数据库 单表 13 亿记录创建索引需要多长时间?
这个问题来自 twitter 上一个网友的问题:
https://twitter.com/laixintao/status/1312963759346860037
万推,对 13 亿的 IP 地址(已经转成 int 存储)在 MySQL 中建立索引最快的方法是什么啊?不要求在线,可以锁表可以停机。机械硬盘... 64C256G 配置...
有生之年跑不完的样子...
一堆网友说要分表,还有网友给出了分表之后估算时间,64C256G 的服务器要 24 小时跑完。
13 亿 IP 地址,必须要做读写分离了,读库也应该分表了。建议 5000W 一张表。如果 sharding 算法速度快的话,建议 1000W 一张表。1000W 数据停机建立索引,10 分钟应该可以了。你 64C,估算 130 张表 24 小时可以跑完。
最后原 PO 给出了在自己的 64C256G 服务器上跑的结果,34 分钟左右跑完:

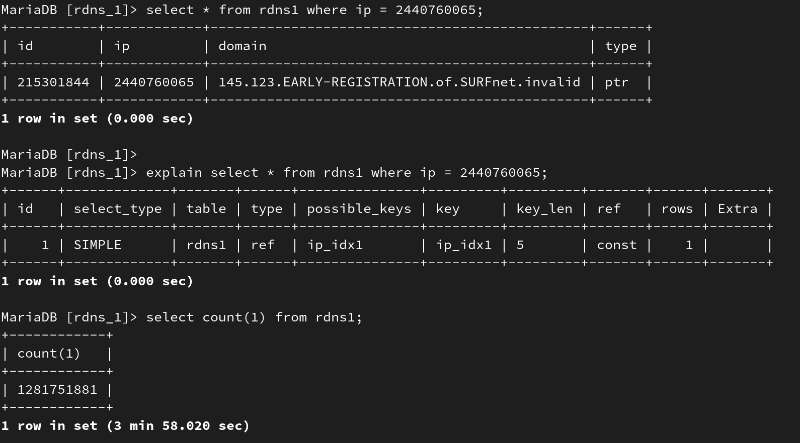
这个话题不错,拿来测试一下挺有意思,在 vultr 上买了一个 8C32G 的服务器,大概每小时 0.2 刀,也不贵...
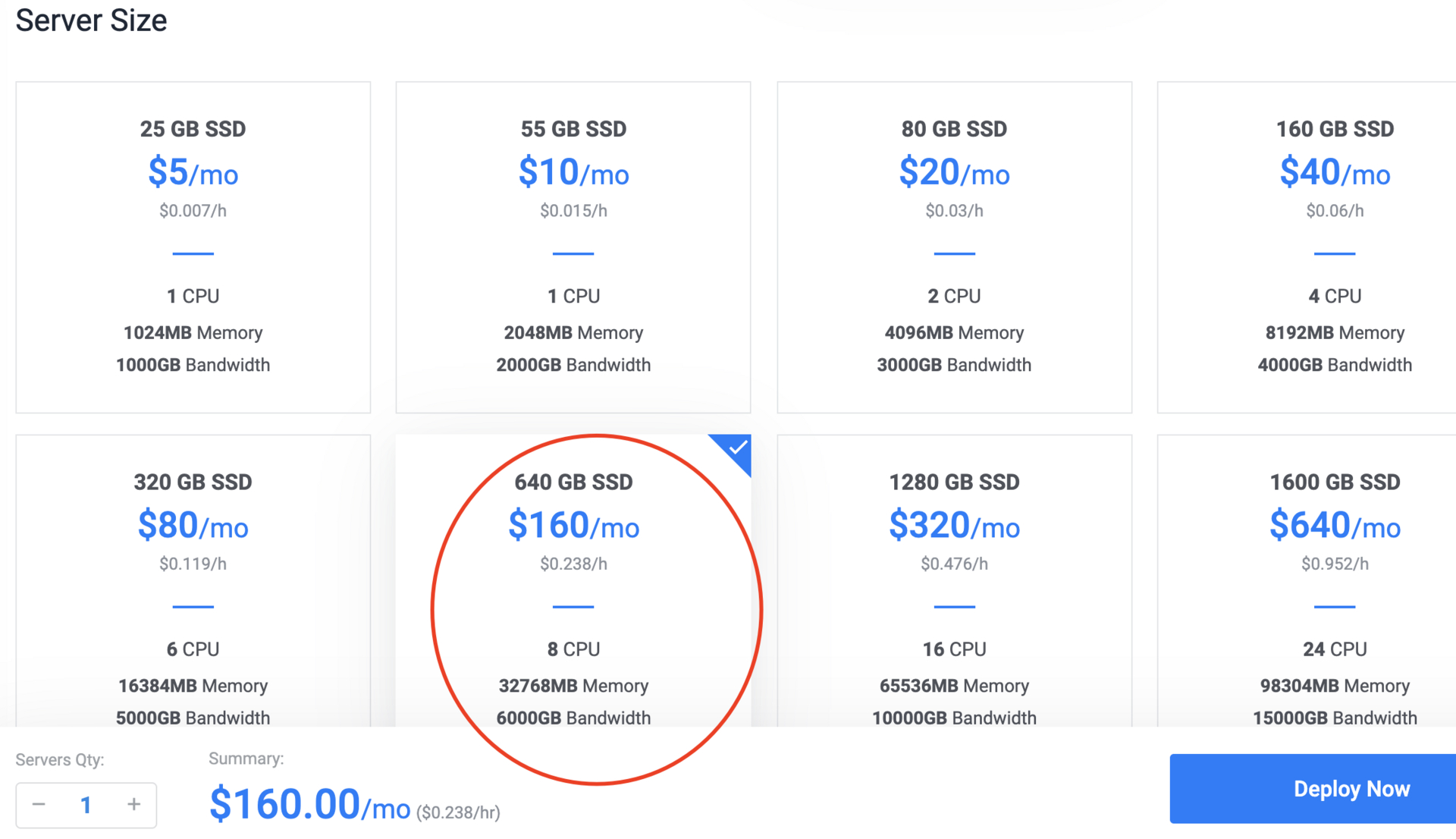
顺便记录一下测试的脚本,方便感兴趣的可以验证。
安装 Postgres 13 和 Ubuntu 20.04:https://hackershare.dev/cn/bookmarks/4978
初始化表结构:
CREATE unlogged TABLE "test" (
"id" SERIAL PRIMARY KEY NOT NULL,
"ip" integer NOT NULL,
"domain" varchar DEFAULT 'drawerd.com'
);
插入 13 亿条记录:
insert into test(ip) select generate_series(1,1280000000);
插入过程耗时挺久的,大概一个多小时,这里图简单,没做什么优化。感兴趣的可以优化插入速度,比如先把主键索引关掉,用脚本生成 csv,再 copy。
\dt+ test
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+-------+-------+----------+-------------+-------+-------------
public | test | table | postgres | unlogged | 62 GB |
创建索引:
SET maintenance_work_mem to '30GB';
SET max_parallel_maintenance_workers to 8;
ALTER TABLE test SET (parallel_workers = 8);
执行创建语句:
CREATE INDEX idx ON test (ip);
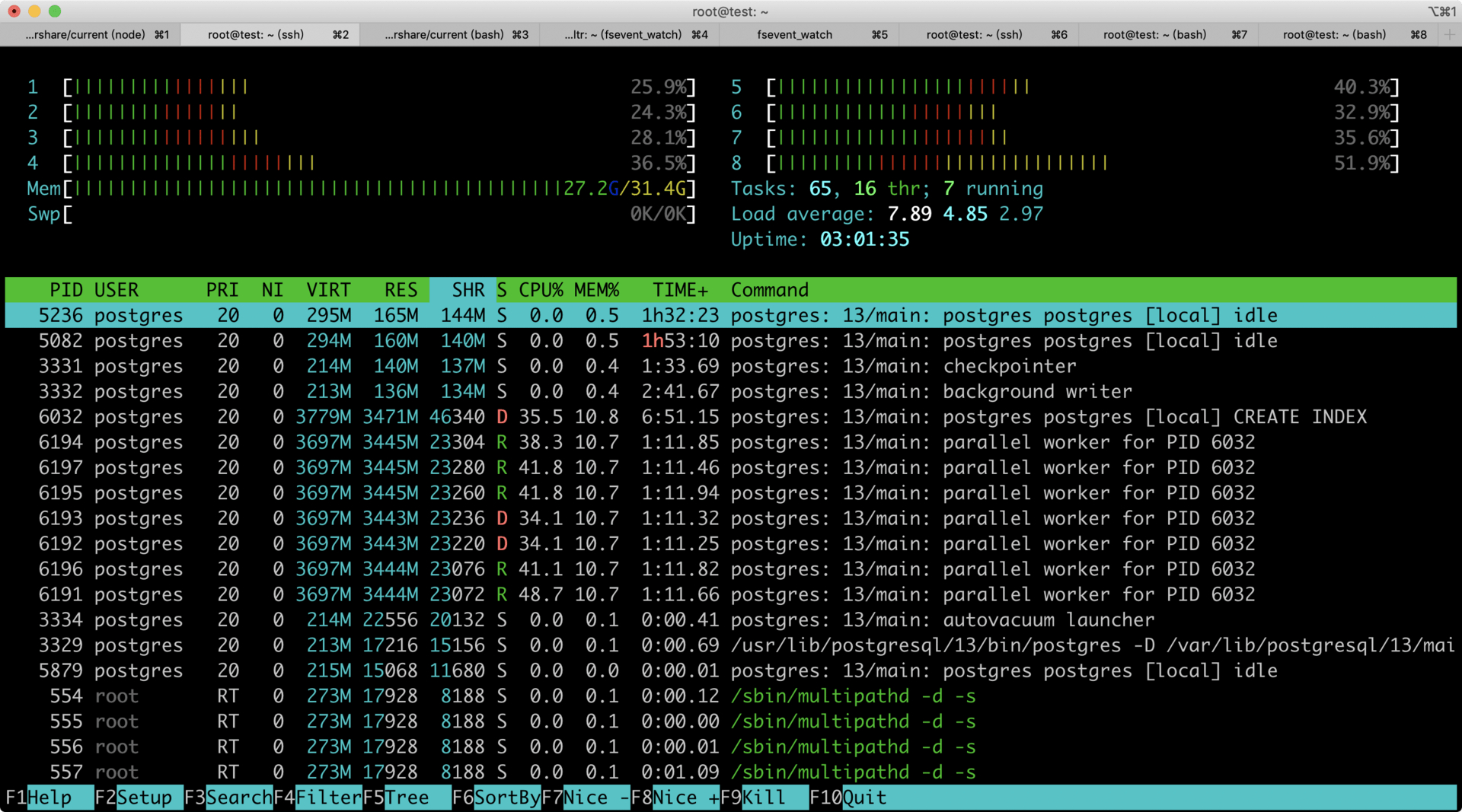
最终 24 分钟跑完。如果和原 PO 同样配置 64C256G 的话,开 64 个并行,按线性算大概 3 分钟跑完,但实际应该达不到,并行切换和调度还会有很大开销,但至少比目前的 8C32G 的要快很多。
最后又测了一下 Postgres 内建的 partition,看看对创建索引会不会起到加速的作用,测试的结果是 18 分钟左右:
CREATE unlogged TABLE "ptest" (
"id" SERIAL PRIMARY KEY NOT NULL,
"ip" integer NOT NULL,
"domain" varchar DEFAULT 'drawerd.com'
) partition by hash(id);
create table dept_1 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 0);
create table dept_2 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 1);
create table dept_3 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 2);
create table dept_4 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 3);
create table dept_5 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 4);
create table dept_6 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 5);
create table dept_7 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 6);
create table dept_8 partition of ptest FOR VALUES WITH (MODULUS 8, REMAINDER 7);
除了建表语句不一样,其他都和上面一样操作。