分享 图数据库 Nebula Graph 在 Boss 直聘的应用

本文首发于 Nebula Graph 官方博客:https://nebula-graph.com.cn/posts/nebula-graph-risk-control-boss-zhipin/
摘要:在本文中,BOSS 直聘大数据开发工程师主要分享一些他们内部的技术指标和选型,以及很多小伙伴感兴趣的 Dgraph 对比使用经验。
业务背景
在 Boss 直聘的安全风控技术中,需要用到大规模图存储和挖掘计算,之前主要基于自建的高可用 Neo4j 集群来保障相关应用,而在实时行为分析方面,需要一个支持日增 10 亿关系的图数据库,Neo4j 无法满足应用需求。
针对这个场景,前期我们主要使用 Dgraph,踩过很多坑并和 Dgraph 团队连线会议,在使用 Dgraph 半年后最终还是选择了更贴合我们需求的 Nebula Graph。具体的对比 Benchmark 已经有很多团队在论坛分享了,这里就不再赘述,主要分享一些技术指标和选型,以及很多小伙伴感兴趣的 Dgraph 对比使用经验。
技术指标
硬件
配置如下:
- 处理器:Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz 80(cores)
- 内存:DDR4,128G
- 存储:1.8T SSD
- 网络:万兆
Nebula Graph 部署 5 个节点,按官方建议 3 个 metad / 5 个 graphd / 5 个 storaged
软件
- Nebula Graph 版本:V1.1.0
- 操作系统:CentOS Linux release 7.3.1611 (Core)
配置
主要调整的配置和 storage 相关
# 按照文档建议,配置内存的 3 分之 1
--rocksdb_block_cache=40960
# 参数配置减小内存使用
--enable_partitioned_index_filter=true
--max_edge_returned_per_vertex=100000
指标
目前安全行为图保存 3 个月行为,近 500 亿边,10 分钟聚合写入一次,日均写入点 3,000 万,日均写入边 5.5 亿,插入延时 <=20 ms。
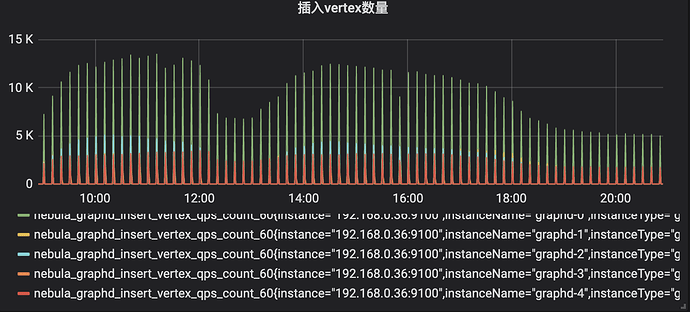
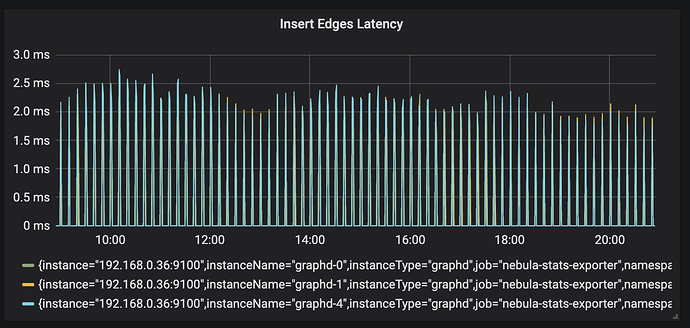
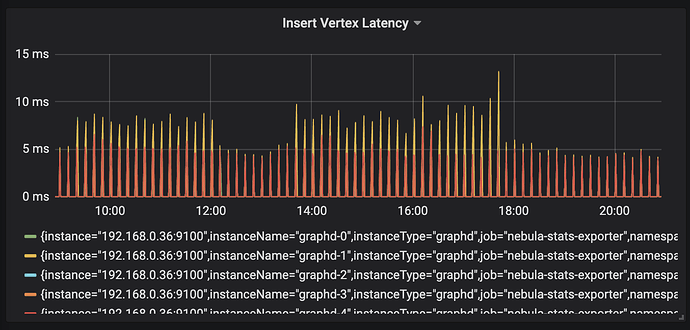
读延时 <= 100 ms,业务侧接口读延时 <= 200 ms,部分超大请求 < 1 s
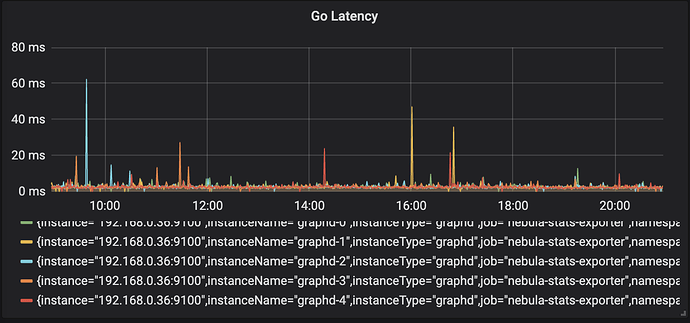
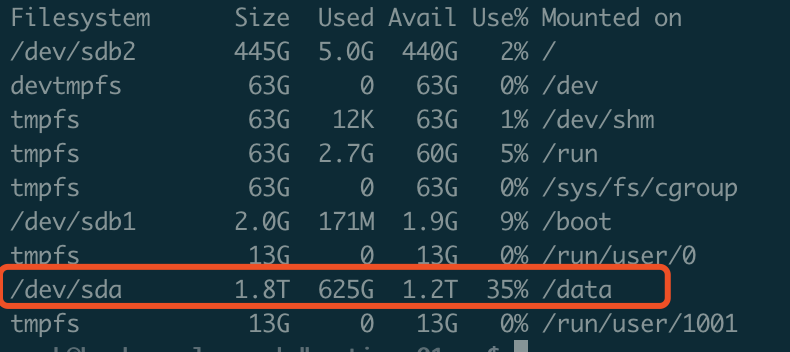
当前磁盘空间占用 600G * 5 左右
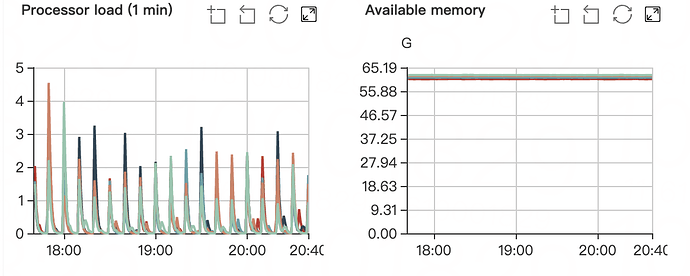
CPU 耗用 500% 左右,内存使用稳定在 60 G 左右
Dgraph 使用对比
目前来说原生分布式图数据库国内选型主要比对 Dgraph 和 Nebula Graph,前者我们使用半年,整体使用对比如下,这些都是我们踩过坑的地方。
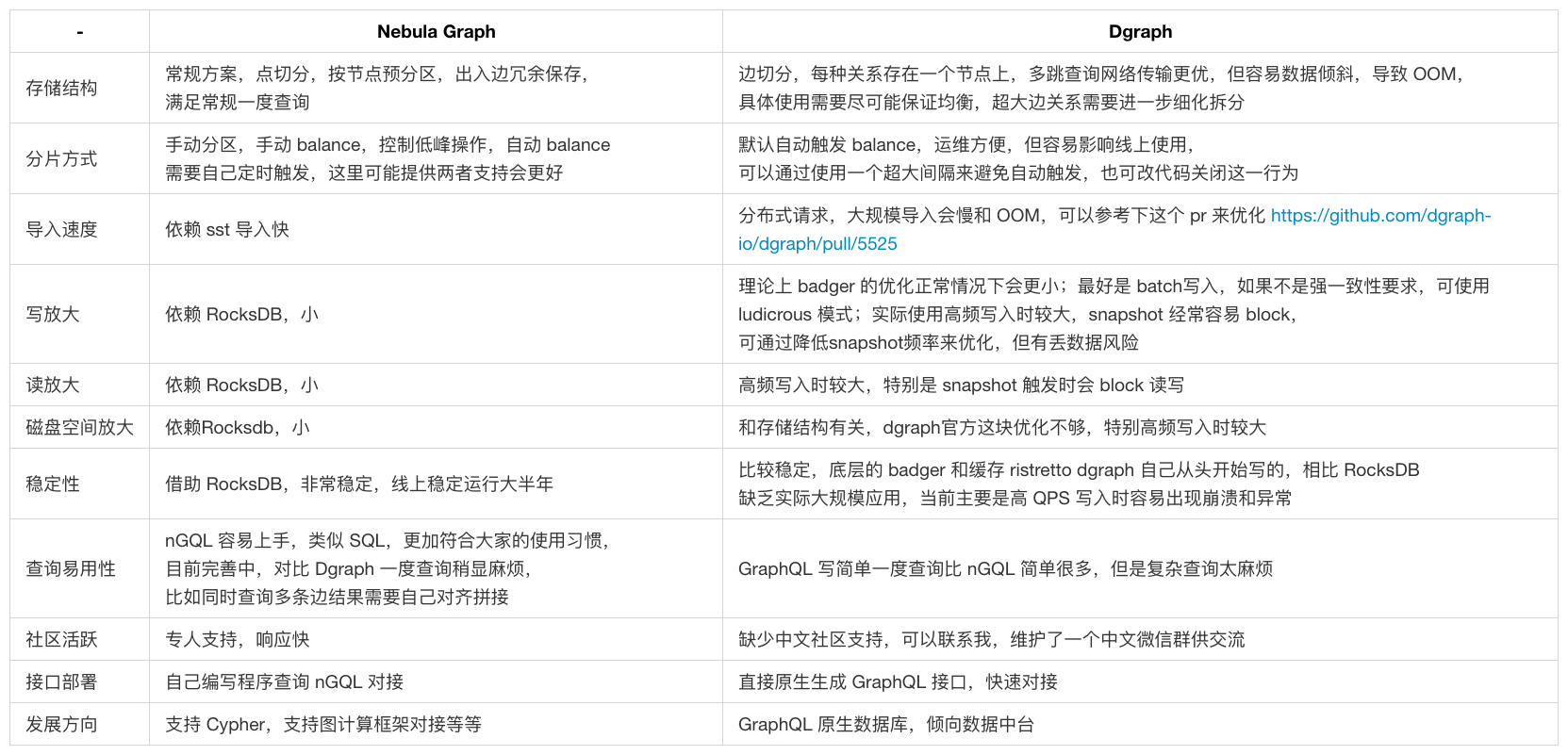
就我们使用经验,Dgraph 设计理念很好,但是目前还不太满足我们业务需求,GraphQL 的原生支持还是有很大吸引力,但是存储结构决定容易 OOM(边存储也分组的话会优化很多,官方之前计划优化);另外,采用自己编写的 badger 和 ristretto,目前最大的问题是从官方释放的使用案例来看,未经大规模数据场景验证,在我们实际使用中,大数据量和高 QPS 写入场景下容易出现崩溃和 OOM,且如果采用 SSD 存储海量数据,Dgraph 的磁盘放大和内存占用也需要优化。
如果没有高 QPS 写入,目前 Dgraph 还是值得一试,对于很多快速原型的场景,作为 GraphQL 原生图数据库使其非常适合做基于图的数据中台,这是目前的一个大趋势,它也上线了自己的云服务,业内标杆 TigerGraph 也在做相关探索,另外事务的完善支持也是它的优势,这块暂时用不到,所以没做相关评测。实测 Dgraph 在线写入并发不高或只是离线导入数据使用的情况下还是很稳定的,如果想借助它的高可用和事务功能,可以尝试下。
对比来说,Nebula Graph 很优秀,特别是工程化方面,体现在很多细节,可以看出开发团队在实际使用和实现上做较了较好的平衡:
- 1.支持手动控制数据平衡时机,自动固然很好,但是容易导致很多问题
- 2.控制内存占用(enable_partitioned_index_filter 优化和设置单次最大返回边数目),都放在内存固然快,但有时候也需要考虑数据量和性能的平衡
- 3.多图物理隔离,多张图实在太有必要
- 4.nGQL 最大程度接近最常用 MySQL 语句,2 期兼容 Cypher 更加完美;对比 GraphQL 固然香,但写起复杂图查询真的让人想爆炸,可能还是更加适合做数据中台查询语言
- 5.和图计算框架的结合,最近释放的 Spark GraphX 结合算法非常有用,原先我们的图计算都是基于 GraphX 从 Neo4j 抽取后离线计算团伙,后续打算尝试 Nebula Graph 抽取
这里主要从实际经验对比分享,二者都在持续优化,都在快速迭代,建议使用前多看看最新版本 release 说明。
建议
当前 Nebula Graph 做得很优秀,结合我们现在的需求也提一点点建议:
- 1.更多离线算法,包括:现有的图神经网络这块的支持,图在线查询多用在分析,真正线上应用目前很多还是图计算离线算完后入库供查询
- 2.Plato 框架的合并支持,Spark GraphX 相对计算效率还是低一些,如果能整合腾讯的 Plato 框架更好
- 3.借鉴 TigerGraph 和 Dgraph,支持固化 nGQL 查询语句直接生成服务 REST 端点,HTTP 传入参数即可查询,这样可快速生成数据查询接口,不用后台再单独连接数据库写 SQL 提供数据服务
目前 Boss 直聘将 Nebula Graph 图数据库应用在安全业务,相关应用已经线上稳定运行大半年,本文分享了一点经验,抛砖引玉,期望更多技术伙伴来挖掘 Nebula 这座宝库。
Dgraph 遇到的一些问题,供有需要小伙伴参考
参考文章
本文系 Boss 直聘·安全技术中心 文洲 撰写