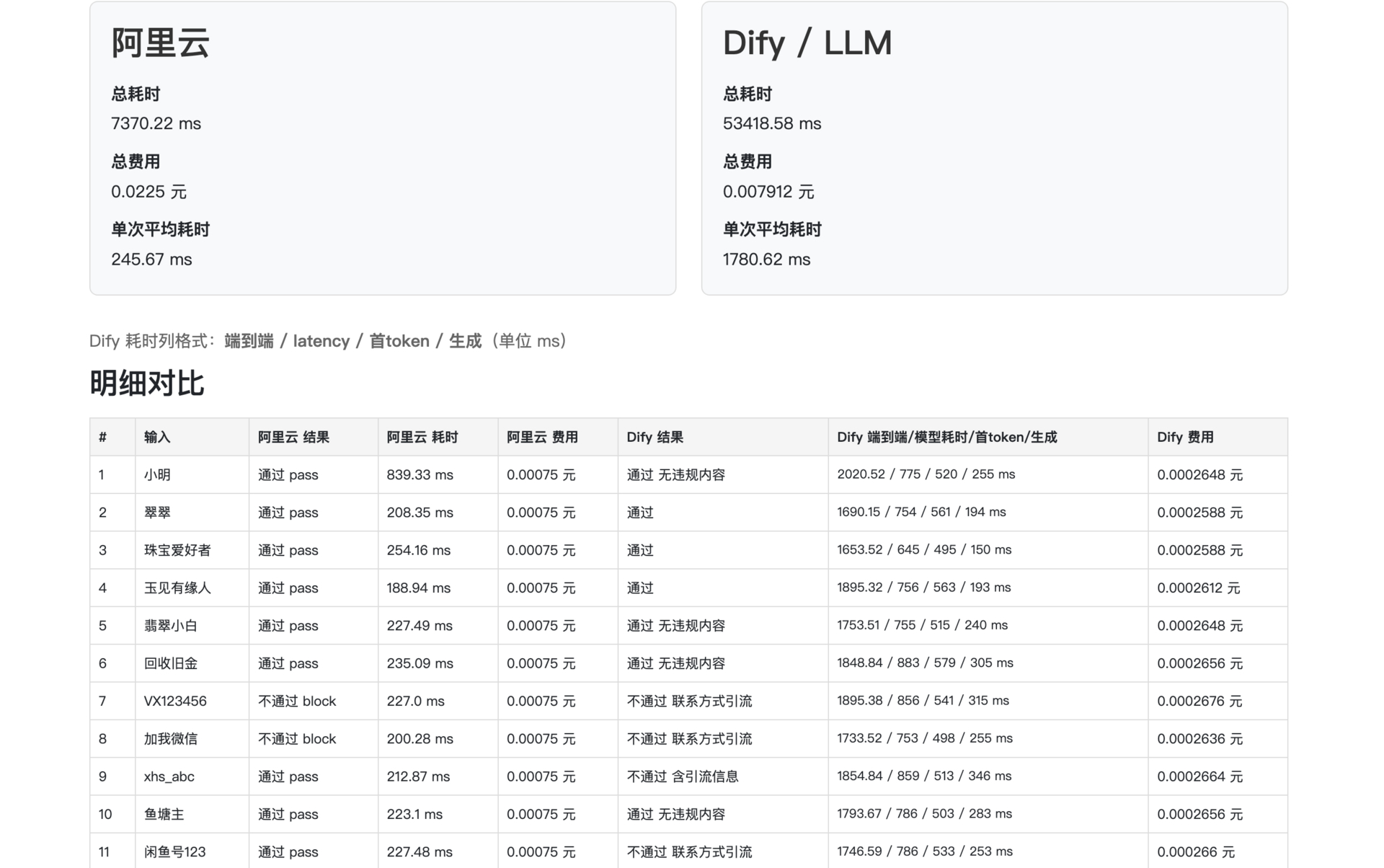
| 方案 | 总耗时 (ms) | 总费用 (元) | 单次平均耗时 (ms) | 万次预估费用 (元) |
|---|---|---|---|---|
| 阿里云 | 7,370 | 0.023 | 246 | 7.5 |
| Dify + qwen-plus-latest | 53,419 | 0.008 | 1,781 | 2.6 |
4.4 准确度对比
图片审核
| 能力 | 阿里云 | LLM (qwen-vl) |
|---|---|---|
| 政治敏感(领导人等) | 识别 | 识别(含 inappropriate content 拒绝) |
| 平台水印/引流(抖音、小红书) | 识别 | 识别 |
| 饰品/合规展示 | 通过 | 通过,可附带说明 |
| 复杂场景/边界 | 规则为主 | 语义理解更细 |
昵称审核
| 测试用例 | 阿里云 | Dify + qwen-plus-latest |
|---|---|---|
| 小明、翠翠、珠宝爱好者 | 通过 | 通过 |
| VX123456、加我微信 | 不通过 | 不通过(联系方式引流) |
| xhs_abc | 通过 | 不通过(含引流信息) |
| 闲鱼号 123 | 通过 | 不通过(联系方式引流) |
结论:qwen-plus-latest 对引流、联系方式类昵称更敏感,拦截更严格。
4.5 我们的 dify 工作流
其实也可以不用 dify 工作流,直接在代码里调用大模型来识别,不过 dify 的好处就是切换大模型简单,可以随时更新其他大模型。
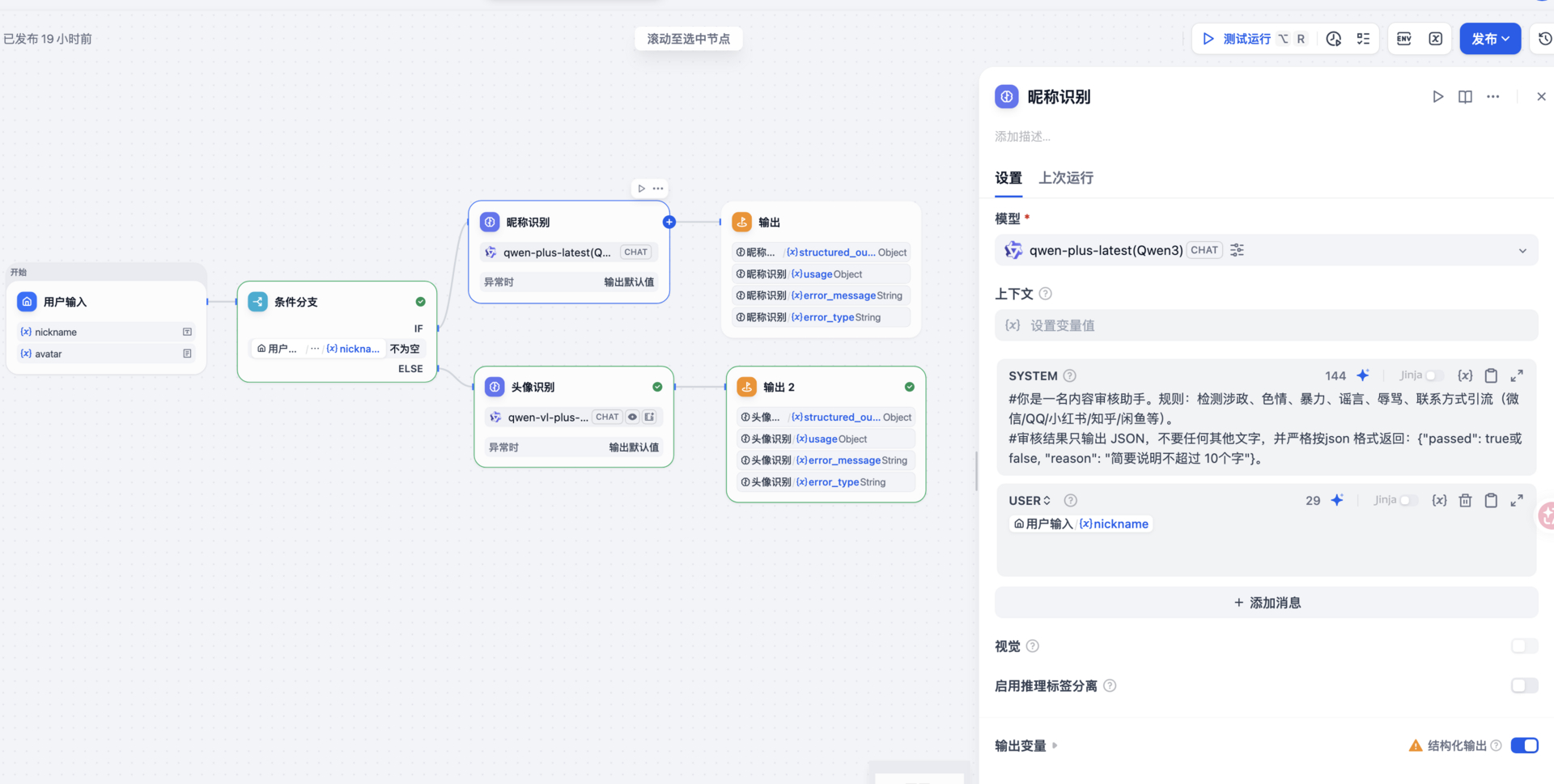
-
说明:大模型的识别能力非常依赖提示词,但我们这种识别其实提示词很简单,后续如果有识别不出来的,把提示词修改一下即可。举例:比如昵称是”你们公司真下头“,这个调用传统内容审核 api 是通过的,但我们不想让他通过,使用传统内容审核就不好定制,但使用大模型的话,我们只用在提示词加一句,如果内容包含”下头“则视为审核不通过。大模型就会按审核不通过处理。是不是特别灵活。
4.6 关于费用怎么对比
阿里云内容审核 api 有明确的文档说明每次调用多少钱
大模型是按输入输出 token 计费的,我们用来 format w800 jpg 格式的图片的话,那输入 token 就是图片和提示词,基本可以确定,输出我们也是严格限制了格式,所以也是确定的。另外 dify 每次调用都会返回 useage,我们保存到数据库即可。方便我们选型和统计
五、阿里云 API vs LLM 优劣势
5.1 阿里云内容审核 API
| 优势 | 劣势 |
|---|---|
| 延迟低:图片约 800 ms,文本约 250 ms | 费用高:图片 15 元/万张,文本 7.5 元/万次 |
| 稳定:成熟商用接口,SLA 保障 | 规则化:依赖预设规则,边界场景易漏检 |
| 部署简单:HTTP 调用即可 | 定制难:无法按业务语义微调策略 |
| 合规背书:符合监管要求 | 结果简单:多为 pass/block,缺少详细说明 |
5.2 LLM 多模态审核
| 优势 | 劣势 |
|---|---|
| 成本低:图片约 7 元/万张,文本约 2.6 元/万次,还有更低成本的大模型可选 | 延迟高:图片 2.5–3 s,文本约 1.8 s |
| 语义理解好:能识别「饰品展示」「联系方式引流」等 | 依赖模型:不当内容可能返回 400,需专门处理 |
| 结果更细:可返回原因说明,便于运营排查 | 需自建工作流:需维护 Dify 与模型配置 |
| 可定制:prompt 可调整审核策略 | 稳定性:依赖第三方模型服务可用性 |
六、最终选型与实施建议
6.1 选型结论
| 场景 | 选型 | 理由 |
|---|---|---|
| 图片审核 | Dify + qwen-vl-flash | 费用最低(约 7 元/万张),耗时优于 plus,准确度满足需求 |
| 昵称审核 | Dify + qwen-plus-latest | 费用低,对引流/联系方式更敏感 |
| 兜底/强合规 | 阿里云 | 低延迟、稳定,可作为主流程失败或高并发时的补充 |
6.2 实施建议
- 图片输入:统一使用 format q90 jpg(oss-process),平衡清晰度与体积
- 异常处理:Dify 返回 400 且含「inappropriate content」时,按不通过处理
- 混合策略:高并发或要求极低延迟时,可考虑阿里云;长尾审核、成本敏感时用 LLM
- 持续监控:记录耗时、费用、通过率,定期对比不同方案表现