正则表达式又称规则表达式(Regular Expression,在代码中常简写为 regex、regexp 或 RE),是一种用于匹配、查找、替换文本的强大工具。它能够以特定的模式匹配字符串,从而实现自动化文本处理。在许多编程语言中,正则表达式都被广泛用于文本处理、数据分析、网页抓取等领域。通过正则表达式,我们可以精确地筛选、操作和格式化文本,提高工作效率。
正则表达式在日常生活中有着广泛的应用。比如,在处理电话号码时,我们可以使用正则表达式来验证号码的格式是否正确。中国的电话号码通常由 11 位数字组成,第一位为 1,第二位通常为 3-9,我们可以使用以下正则表达式来匹配这些号码:
/^1[3-9]\d{9}$/
通过这个正则表达式,我们可以判断一个电话号码是否符合规范,从而避免出现错误的信息输入。
什么是正则表达式
每个正则表达式都有一个有限自动机(也称为状态机),它接受表达式指定的语言,并使用 Thompson 构造算法将正则表达式转化为一个与之等价的非确定有限状态自动机(NFA)。同时,对于每个有限自动机来说,还有一个描述该自动机所接受语言的正则表达式。该表达式可以通过克莱恩算法或高斯消元法生成。
正则表达式的一个著名应用是文本编辑器中的搜索和替换功能,计算机先驱 Ken Thompson(UNIX 操作系统的开发者之一)首先在 20 世纪 60 年代的面向行编辑器 QED 中实现了该功能。此函数允许查找文本中的特定字符串,并根据需要将其替换为任何其他字符串。
正则表达式如何工作
正则表达式可以仅使用正则字符(例如 abc),也可以使用正则字符和元字符的组合(例如 ab*c)。元字符的任务是描述某些字符的结构或排列,例如字符是否应位于行的开头,或者字符是否只出现一次或多次出现。上面提到的正则表达式示例的工作原理如下:
- abc:简单的正则表达式模式 abc 需要完全匹配。换句话说,该表达式以精确的顺序搜索包含字符“abc”的所有字符串。例如可以匹配到:“a abc d”及“abc oulomb”。
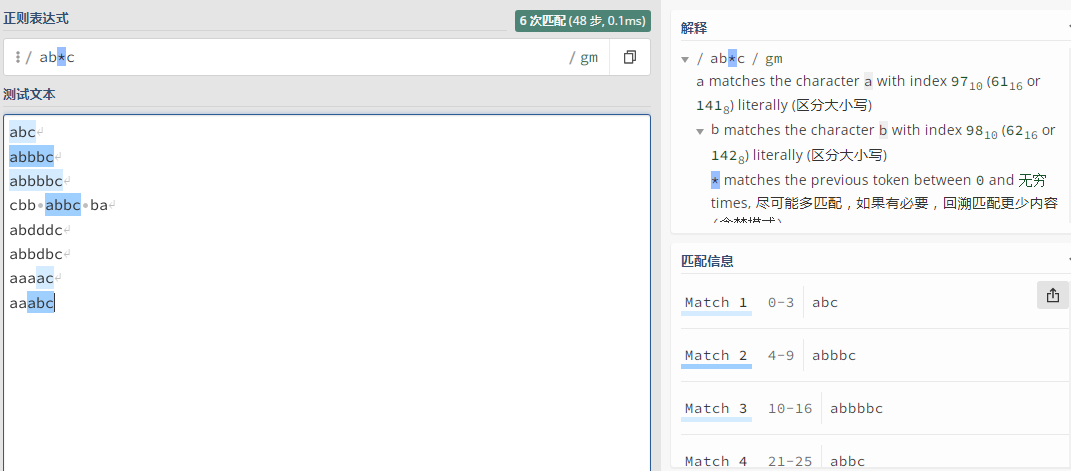
- ab*c:相比之下,具有特殊字符的正则表达式略有不同。星号代表表达式搜索以字母“a”开头并以字母“c”结尾的字符串。但是,a 和 c 之间可以有任意数量的 b。所以,“abc”以及字符串“abbbbc”和“cbb abbc ba”也构成了匹配。
每个正则表达式还可以链接到特定的操作,例如上面提到的“替换”操作。只要正则表达式为真,即只要存在上面示例中所述的匹配项,就会执行此操作。又拍云 CDN 的边缘规则中就支持类似场景,根据正则表达式匹配字符串,执行改写、跳转、访问控制、限速等需求。

使用正则表达式的挑战
掌握正则表达式可以提高我们编程和文本处理的能力,更加高效地处理大量数据和文本。然而,掌握和使用还是存在着一些挑战。
- 复杂性:正则表达式本身较为复杂,学习曲线陡峭,编写和理解复杂的正则表达式可能需要大量的时间和经验。
- 匹配效率:不合理的正则表达式可能导致效率低下,特别是在处理大量数据时。
- 不可读性:复杂的正则表达式可能难以理解,使得维护和调试变得困难。
- 学习成本:正则表达式的语法和特殊字符较多,需要一定的学习才能熟练使用。
编写正则表达式时,最重要的是掌握以下几个核心概念:
- 元字符:包括字符、反斜杠、方括号、星号、问号等,它们用于匹配特定的字符或字符集。
- 转义字符:使用反斜杠对特殊字符进行转义,以便匹配这些字符本身而不是其特殊含义。
- 限定符:用于指定正则表达式中前一个字符或子表达式出现的次数。例如,* 表示零次或多次,+ 表示一次或多次,? 表示零次或一次。
- 选择符:使用管道符号(|)表示可以选择多个模式中的任何一个进行匹配。
- 原子:用于指定一个精确的字符或字符集,例如 \d 表示数字字符,\w 表示字母、数字或下划线字符。
- 断言:用于指定一个位置而不是具体的字符或字符集,例如 ^ 表示行首,$ 表示行尾。
- 括号:用于将多个模式组合成一个更复杂的模式,并指定匹配的顺序。
掌握了这些核心概念,就能够编写更准确、更复杂的正则表达式,以解决各种文本处理问题。
哪些语法规则适用正则表达式
正则表达式可以在多种语言中使用,例如 Perl、Python、Ruby、JavaScript、XML 或 HTML,但它们的用途或功能可能有很大不同。如在 JavaScript 中,正则表达式模式用于 search()、match() 或 replace() 字符串方法,而 XML 文档中的表达式用于分隔元素内容。不过就语法而言,在编程语言或标记语言中使用几乎没有任何区别。
正则表达式可以由三个部分组成,无论使用哪种语言:
| Patterns(表达式) | 由元字符、普通字符和特殊字符组成,用于描述要匹配的文本模式。该模式可以仅由简单字符组成,也可以由简单字符和特殊字符的组合组成。 |
|---|---|
| Delimiters(分隔符) | 用于将正则表达式与其他文本区分开来。常用的分隔符是斜杠(/),但也可以使用其他字符作为分隔符。 |
| Modifiers(修饰符) | 用于指定正则表达式的行为。常见的修饰符包括 i(忽略大小写)、m(多行模式)、s(将点号匹配任何字符,包括换行符)和 x(忽略空白字符)。 |
以下是用于表达式中的一些典型语法符号及注释:
| 正则表达式语法的特殊字符 | 功能 |
|---|---|
| [] | 用于指定一个字符集,即可以匹配方括号内的任意一个字符。字符集可以包含单个字符、多个字符、字符范围等。 |
| () | 一个捕获组,用于将一组字符或模式捕获并保存起来,以便后续使用或匹配。捕获组可以用于提取子字符串、进行替换操作等。 |
| - | 一个连字符,用于表示范围或指定范围。它可以用于字符集或重复次数的修饰符中。 |
| ^ | 在字符集中,^ 用于否定字符集;在断言中,^ 用于表示行的开头。 |
| $ | 用于匹配字符串的结尾。 |
| . | 匹配任意字符的元字符。可以匹配除了换行符(\n、\r)之外的任何字符。 |
| * | 是一个限定符,用于指定前一个字符或子表达式出现的次数。它可以表示零次或多次。 |
| + | 是一个限定符,用于指定前一个字符或子表达式出现的次数。它可以表示一次或多次。 |
| ? | 是一个限定符,用于指定前一个字符或子表达式出现的次数。它可以表示零次或一次。 |
| {n} | 是一个限定符,用于指定前一个字符或子表达式出现的次数。它表示前面的字符或子表达式必须精确出现 n 次。 |
| {n,m} | 是一个限定符,用于指定前一个字符或子表达式出现的次数范围。其中,n 表示最小次数,m 表示最大次数。 |
| {n,} | 是一个限定符,用于指定前一个字符或子表达式出现的次数范围,表示至少出现 n 次。 |
| \b | 是一个边界断言符,用于指定一个单词的边界。它匹配一个单词的开头或结尾,即前后都是非单词字符(如空格、标点符号等)的位置。 |
| \B | 是一个边界断言符,与 \b 相反。它匹配一个单词内部的位置,即前后都是单词字符的位置。 |
| \d | 是一个字符类,用于匹配任意十进制数字。等价于 [0-9]。 |
| \D | 是一个否定断言符,用于匹配非数字字符。它是一个反向匹配符,用于与数字字符进行区分。 |
| \w | 是一个元字符,用于匹配一个单词字符。单词字符包括字母、数字和下划线 [a-zA-Z_0-9]。 |
| \W | 是一个反向字符断言符,用于匹配非字母数字字符。 |
当然,上面只是介绍了正则表达式的一些基础知识。正则表达式具有很高的灵活性和可塑性,从简单的文本编辑器到复杂的开发工具,都可以使用正则表达式进行文本处理。之前也提到了,又拍云 CDN 的边缘规则功能就运用到了正则表达式提取字符串,下面通过一些例子来了解一下它的强大之处。
正则表达式在又拍云 CDN 的应用
示例一:目录及参数改写
将请求 URL 转换为带参数的动态 URL,例如请求的 URL 为:
http://example.com/pay/25/8/...
需要 CDN 边缘节点转换为如下请求:
http://example.com/pay.php?payid=25&categoryid=8...
这个时候,pattern 部分需要提取目录数字,需要生成 $1 和 $2 这样的变量,如下规则所示:
"rule": "/pay.php?productid=$1&categoryid=$2",
"pattern": "^pay/([0-9]+)/([0-9]+)/(.*?).html$"
规则释义:当解析的 url 符合规则 ^pay/([0-9]+)/([0-9]+)/(.*?).html$,那么将请求导向到 /pay.php?productid=$1&categoryid=$2。
也即将 http://example.com/pay/25/8/... 转换为 http://example.com/pay.php?payid=25&categoryid=8...
示例二:文件名改写
pattern: /(.*)/playlist.m3u8$rule: /$1'.m3u8'
规则释义:当访问地址为http://domain/app/stream/playlist.m3u8http://domain/app/stream.m3u8.时,将访问地址改写为
应用场景:在直播应用场景中,因为客户端机制无法或者不方便升级的情况,可以通过 URL 改写,将 /stream/playlist.m3u8 改为 /stream.m3u8,其中 app 代表发布点,stream 代表流名。
示例三:URL 限速
假如请求的 URL 为:http://test.example.com/mp4/4E10F356C0FEAD359C33DC5901307461-10.mp4 ,需要对该类型文件进行限速,限速要求为:前 20MB 不限速,20MB 之后限速 800 KB/s,规则可这样编写:
"rule": "$WHEN($1, $EQ($_HOST, 'test.example.com'))$LIMIT_RATE_AFTER(20, m)$LIMIT_RATE(800, k)",
"pattern": "^(/).+-10.mp4$"
规则释义:当 $1 为真,且满足请求 HOST 为 test.example.com 时,开始 20MB 不限速,后面限制到 800KB/s。
又拍云 CDN 边缘规则功能结合正则表达式,搭配处理操作,可以帮助您简化内容分发业务逻辑,并提升终端用户访问体验。该规则可以快速部署且配置简单,可极大降低业务实现成本。网站及 Web 应用开发者或者安全工程师可以快速创建边缘规则集来提升网站安全及分发性能。具体可以查看文档:https://help.upyun.com/docs/edgerules/
最后,我来推荐一个好用的正则表达式匹配测试工具:https://regex101.com/, 可以快速测试哪些字符串能匹配规则,搭配规则详解,对于编写和测试超级方便。