Ruby 测试性能优化建议
这是一篇关于测试性能优化的文章,主要分享笔者近期对测试进行优化的一些心得。原文链接:https://www.lanzhiheng.com/posts/suggestion-of-test-optimization
之前一篇关于测试的文章写到笔者在公司的项目中“强推”测试驱动的开发模式,首次尝到了测试驱动的甜头。不过也带来了一些问题,由于笔者对各种测试工具的理解不够深入,遗留下了不少会导致性能问题的测试代码,导致跑全面测试的时候耗费时间过长,本篇文章作为优化指南,简单谈谈我的测试优化策略。
成果
花了一些时间来做测试优化还是值得的,以下是优化之前的测试结果。(注:笔者所用的测试机器是非 M1 芯片的新款 Macbook Pro2020,8 核 8G)
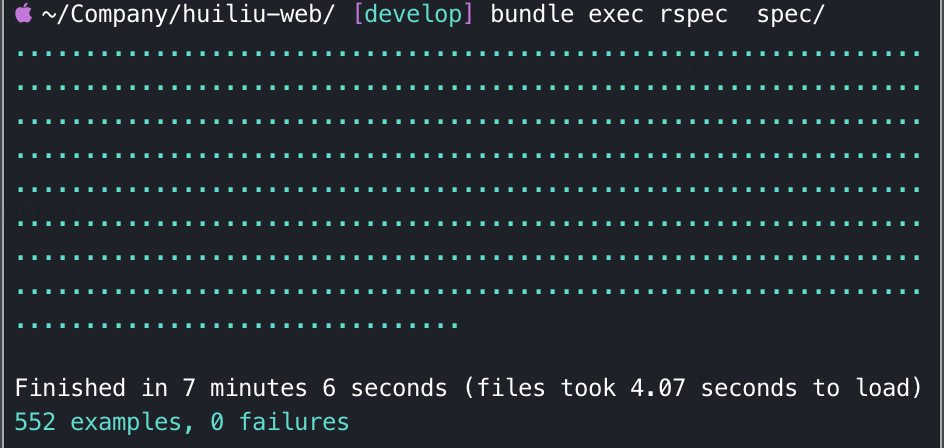
而下面是我昨天的测试结果

大概有 780 个用例吧,耗时 2 分 40 秒左右。由于业务的推进,最新的测试用例会比原来多 200 个,时间却缩减了 5 分钟左右,也算是有点长进了。
现在的版本在 CircleCI 上面跑完整个 CI 流程大概需要 4-5 分钟,如果是之前的版本估计的十多分钟吧。十多分钟去跑一个 CI,怎么想都难以接受(4-5 分钟勉强能忍,但还需要继续优化)。不过这都是之前代码写得太烂导致的,接下来我会分享一些我在项目中犯过的低级错误,以及我缩减测试时间的一些准则,能做好这些说不定你的测试效率也能有所提高。
更深度优化笔者也还没做过,以后做了再分享出来。
优化手段
1. 找出影响性能那 20% 的用例
一个老生常谈的结论,80/20 定律。其实用在测试里面也是成立的,往往导致性能瓶颈的都是 20% 的测试用例,把它们找出来,优化掉,所带来的收益比无脑地去跟剩下的 80% 的代码死磕要高得多。笔者使用的测试工具是RSpec,它提供了一个很方便的测试性能分析器,让我们可以找出用例群里面最慢的测试用例,比如我要找出所有用例里面最慢的 30 条测试,可以在命令后面加上-p 30,或者--profile 30
bundle exec rspec -p 30
整体跑完测试之后就能得到一个类似这样的列表,建议把这个结果保存下来,毕竟在优化之前像这样整体跑一次测试还是挺花时间的。

可见,有很多耗时 5-10 秒之间的用例。一个用例要是耗时那么长时间是很不正常的。想想要是有几个耗时十几秒的用例,就会生生占去一分钟的时间。如果能花点心思把这些个用例给优化掉,说不定就能省下一分钟的时间了。耗时那么长时间一般可能就是数据构造得太多,导致占用的时间太长,或者是测试依赖网络,网络较慢的时候也会导致测试迟缓。接下来都会分别谈谈这些场景要如何优化,不过优化的前提依然是先把那些性能低下的用例给找出来,盲目去翻代码其实是下下策。
2. let 很好,但是要注意陷阱
笔者有很多有性能问题的测试都是因为let语句使用不规范导致的。let 语句很棒,真的,不过如果对她的功效没有理解好,那可能会写出性能低下的测试,let语句最常规的用法是构造数据并赋值。
describe 'test group' do
let(:hello) do
'hello'
end
it 'example1' do
expect(hello).to eq('hello')
end
end
这很爽,然而let的代码块在每个用例开始的时候都会调用一次,效用跟before钩子函数差不多,也就是说
describe 'test group' do
let(:hello) do
puts 'create data'
'hello'
end
it 'example1' do
expect(hello).to eq('hello')
end
it 'example2' do
expect(hello).to eq('hello')
end
end
运行结果为
> rspec test.rb
call me
.call me
.
设想一下如果我们在一个测试组里面使用let语句来构造数组数据
describe 'list test group' do
let(:list) { create_list(:user, 100) }
it 'xxx1' do
end
it 'xxx2' do
end
it 'xxx3' do
end
...
end
这种情况下你有几个it带头的测试用例,let语句就会调用几次,也就是说会创建n * 100条数据,而且单从代码的布局来看还以为是只创建了一次然后在不同用例之间共享。笔者最开始写测试的时候就不自觉地留下了一些这样的代码,导致每个用例耗时都好几秒,把这些优化掉就能节省不少时间。更好的做法应该是
describe 'better list test group' do
before(:context) do
@list = create_list(:user, 100)
end
let(:list) { @list }
it 'xxx' do
end
end
这样无论有几个用例,数据都只构造了一次。不过为了避免数据污染,采用这种方式要记得手动去销毁数据
describe 'better list test group' do
....
after(:context) do
@list.each(&:destroy)
end
end
当然我们不会想每次都手动去销毁数据,后面我会介绍更好的数据管理方案。一般let滥用都容易导致性能问题,先用前面提到的性能分析器把这些用例找出来吧,一步一步地去优化他们。
减少对数据库的访问
无论我们代码写得再精妙,我们的测试始终都依赖于数据库。而再好的数据库在面对大量数据写入的时候都难免需要耗费点时间。就像前面提到的例子
describe 'list test group' do
let(:list) { create_list(:user, 100) }
...
end
这一下子就创建了 100 条数据,测试又怎能不慢。况且再配合上let的滥用,那简直就是测试代码的毒瘤。虽然现今机器资源都相对比较廉价,但也经不住这般折腾,毕竟这也会延长 CI 的时间,降低开发间的协作效率。其实如果要测试普通的列表功能,一般 3-5 条数据都足够了。
describe 'list test group' do
let(:list) { create_list(:user, 3) }
...
end
减少了构造数据,哪怕贪方便偶尔“滥用”一下let语句来构造列表,其实也不会造成特别严重的负面影响。
事务策略
在 Rails 项目中大多数的测试用例都需要从数据库中构造数据,这会带来一个问题,就是我某一个用例构造的测试如果没有及时删除的话它会遗留在数据库中,并且会对接下来的数据产生影响
require 'rails_helper'
describe 'test group' do
before do
@user = create(:user)
end
it 'hello1' do
expect(User.count).to eq(1) # passed
end
it 'hello2' do
expect(User.count).to eq(2)
# Failure/Error: expect(User.count).to eq(2)
# expected: 2
# got: 1
end
end
这种情景肯定不是我们想要的。如果要得到洁净的数据表则要手动去after { User.destroy_all },当然我们也懒得做这种事情。rails-helper提供了事务策略,只要这样去配置一下
RSpec.configure do |config|
config.use_transactional_fixtures = true
end
那么上面的代码就不用做任何调整,两个用例都能够通过,它利用了数据库的事务特性,每个测试用例都会包裹在事务当中,等到用例完结之后,期间所做的所有数据改动都会被回滚,我们就能够得到一个相对洁净的测试环境了。
不过这种方法有个不太方便的地方,就是它只能把单个的用例包裹进事务中去,并不能针对用例的组创建事务,像这种
describe 'first test group' do
before(:context) do
@user = create_list(:user, 10)
end
it 'check users' do
expect(User.count).to eq(10) # => passed
end
end
describe 'second test group' do
it 'check users' do
expect(User.count).to eq(0)
# Failure/Error: expect(User.count).to eq(0) # => passed
# expected: 0
# got: 10
end
end
你如果第一个测试组里面的数据不手动去清除,那遗留下来的数据势必会对后面的测试造成影响。如果能把测试组包裹进事务里面就好了,然而官方文档没有给出这种做法。它可能倾向于让我们针对每个用例构造数据吧?然而如果针对列表数据,我可能更倾向于在测试组的最开始构建一次,数据组内共享,最终再一次性删除。
1. Database Cleaner 一个很不错的测试辅助工具
先介绍一个很好的数据清理工具database_cleaner,RSpec 的官方文档也有提到它。它为我们提供了更为方便的数据管理手段。我们可以针对不同的场景,用不同的策略来删除已有的测试数据。在对的场景采用对的策略有助于减少测试的时间。并且这个 Gem 让我们可以自己来设定数据清理的区域
DatabaseCleaner.strategy = :transaction
DatabaseCleaner.start # usually this is called in setup of a test
dirty_the_db
DatabaseCleaner.clean # cleanup of the test
上面代码的意思是,采用 database_cleaner 的事务策略 (transaction),然后开启事务清理区域DatabaseCleaner.start,在这个区域内的所有数据改动都会在调用DatabaseCleaner.clean的时候删除。比如我这里选择的删除策略是transaction,那么它就会通过事务回滚的方式来删除数据。针对 ActiveRecord,它还可以用deletion以及truncation两种策略。
应该还比较好理解,由于这个 Gem 本身就有事务功能,会跟前面提到的用例事务有冲突,所以使用之前都需要先关闭原厂的用例事务配置
RSpec.configure do |config|
config.use_transactional_fixtures = false
end
2. 配置简介
以下是我集成了DatabaseCleaner之后的配置
RSpec.configure do |config|
config.before(:suite) do
DatabaseCleaner[:active_record].clean_with(:deletion)
DatabaseCleaner[:redis].strategy = :deletion
DatabaseCleaner[:redis].db = 'redis://localhost:6379/1'
end
config.before(:all, :cleaner_for_context) do
DatabaseCleaner[:active_record].strategy = :truncation
DatabaseCleaner.start
end
config.before(:each) do |example|
next if example.metadata[:cleaner_for_context]
DatabaseCleaner[:active_record].strategy = :transaction
DatabaseCleaner.start
end
config.after(:each) do |example|
next if example.metadata[:cleaner_for_context]
DatabaseCleaner.clean
end
config.after(:all, :cleaner_for_context) do
DatabaseCleaner.clean
end
end
这里其实很好地利用了 RSpec 的元数据机制。首先看看那两个包含each的配置。先不管其中的元数据检测部分,其实它运用到真实场景里就是
describe 'xxxx' do
before do
DatabaseCleaner[:active_record].strategy = :transaction
DatabaseCleaner.start
end
it 'xxx' {}
after do
DatabaseCleaner.clean
end
end
在每个测试用例启动的时候,它首先会设置一个数据清理的策略transaction,并开启数据清理区域(根据策略这里是事务区域),等到实例完结的时候就对事务进行回滚。它的作用其实就几乎等同于前面提到的config.use_transactional_fixtures = true这个配置,每个测试用例都包裹在事务里面,完成之后进行回退。只不过我们现在已经用了database_cleaner,就索性用它来完成类似的事情,原厂的事务机制就可以关闭掉了config.use_transactional_fixtures = false。
接下来看看包含all的配置,其实all可以替换成context,两者是等价的。只要在分组里面设置了元数据cleaner_for_context,它就会把测试组包括在测试清理区域内。运用到实际场景是这样的
describe 'xxxx' do
before(:context) do
DatabaseCleaner[:active_record].strategy = :truncation
DatabaseCleaner.start
end
it 'xxx' {}
after(:context) do
DatabaseCleaner.clean
end
end
这里需要注意一下,清理块本身并不支持嵌套。因此,如果不排除掉测试用例自身的清理语句,那当其中的用例完结并调用自身的DatabaseCleaner.clean就会把组内的共享数据都清理掉,导致测试紊乱。这也是为什么在each的配置函数一开始会加一个
...
next if example.metadata[:cleaner_for_context]
可以这样应用
describe 'xxxx', :cleaner_for_context do
before(:context) do
@users = create_list(:user, 10)
end
let(:users) { @users }
let(:fake) { create(:user) }
it 'xxx' {}
it 'xxx' {}
end
这意味着告诉组内的所有测试用例,数据由测试组统一来管理,不用你们管了,你们只需要安心地构造数据即可。详情可以参考一下How to: Get most of the database cleaner。这种一般在针对列表的测试中会用得稍微多一些。一般我要测试列表都是在测试组一开始就构造好列表数据,然后组内的所有用例则共享这些数据,运行到测试组的最末尾则统一删除掉这些数据。
另外还需要注意一下这里的数据清理策略我使用了truncation而不是transaction,两者的区别在于一个是直接把表“截断”,另一个是事务回退。所谓表截断其实就是
simple=# select COUNT(*) from test ;
count
-------
3
(1 row)
simple=# TRUNCATE test;
TRUNCATE TABLE
simple=# select COUNT(*) from test ;
count
-------
0
(1 row)
如果你数据库中有很多数据,相比于用DELETE语句一条条去删除,还不如把表直接删掉,然后重建要来的快一些,这也是TRUNCATION语句的功效(笔者这里用了truncation策略,后面发现其实deletion策略会更快一些,于是也换成deletion了,可能因为本身构造的数据不算太多吧)。其实如果条件允许的话用transation策略进行整体回滚是最好的,不过对于我们这些有多个数据库连接的场景要用好事务似乎有点难,可以参考一下What Strategy Is Fastest,我也尝试过针对组采用事务回滚,虽然会快不少 (20-30s 左右),但是偶尔会出现一些莫名其妙的错误,于是就先用那两个比较简单的策略先了。
最后看看针对套件的钩子
RSpec.configure do |config|
...
config.before(:suite) do
DatabaseCleaner[:active_record].clean_with(:deletion)
DatabaseCleaner[:redis].strategy = :deletion
DatabaseCleaner[:redis].db = 'redis://localhost:6379/1'
end
end
这个钩子函数会在测试刚开始的时候运行,主要是用于设置一些针对全局的配置。比如 redis 的删除数据策略,还有测试一开始就采用deletion策略来清空 ActiveRecord 相关数据表中的数据(因为我们每个用例,或者用例组都会用事务或者删除的方式来清理数据,所以上一次测试完结后遗留下来的数据不会很多,这里用deletion进行数据清理的话会比用truncation重建表要高效一些)。
笔者的测试里面会依赖 redis,而每个测试用例或者测试组完结的时候都会调用DatabaseCleaner.clean清理数据表,这个过程也会清理 redis 的数据。它目前似乎也只有deletion一个策略。
活用工具及数据库本身的特性让我们能够快速构建出测试用例所需要的“洁净室”,同时也能降低测试的维护成本。当然如果规划能力一流,最高效的做法肯定还是一开始就把数据构建好,剩下的时间跑测试就行,然而笔者并没有这种规划能力,我相信市面上大多数程序员都不具备这种能力,细想一下还是按需去构造数据比较适合我们这些人。
规避网络请求
经过一番的努力笔者总算把测试用例里面几乎所有超过 1s 的测试用例都优化掉了,耗时也大幅减少。不过还有一个问题,就是有些测试用例的耗时并不稳定,有些时候几毫秒就完结了,而有的时候则需要 5-10s 才能完成。笔者曾经一度以为是数据库访问太频繁导致的,后来发现并非如此,毕竟每次都是这几个用例会出现严重的延迟问题。
最后发现这些偶尔会慢的测试跟网络有关(感谢办公环境那不稳定的网络)。正是由于那些业务逻辑依赖了第三方的接口,测试这些业务的时候也不得不发送网络请求。从而在网络不佳的时候会拖慢整个测试流程。
解决方案很简单,一般这些第三方的接口都会有相应的文档,文档里面会描述接口返回的结果(成功时候会有哪些字段,失败的时候会有哪些字段)。接下来我们可以用 RSpec 提供的Mock技术,来 hack 我们代码对第三方接口的封装,借此还能够测试不同的场景。我拿姜军主导的wx_pay来举例,安装了这个 Gem 后他提供的统一下单接口是WxPay::Service.invoke_unifiedorder正常来说我不希望我的测试代码会调用到它,因为它真的会触发网络请求。这个时候我可以
def hack_method
WxPay::Service.invoke_unifiedorder(1, 2)
end
describe 'wx pay' do
it 'mock unifiedorder' do
mock = class_double('WxPay::Service').as_stubbed_const(:transfer_nested_constants => true)
expect(mock).to receive(:invoke_unifiedorder).with(1, 2) { { return_code: 'SUCCESS' } }
expect(hack_method).to match({ return_code: 'SUCCESS' })
end
end
这样在hack_method方法被调用的时候就不会真的发请求去微信那边,并且还能模拟微信的返回结果,有助于测试不同场景下的业务逻辑。
笔者现在的项目会依赖微信,快递 100 等等这些第三方服务,当调用依赖这些服务的接口时,测试用例有时候会变得莫名其妙的慢(5s-10s)。优化掉之后基本上 100ms-500ms 就能完成。要找出这些漏网之鱼最好的办法就是在断网的情况下本地运行你的测试,基本上那些卡住很久的用例就是它们的所在地。
以下策略会有点用,但是效果可能不会很明显
提升日志等级
正常情况下我们测试日志的所采用的日志等级是很低的
irb(main):001:0> Rails.logger.level
=> 0
这种情况下,所有对数据库的操作语句都会被写入到日志里面,文件的读写量会相对较大,然而往往我们压根就不会去看这个日志,建议可以把日志等级调高
irb(main):002:0> Rails.logger.level = :error
=> :error
irb(main):003:0> Rails.logger.level
=> 3
这样只有异常信息才会写入到日志文件中去。具体可以参考一下Three Tips To Improve The Performance Of Your Test Suite。
扩张数据库连接池
default: &default
adapter: postgresql
encoding: unicode
# For details on connection pooling, see Rails configuration guide
# https://guides.rubyonrails.org/configuring.html#database-pooling
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
test:
<<: *default
database: huiliu_web_test
pool: 10
测试用例有些时候会堵住,但一般来说感觉不会特别明显。你可以尝试把pool改成 1,那么有些涉及到请求的测试会卡死,因为连接被占用无法释放,请求进不去。把这个连接池稍微扩大一点或许有点用吧,不过请求不多的时候应该是感觉不出来了,因为一些用例也会释放掉自己手上的连接,不一定会用到储备池里面的。
尾声
这篇文章简单分享了一下自己在对项目的测试进行优化后的经验总结,虽然对比于 Ruby China 的homeland 项目测试效率还是有不少的差距(它大概一分钟以内能跑完 500 个测试吧),不过对比与之前的版本已经有不少的提升了,接下来还会继续进行优化。希望能帮助到那些初入测试坑的朋友,少犯点低级错误,测试用例能节省下不少的时间资源。
参考资料
- Three tips to improve the performance of your test suite: http://blog.plataformatec.com.br/2011/12/three-tips-to-improve-the-performance-of-your-test-suite/
- Rspec 官方文档:https://rspec.info/
- Database Cleaner: https://github.com/DatabaseCleaner/database_cleaner
- How to: Get most of the database cleaner: https://devopsvoyage.com/2018/09/26/get-most-of-the-database-cleaner.html

 搞进去了。需要点时间才能深度使用。东西有点多 ruby-prof stackprof。层级有点深啊,哈哈哈哈。。。
搞进去了。需要点时间才能深度使用。东西有点多 ruby-prof stackprof。层级有点深啊,哈哈哈哈。。。