云服务 腾讯云 CHDFS — 云端大数据存算分离的基石
随着网络性能提升,云端计算架构逐步向存算分离转变,AWS Aurora 率先在数据库领域实现了这个转变,大数据计算领域也迅速朝此方向演化。
存算分离在云端有明显优势,不但可以充分发挥弹性计算的灵活,同时集中的托管存储可以提供更大的容量和更低的成本,避免了云端大量自建存储集群的维护代价。
一、问题和挑战
对象存储是广泛使用的云端非结构化数据存储解决方案,越来越多的非结构化数据聚集于对象存储的数据湖中,随之而来的是对这些海量数据的分析需求。
然而对大数据分析的存储系统来说,HDFS 接口是事实标准,HDFS 是大数据生态的存储基石。
原生的对象存储接口不兼容 HDFS,无法直接使用。为支持计算存储分离的大数据场景,对象存储通常提供了一个模拟层,实现 HDFS 语义到对象存储语义的转换,典型实现类似 s3n 和 cosn。然而这类实现缺乏对真正的文件系统接口的支持,基于对象存储的扁平目录结构无法实现分层命名空间,在处理类似 rename 等操作时效率极低(实际是基于前缀复制关联的所有对象),对于 list、head 等频繁元数据操作的场景延迟较高,一些对象存储系统还缺少强一致性语义,不能保证写后读一致性,导致上层的大数据计算框架出错。
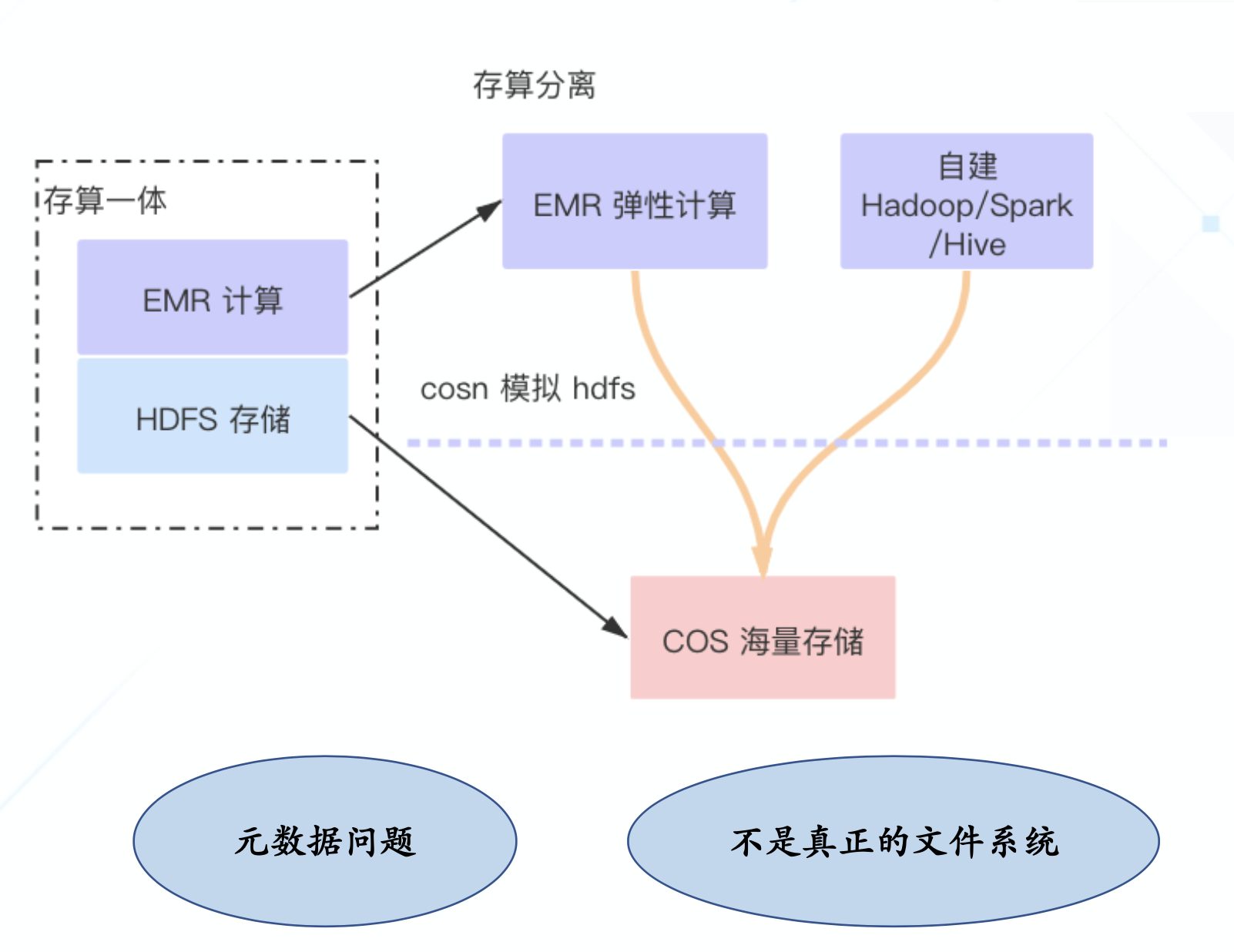
同时在数据流方面,诸如常见的文件 append 操作,s3n 和 cosn 等对象存储的模拟层也无法支持。
为支持大数据存算分离场景,需要重新设计云端存储系统,该系统可以为云端大数据计算提供高效可靠的存储基石,在实现无限存储的同时,重点满足对元数据的需求。
为此,我们提出了一种基于对象存储的通用分布式文件系统设计方案:cloud native hdfs,简称 CHDFS。
二、CHDFS 整体介绍
CHDFS 整体架构如图所示。
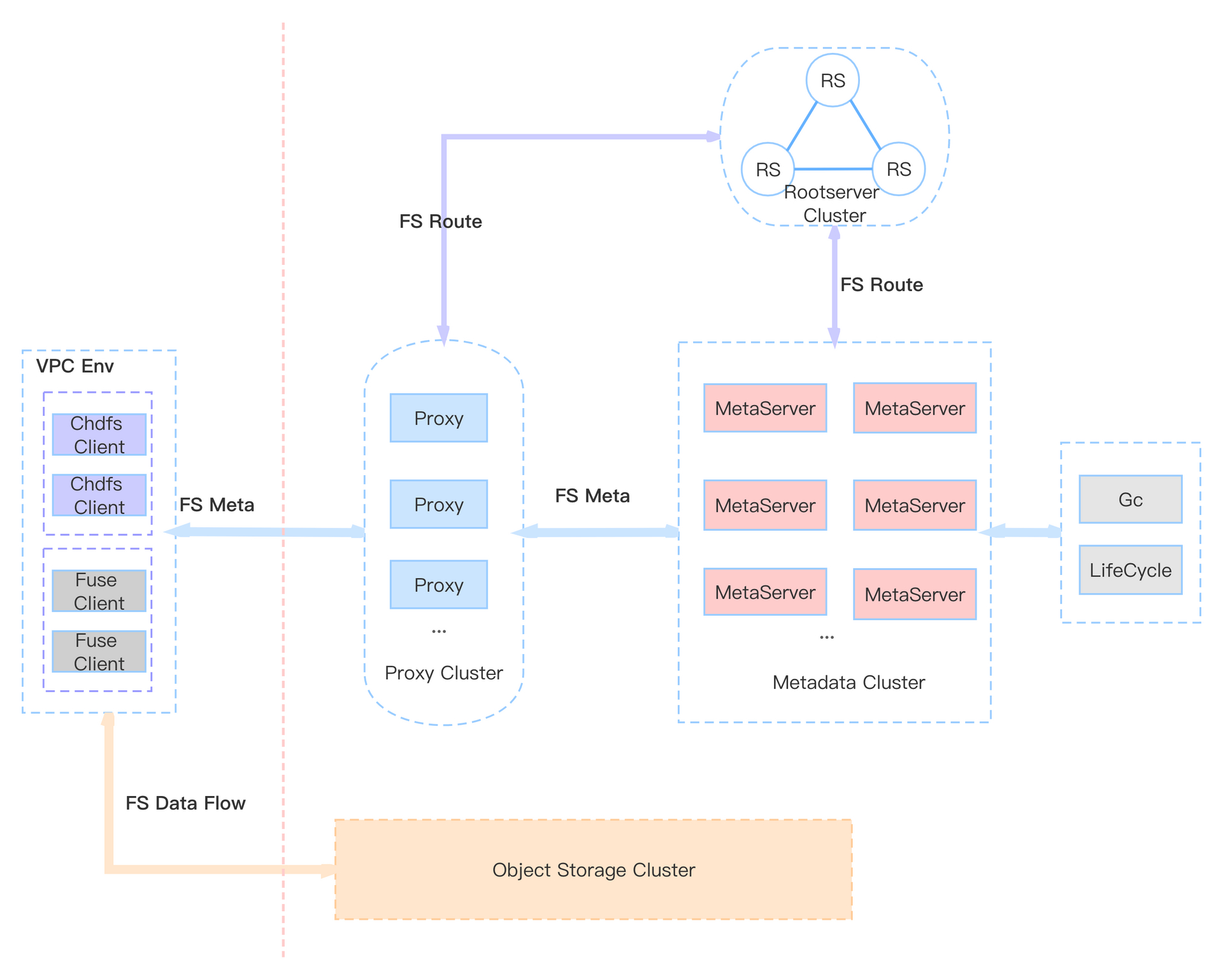
CHDFS,在对象存储之上,充分发挥云端优势,构建可扩展的 metadata 层,实现对 HDFS 语义的支持。通过高度优化的 metadata 层,可以支持海量元数据的高效访问。在元数据规模远超 HDFS 的情况下,达到接近原生 HDFS 性能的效果。同时提供优化了读写数据流的 java 客户端,在支持高效元数据操作的同时,充分发挥了对象存储高吞吐和低成本的优点。
CHDFS 基于对象存储实现文件系统语义,数据托管给对象存储,把对象存储当做磁盘使用,在此基础上构建文件系统分布式元数据层,支持海量数据。基于对象存储托管数据,可以自动获得对象存储的优势,如低成本,高可靠,大吞吐,高可用等特性,容量可达到百 PB 级别。
三、CHDFS 元数据服务特点
CHDFS 元数据服务采用分布式架构,在元数据读写方面做了较多优化,支持百亿级别的文件数据量,突破了 hdfs namenode 规模限制,同时保证了严格的强一致语义。
对比 COS 和 HDFS,具有以下特点:
1、毫秒级别的原子 rename 操作,对目录和文件都适用;
2、元数据强一致,写入后立即可见;
3、支持百亿级别的文件数量,远超 HDFS 规模,延迟和 HDFS 相当;
4、单文件系统,元数据支持 10w 以上的 qps,满足大规模计算的高并发需求;
5、高可用,秒级的 ha 切换时间;
6、元数据并行加载,冷启动速度 比 HDFS 快 1 个数量级;
7、元数据跨区域/可用区复制,进一步提高可靠性;
CHDFS 提供了多种元数据引擎,在面临不同的应用场景时,用户可以有多种选择,达到成本、容量和性能的平衡。
在接口上,CHDFS 完全兼容 HDFS,可以轻松在两个系统之间迁移数据。
四、COS 为 CHDFS 提供数据底座
对象存储 COS 作为云端基础存储服务,为 CHDFS 提供了坚实的数据底座,CHDFS 的文件数据分块后存储在 COS,具有以下优点:
1、海量存储,支持百 P 级别的数据量,容量自动扩展;
2、超大带宽,支持 Tbps 级别的带宽,大数据计算可以充分发挥 COS 高吞吐的优势;
3、数据多 AZ,带来了 11 个 9 的超高可靠性;
4、数据存储默认 EC 编码,成本更低;
5、支持文件数据跨区域复制;
6、智能分层支持,根据数据的冷热程度,自动分层,进一步降低存储成本;
同时,CHDFS 提供了高性能的 HDFS 兼容的 java sdk,针对大数据场景做了全面优化,实现了高效的读写缓存机制,可以充分发挥 COS 在数据流方面的优势。
五、丰富的产品功能
除了上述提到的强大的文件读写能力外,CHDFS 还提供了丰富的产品功能,来满足大数据场景下客户的多样需求。
对于关注成本优化的客户,CHDFS 提供了存储生命周期管理功能,能够通过简单的配置页面,让客户的文件自动沉降到成本更低的存储介质,进一步降低客户使用云端存储的成本,真真正正的帮助客户省钱。当客户需要访问这部分沉降的冷数据时,CHDFS 提供了功能强大、方便易用的命令行工具,使文件回到热存储层供客户使用。
对于有存储内容感知需求的客户,CHDFS 提供了强大的文件清单功能,可以按照客户指定的文件格式及过滤字段,离线导出文件信息,并且投递到客户的文件系统中。客户可以通过读取该清单文件,进行多维度的业务文件属性分析,如文件平均大小分布等。甚至还可以作为客户从本地 HDFS 导入 CHDFS 过程中的一种文件校验手段。
六、生态整合
CHDFS 提供了完全兼容 HDFS 的协议,可以无缝支持常见的大数据计算框架,如 Hive,Spark,Presto,Flink 等。
CHDFS 目前已经和腾讯云 EMR 产品紧密集合。客户购买 CHDFS 产品后,无需安装任何环境,即可直接在腾讯云 EMR 上使用 CHDFS 产品,进一步简化客户使用 CHDFS 的上手成本。