分享 主流开源分布式图数据库 Benchmark
本文由美团 NLP 团队高辰、赵登昌撰写 首发于 Nebula Graph 官方论坛:https://discuss.nebula-graph.com.cn/t/topic/1377

1. 前言
近年来,深度学习和知识图谱技术发展迅速,相比于深度学习的“黑盒子”,知识图谱具有很强的可解释性,在搜索推荐、智能助理、金融风控等场景中有着广泛的应用。美团基于积累的海量业务数据,结合使用场景进行充分地挖掘关联,逐步建立起包括美食图谱、旅游图谱、商品图谱在内的近十个领域知识图谱,并在多业务场景落地,助力本地生活服务的智能化。
为了高效存储并检索图谱数据,相比传统关系型数据库,选择图数据库作为存储引擎,在多跳查询上具有明显的性能优势。当前业界知名的图数据库产品有数十款,选型一款能够满足美团实际业务需求的图数据库产品,是建设图存储和图学习平台的基础。我们结合业务现状,制定了选型的基本条件:
-
开源项目,对商业应用友好
- 拥有对源代码的控制力,才能保证数据安全和服务可用性。
-
支持集群模式,具备存储和计算的横向扩展能力
- 美团图谱业务数据量可以达到千亿以上点边总数,吞吐量可达到数万 qps,单节点部署无法满足存储需求。
-
能够服务 OLTP 场景,具备毫秒级多跳查询能力
- 美团搜索场景下,为确保用户搜索体验,各链路的超时时间具有严格限制,不能接受秒级以上的查询响应时间。
-
具备批量导入数据能力
- 图谱数据一般存储在 Hive 等数据仓库中。必须有快速将数据导入到图存储的手段,服务的时效性才能得到保证。
我们试用了 DB-Engines 网站上排名前 30 的图数据库产品,发现多数知名的图数据库开源版本只支持单节点,不能横向扩展存储,无法满足大规模图谱数据的存储需求,例如:Neo4j、ArangoDB、Virtuoso、TigerGraph、RedisGraph。经过调研比较,最终纳入评测范围的产品为:NebulaGraph(原阿里巴巴团队创业开发)、Dgraph(原 Google 团队创业开发)、HugeGraph(百度团队开发)。
2. 测试概要
2.1 硬件配置
- 数据库实例:运行在不同物理机上的 Docker 容器。
- 单实例资源:32 核心,64GB 内存,1TB SSD 存储。【Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz】
- 实例数量:3
2.2 部署方案
Metad 负责管理集群元数据,Graphd 负责执行查询,Storaged 负责数据分片存储。存储后端采用 RocksDB。
| 实例 1 | 实例 2 | 实例 3 |
|---|---|---|
| Metad | Metad | Metad |
| Graphd | Graphd | Graphd |
| Storaged[RocksDB] | Storaged[RocksDB] | Storaged[RocksDB] |
Zero 负责管理集群元数据,Alpha 负责执行查询和存储。存储后端为 Dgraph 自有实现。
| 实例 1 | 实例 2 | 实例 3 |
|---|---|---|
| Zero | Zero | Zero |
| Alpha | Alpha | Alpha |
HugeServer 负责管理集群元数据和查询。HugeGraph 虽然支持 RocksDB 后端,但不支持 RocksDB 后端的集群部署,因此存储后端采用 HBase。
| 实例 1 | 实例 2 | 实例 3 |
|---|---|---|
| HugeServer[HBase] | HugeServer[HBase] | HugeServer[HBase] |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| RegionServer | RegionServer | RegionServer |
| ZooKeeper | ZooKeeper | ZooKeeper |
| NameNode | NameNode[Backup] | - |
| - | ResourceManager | ResourceManager[Backup] |
| HBase Master | HBase Master[Backup] | - |
3. 评测数据集
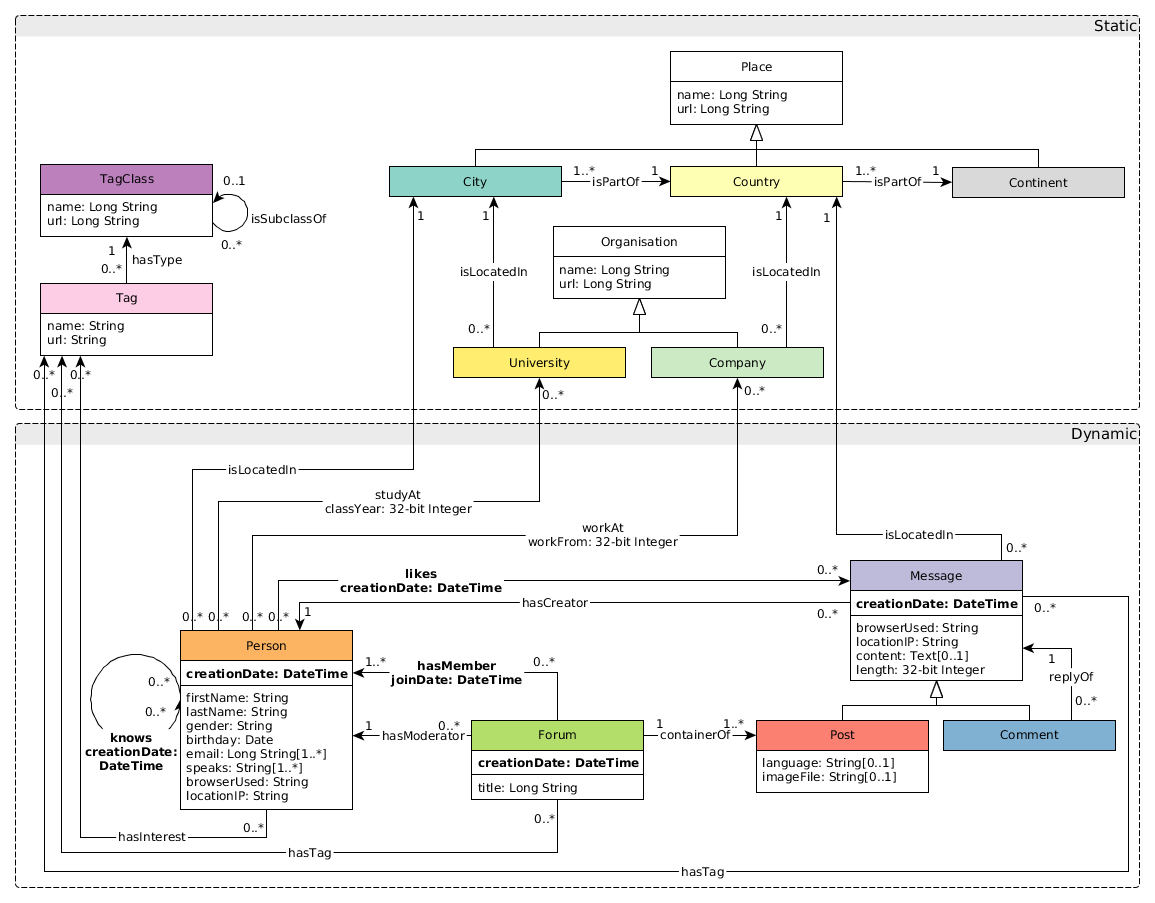
- 社交图谱数据集:https://github.com/ldbc011
- 生成参数:branch=stable, version=0.3.3, scale=1000
- 实体情况:4 类实体,总数 26 亿
- 关系情况:19 类关系,总数 177 亿
- 数据格式:csv
- GZip 压缩后大小:194 G
4. 测试结果
4.1 批量数据导入
4.1.1 测试说明
批量导入的步骤为:Hive 仓库底层 csv 文件 -> 图数据库支持的中间文件 -> 图数据库。各图数据库具体导入方式如下:
- Nebula:执行 Spark 任务,从数仓生成 RocksDB 的底层存储 sst 文件,然后执行 sst Ingest 操作插入数据。
- Dgraph:执行 Spark 任务,从数仓生成三元组 rdf 文件,然后执行 bulk load 操作直接生成各节点的持久化文件。
- HugeGraph:支持直接从数仓的 csv 文件导入数据,因此不需要数仓 - 中间文件的步骤。通过 loader 批量插入数据。
4.1.2 测试结果
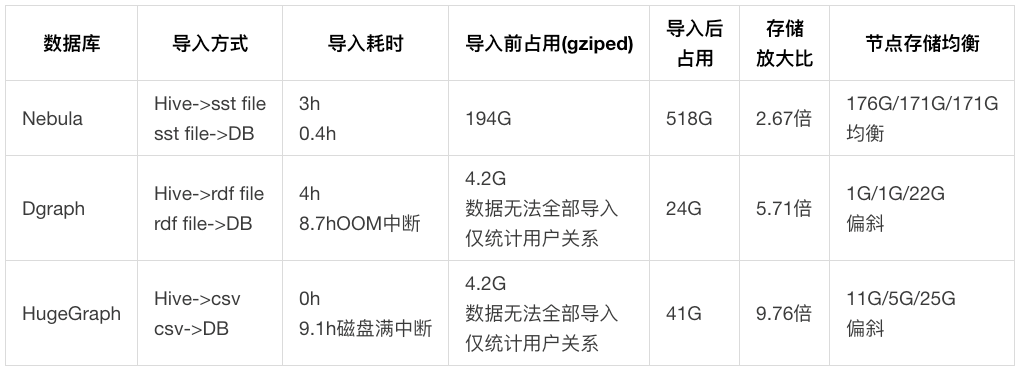
4.1.3 数据分析
- Nebula:数据存储分布方式是主键哈希,各节点存储分布基本均衡。导入速度最快,存储放大比最优。
- Dgraph:原始 194G 数据在内存 392G 的机器上执行导入命令,8.7h 后 OOM 退出,无法导入全量数据。数据存储分布方式是三元组谓词,同一种关系只能保存在一个数据节点上,导致存储和计算严重偏斜。
- HugeGraph:原始 194G 的数据执行导入命令,写满了一个节点 1,000G 的磁盘,造成导入失败,无法导入全量数据。存储放大比最差,同时存在严重的数据偏斜。
4.2 实时数据写入
4.2.1 测试说明
- 向图数据库插入点和边,测试实时写入和并发能力。
- 响应时间:固定的 50,000 条数据,以固定 qps 发出写请求,全部发送完毕即结束。取客户端从发出请求到收到响应的 Avg、p99、p999 耗时。
- 最大吞吐量:固定的 1,000,000 条数据,以递增 qps 发出写请求,Query 循环使用。取 1 分钟内成功请求的峰值 qps 为最大吞吐量。
- 插入点
- Nebula
INSERT VERTEX t_rich_node (creation_date, first_name, last_name, gender, birthday, location_ip, browser_used) VALUES ${mid}:('2012-07-18T01:16:17.119+0000', 'Rodrigo', 'Silva', 'female', '1984-10-11', '84.194.222.86', 'Firefox')
- Dgraph
{
set {
<${mid}> <creation_date> "2012-07-18T01:16:17.119+0000" .
<${mid}> <first_name> "Rodrigo" .
<${mid}> <last_name> "Silva" .
<${mid}> <gender> "female" .
<${mid}> <birthday> "1984-10-11" .
<${mid}> <location_ip> "84.194.222.86" .
<${mid}> <browser_used> "Firefox" .
}
}
- HugeGraph
g.addVertex(T.label, "t_rich_node", T.id, ${mid}, "creation_date", "2012-07-18T01:16:17.119+0000", "first_name", "Rodrigo", "last_name", "Silva", "gender", "female", "birthday", "1984-10-11", "location_ip", "84.194.222.86", "browser_used", "Firefox")
- 插入边
- Nebula
INSERT EDGE t_edge () VALUES ${mid1}->${mid2}:();
- Dgraph
{
set {
<${mid1}> <link> <${mid2}> .
}
}
- HugeGraph
g.V(${mid1}).as('src').V(${mid2}).addE('t_edge').from('src')
4.2.2 测试结果
- 实时写入
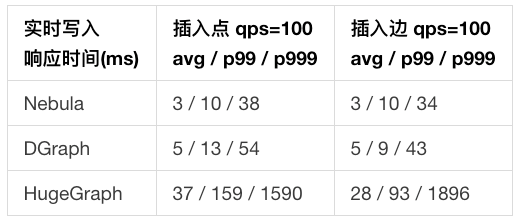
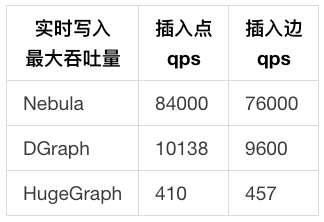
4.2.3 数据分析
- Nebula:如 4.1.3 节分析所述,Nebula 的写入请求可以由多个存储节点分担,因此响应时间和吞吐量均大幅领先。
- Dgraph:如 4.1.3 节分析所述,同一种关系只能保存在一个数据节点上,吞吐量较差。
- HugeGraph:由于存储后端基于 HBase,实时并发读写能力低于 RocksDB(Nebula)和 BadgerDB(Dgraph),因此性能最差。
4.3 数据查询
4.3.1 测试说明
- 以常见的 N 跳查询返回 ID,N 跳查询返回属性,共同好友查询请求测试图数据库的读性能。
- 响应时间:固定的 50,000 条查询,以固定 qps 发出读请求,全部发送完毕即结束。取客户端从发出请求到收到响应的 Avg、p99、p999 耗时。
- 60s 内未返回结果为超时。
- 最大吞吐量:固定的 1,000,000 条查询,以递增 qps 发出读请求,Query 循环使用。取 1 分钟内成功请求的峰值 qps 为最大吞吐量。
- 缓存配置:参与测试的图数据库都具备读缓存机制,默认打开。每次测试前均重启服务清空缓存。
- N 跳查询返回 ID
- Nebula
GO ${n} STEPS FROM ${mid} OVER person_knows_person
- Dgraph
{
q(func:uid(${mid})) {
uid
person_knows_person { #${n}跳数 = 嵌套层数
uid
}
}
}
- HugeGraph
g.V(${mid}).out().id() #${n}跳数 = out()链长度
- N 跳查询返回属性
- Nebula
GO ${n} STEPS FROM ${mid} OVER person_knows_person YIELDperson_knows_person.creation_date, $$.person.first_name, $$.person.last_name, $$.person.gender, $$.person.birthday, $$.person.location_ip, $$.person.browser_used
- Dgraph
{
q(func:uid(${mid})) {
uid first_name last_name gender birthday location_ip browser_used
person_knows_person { #${n}跳数 = 嵌套层数
uid first_name last_name gender birthday location_ip browser_used
}
}
}
- HugeGraph
g.V(${mid}).out() #${n}跳数 = out()链长度
- 共同好友查询语句
- Nebula
GO FROM ${mid1} OVER person_knows_person INTERSECT GO FROM ${mid2} OVER person_knows_person
- Dgraph
{
var(func: uid(${mid1})) {
person_knows_person {
M1 as uid
}
}
var(func: uid(${mid2})) {
person_knows_person {
M2 as uid
}
}
in_common(func: uid(M1)) @filter(uid(M2)){
uid
}
}
- HugeGraph
g.V(${mid1}).out().id().aggregate('x').V(${mid2}).out().id().where(within('x')).dedup()
4.3.2 测试结果
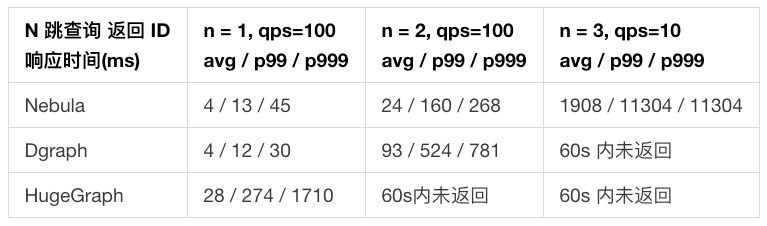
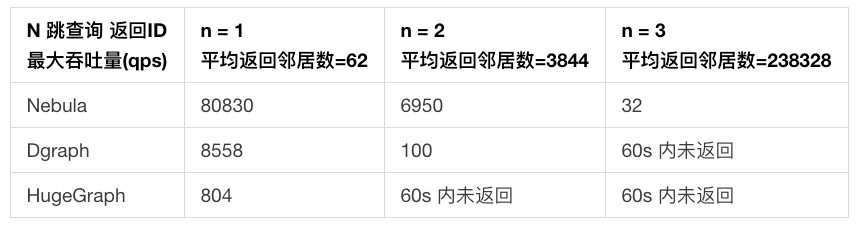
- N 跳查询返回 ID
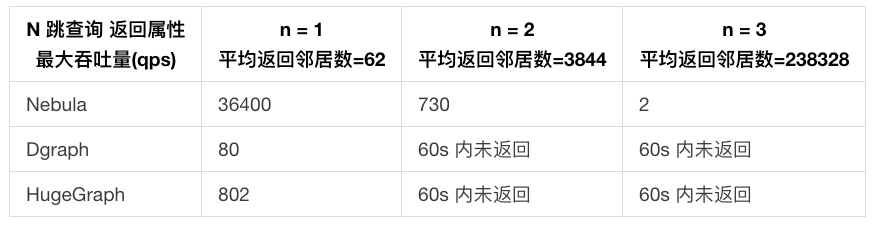
- N 跳查询返回属性
单个返回节点的属性平均大小为 200 Bytes。

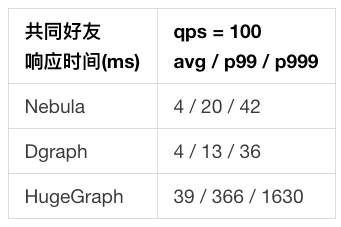
- 共同好友 本项未测试最大吞吐量。
4.3.3 数据分析
- 在 1 跳查询返回 ID「响应时间」实验中,Nebula 和 DGraph 都只需要进行一次出边搜索。由于 DGraph 的存储特性,相同关系存储在单个节点,1 跳查询不需要网络通信。而 Nebula 的实体分布在多个节点中,因此在实验中 DGraph 响应时间表现略优于 Nebula。
- 在 1 跳查询返回 ID「最大吞吐量」实验中,DGraph 集群节点的 CPU 负载主要落在存储关系的单节点上,造成集群 CPU 利用率低下,因此最大吞吐量仅有 Nebula 的 11%。
- 在 2 跳查询返回 ID「响应时间」实验中,由于上述原因,DGraph 在 qps=100 时已经接近了集群负载能力上限,因此响应时间大幅变慢,是 Nebula 的 3.9 倍。
- 在 1 跳查询返回属性实验中,Nebula 由于将实体的所有属性作为一个数据结构存储在单节点上,因此只需要进行【出边总数 Y】次搜索。而 DGraph 将实体的所有属性也视为出边,并且分布在不同节点上,需要进行【属性数量 X * 出边总数 Y】次出边搜索,因此查询性能比 Nebula 差。多跳查询同理。
- 在共同好友实验中,由于此实验基本等价于 2 次 1 跳查询返回 ID,因此测试结果接近,不再详述。
- 由于 HugeGraph 存储后端基于 HBase,实时并发读写能力低于 RocksDB(Nebula)和 BadgerDB(Dgraph),因此在多项实验中性能表现均落后于 Nebula 和 DGraph。
5. 结论
参与测试的图数据库中,Nebula 的批量导入可用性、导入速度、实时数据写入性能、数据多跳查询性能均优于竞品,因此我们最终选择了 Nebula 作为图存储引擎。
6. 参考资料
- NebulaGraph Benchmark:https://discuss.nebula-graph.com.cn/t/topic/782
- NebulaGraph Benchmark 微信团队:https://discuss.nebula-graph.com.cn/t/topic/1013
- DGraph Benchmark:https://dgraph.io/blog/tags/benchmark/
- HugeGraph Benchmark:https://hugegraph.github.io/hugegraph-doc/performance/hugegraph-benchmark-0.5.6.html
- TigerGraph Benchmark:https://www.tigergraph.com/benchmark/
- RedisGraph Benchmark:https://redislabs.com/blog/new-redisgraph-1-0-achieves-600x-faster-performance-graph-databases/
本次性能测试系美团 NLP 团队高辰、赵登昌撰写,如果你对本文有任意疑问,欢迎来原贴和作者交流:https://discuss.nebula-graph.com.cn/t/topic/1377