都说男生是世界上最简单的动物,为什么呢?举个例子,你要给女朋友送礼,你可以选择包、口红、护肤品、化妆品等,而包的品牌和样式、口红的色号等足以让你挑得眼花缭乱。而男生不一样,如果女生选择给男生送礼,我相信一块 RTX4090 就足以让他高兴得死去活来。

RTX4090 到底是何方神圣?它凭什么赢得所有男生的“芳心”?
了解 GTX4090
我们先来看下 NVIDIA 官方对 RTX4090 的介绍。
The NVIDIA® GeForce RTX™ 4090 is the ultimate GeForce GPU. It brings an enormous leap in performance, efficiency, and AI-powered graphics. Experience ultra-high performance gaming, incredibly detailed virtual worlds, unprecedented productivity, and new ways to create. It’s powered by the NVIDIA Ada Lovelace architecture and comes with 24 GB of G6X memory to deliver the ultimate experience for gamers and creators.
RTX4090 是终极的 GeForce GPU。它带来了性能、效率和人工智能驱动的图形方面的巨大飞跃,体验超高性能的游戏、极其详细的虚拟世界、前所未有的生产力和新的创作方式。它采用 NVIDIA Ada Lovelace 架构,并配备 24 GB G6X 显示内存,为游戏玩家和创作者提供终极体验。
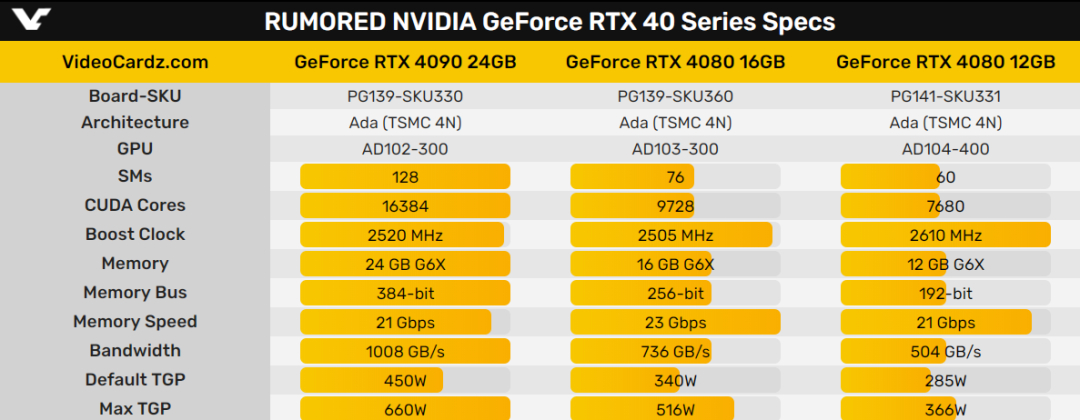
RTX4090 采用的是 AD102 核心,拥有 11 组共 16384 个流处理器、512 个 Tensor Core、176 个 RT Core 和 176 个流处理器单元。RTX4090 采用了 NVIDIA Ada Lovelace 架构,致力于打造出色的游戏与创作、专业图形、AI 和计算性能,采用了新型 SM 多单元流处理器、第四代 Tensor Core、第三代 RT core 等多种新技术。
第四代 Tensor Core
NVIDIA DLSS 3 是 AI 驱动图形领域的革命性突破,可大幅提升性能。DLSS 3 由 GeForce RTX40 系列 GPU 所搭载的全新第四代 Tensor Core 和光流加速器提供支持,可利用 AI 创造更多高质量帧。
另外,凭借全新的 FP8 Transformer 引擎,Ada 的全新第四代 Tensor Core 拥有不可思议的飞快速度,可将吞吐量提升 4 倍,达到 1.4 Tensor-petaFLOPS。
第三代 RT Core
NVIDIA 发明的 RT Core 在视频游戏中实现了实时光线追踪。这种搭载在 GPU 上的特殊核心专为处理性能需求密集的光线追踪工作负载而设计。
Ada 架构采用的第 3 代 RT Core 不仅将光线与三角形求交性能提高了一倍,还将 RT-TFLOP 峰值性能提高了一倍之多。
新款 RT Core 还配备全新 Opacity Micromap (OMM) 引擎和 Displaced Micro-Mesh (DMM) 引擎。OMM 引擎可大幅提升对 alpha 测试纹理进行光线追踪的速度,此类纹理通常应用于树叶、颗粒和围栏。DMM 引擎能够以近乎 9 倍的速度构建光线追踪边界体积层次结构 (BVH),而所占用的显存只有之前的二十分之一。从而实现几何复杂场景的实时光线追踪。
RTX4090 的应用场景
RTX4090 这么强,主要应用在哪些方面呢?
游戏
首先毫无疑问是在游戏方面的应用。RTX4090 是能驾驭各种游戏的硬核 GPU,拥有惊人的性能和超大 24GB G6X 显存,能以 8K 分辨率轻松运行多款热门游戏,支持 HDMI 2.1 所提供的 8K 60Hz HDR 和可变刷新率功能。你可以借助 RTX4090 强大的能力,在 8k 分辨率的 HDR 模式下,可以尽情体验游戏大作,尽享视觉盛宴。这也是为什么 RTX4090 是大部分男生的梦想。
相较于 RTX 3090,RTX4090 的性能基本上能达到它的两倍。当然,相应的功耗也大了不少,比 3090 高出了将近 100W。下图是 RTX4090 和 RTX3090Ti 在各个游戏中的性能对比,大家可以看到 RTX4090 的表现是相当亮眼的。
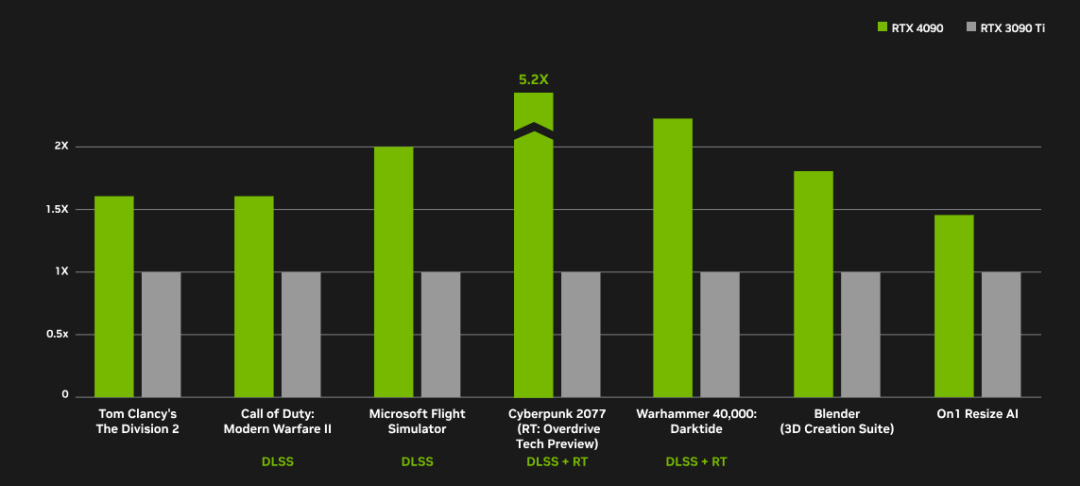
△ RTX4090 vs RTX3090Ti 性能对比
AI 绘画
Stable Diffusion 是我们常用的 AI 绘画软件,Stable Diffusion 是支持使用 CPU 或 GPU 来完成 AI 绘画。而在 AI 绘画中,RTX4090 展现出它在目前消费级显卡中最强的 AIGC 性能,处理速度要比次顶级的 RTX 4080 强上约 30%,相较于 RTX3090 Ti 也有接近 2 倍的性能提升。
说到 AI 绘画,也顺便提一下前面已经说过的 NVIDIA DLSS(深度学习超级采样)。DLSS 是一种神经图形技术,它使用 AI 来提高性能,创建全新的帧,通过图像重建显示更高分辨率,并提高密集光线追踪内容的图像质量,同时提供最佳的一流的图像质量和响应能力,其实这也是一种 AIGC。DLSS 在部分游戏中已经支持,如今一些创作软件也有利用 DLSS 技术来做加速。这对 GPU 的性能要求很高,即使是上一代最强的 RTX3090 Ti 都难以实现,但新一代 RTX 40 系显卡的 DLSS 3 技术加入帧生成技术,使得单张显卡也都可以进行一些中轻度的创作。
深度学习推理
在大模型的训练阶段,RTX4090 是不行的。为什么这么说呢?RTX4090 虽然算力强,性价比也高,但是不支持 NVLink,这就成为了 RTX4090 不能成为大模型训练的主要原因。当然,相较于 A100 40GB、80GB 的大显存,RTX4090 只有 24GB 的显存,也显得相对弱了不少。于大模型训练而言,A100 相较于 RTX4090,并不是因为单卡性能强了多少,而是在于拓展性、服务、显存这些方面的优势。
RTX4090 不适用于大模型训练,为什么却可以用于深度学习推理呢?我们来了解下推理和训练有什么区别。
深度学习推理是指在已经完成训练的深度学习模型上进行实际应用和预测的过程。在深度学习中,模型的训练阶段是为了调整模型的参数和权重,以使其能够准确地对训练数据进行分类、预测或生成。一旦深度学习模型完成训练,它就可以用于推理阶段,即对新的输入数据进行处理和预测。
在训练阶段,GPU 不仅需要存储模型参数,还需要存储梯度、优化器状态、正向传播每一层的中间状态(activation)。训练任务是一个整体,流水线并行的正向传播中间结果是需要存下来给反向传播用的。为了节约内存而使用流水线并行,流水级越多,要存储的中间状态也就更多。
而在推理阶段,模型将接收输入数据,并通过前向传播算法计算输出结果。这个过程不涉及参数的更新或反向传播的计算,而是利用模型已经学到的知识来进行预测。推理任务中的各个输入数据之间并没有关系,因此流水线并行不需要存储很多中间状态。
0 元体验 RTX4090
在了解 RTX4090 的强大后,你可能在为没办法体验到它而感到遗憾。那么我偷偷告诉你,又拍云联合厚德云推出 RTX4090 GPU,新用户完成注册即可 0 元体验。你只要完成下面 3 个步骤即可:
1. 创建厚德云账号并完成实名认证;
2. 领取体验金
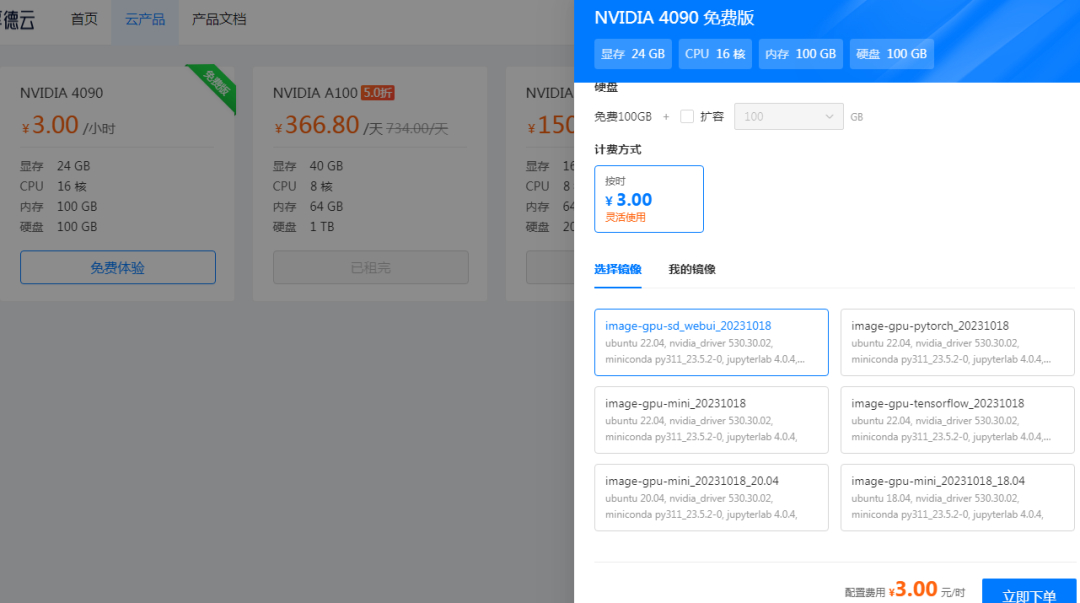
登录厚德云后在 GPU 中选择 NVIDIA 4090,点击免费体验,按步骤领取体验金即可。
3. 开启体验之旅
领取体验金后即可创建 4090 云主机,点击免费体验,选择镜像,镜像根据需要进行选择,比如“image-gpu-sd_webui_20231018”已经预装了 stable Diffusion,然后点击立即下单即可,体验金会抵扣掉下单金额哦。
下单后等待创建,显示运行中就可以使用啦。