Ruby Web 的摩斯密码,Base64 介绍
本来写在 JWT 介绍
但好像太长了,拆出来分享
因为看到 ruby3 的 release note 裡特别有讲把 base64 放上 rubygems.org
https://github.com/ruby/base64
也让我想到好像至今没有真的了解 base64 在做什麽...。
就是每次处理非纯文字的资料时,
都是把档案转成 base64 的字串表示。
比如在 rails 上传图片时,图片在 params 中就是 base64 的形式,
而且另个疑问是,为什麽要称那些资料为 Binary data 呢?
预设你已了解 bit 跟 byte 还有字的编码如 ASCII,读起来较易理解
参考资料
当然是 Wiki Base64 - Wikipedia
base64
base64 可以想成「用 64 种字元」去代表所有的资料的一种方式
因为电脑其实只认 0 跟 1
所以资料不论是何种类型,到最后一定会变成是 0 跟 1 的组合。例如:
- 数字 6 会转成二进位的 110
- 字元 A 是 100 0001(因为 ASCII 裡 A=65,而 65 的二进位是 100 0001)
- 字串是字元连起来的,所以是一长串的 01 组合
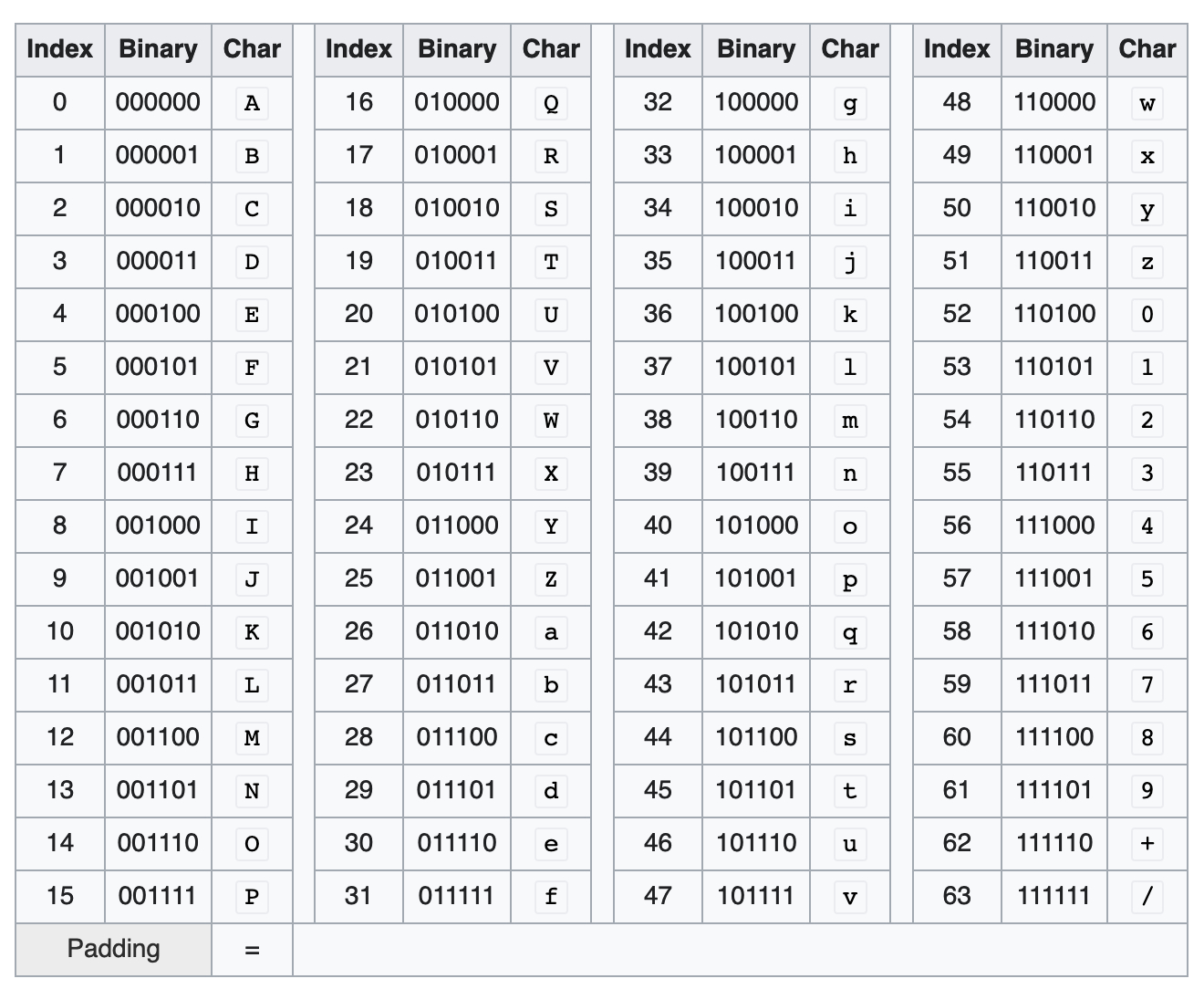
base64 是把 01 这种二进位的资料,以 6 个为一组呈现的方式
任 6 位数 2 进位,如 000 001, 001 101
总共会有 64 种组合,所以命名为 base64
给每种组合一个代表的「字元 Char」,
就可以用那 64 种字元去代表所有的字串了,
(如果 bits 数不能被 6 整除,会用 = 去代替)
下表是 wiki 上列出这 64 个字元:
以 Wiki 页 上的例子 Man 这个字串来说,
ASCII 是用 8 bits 存的,所以 共有 24 bits
转成 base64:
- M 是 010011 01, 前面 6 bit 010011 依上表 是
T,然后剩 2 bit01 - a 是 0110 0001,前面的 4 bit 配上 M 后 2 bit, 010110 是
W - 依续做可得
TWFu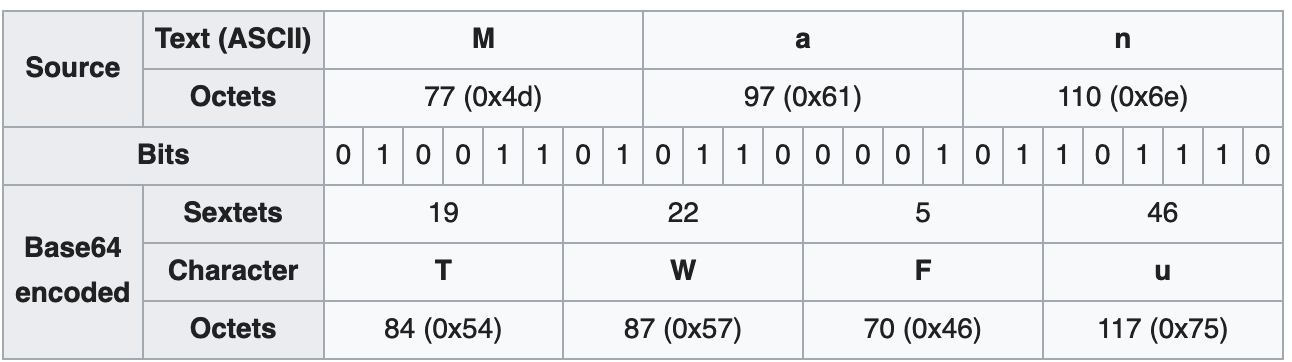
我们可以用这个方式拆解中文我试看看:
'我'.unpack("B*")[0] # 将 String 转二进位
# "111001101000100010010001"
我刚好是 3 个 byte 也就是 24bits 所以用 base64 恰好是 4 个字元显示

实际操作看看:
require 'base64'
puts Base64.encode64('我')
# 5oiR
# 注意decode base64时,它不知道那是 utf-8 所以要自己转回去
Base64.decode64('5oiR')
# "\xE6\x88\x91"
Base64.decode64('5oiR').encoding
# #<Encoding:ASCII-8BIT>
Base64.decode64('5oiR').force_encoding('UTF-8')
# "我"
而那些根本不是任何「文字」的档案,比如说图片、音乐、影片,
根本不能转成文字,但依然可以以 0 跟 1 表示,
可以写成超长的011010101010....的字串,
就称它们为 Binary data。
在传送档案时,就可以用 base64 去表示任何档案,
又因为 base64 转回来时只是一般的 ASCII,所以才为什麽一定要加註
Content-Type 或副档名。
Q&A
base64 最终还不是会换为 0 与 1,为什麽不直接传 01 就好了?
主要原因还是希望传输的内容人易看懂,即使 base64 是不可读的,但英数真的比较容易分辨 2 串字一不一样
感谢网友指正,因为某些通讯协定或资料格式直接规定讯息内不能放 binary data,比如最常拿来举例的就是 email 格式的 MIME,直接规定只允许 ASCII 的字元。那图片跟其它附加档案都是 binary data 怎麽办?用 base64 即可将 binary data 转成 ASCII 并附在 email 的讯息中。
另外 stackoverflow 上的解釋也十分值晶參考,
避免不同系统对不同的编码解读不同。
如用 base64 传输资料,即使两边系统解读不同,
至少可以同意「资料本身」是两边一致的,
以 Stackoverflow 上的例子来说,传两行的讯息时:
Hello
world!
ASCII 的编码是长
72 101 108 108 111 10 119 111 114 108 100 33
那个换行符号 10, 在不同的作业系统解读是不一样的 如果用 base64
SGVsbG8Kd29ybGQh
一样都是 ASCII,但都是较「安全」的,也就是所有系统都一致的
83 71 86 115 98 71 56 75 100 50 57 121 98 71 81 104
不过这则留言还是满好笑的 xD
问题留言有一位 Martin 回 We use base64 because it's more readable than Perl 笑死 xD
为何不干脆来个 base128, base256? 不是能变更短
这问题也非常有意思,我也这样想过
encoding - Why is base128 not used? - Stack Overflow
因为 base64 的字元其实是从 ASCII 选的,为了所有电脑都能显示,
从上面的程式码例子也知道 decode 完预设是 ASCII 的编码。
ASCII 裡剩下的都是控制码了,换行 \n 或让电脑叫一声那种。
希望有帮助到大家理解喔