分享 Nebula Graph 在大规模数据量级下的实践和定制化开发

本文作者系微信技术专家李本利
图数据在社交推荐、多跳实时计算、风控和安全等领域有可期待的前景。如何用图数据库高效存储和查询大规模异构图数据,是一个重大挑战。本文描述了开源分布式图数据库 Nebula Graph 实践中遇到的问题,并通过深度定制,实现:大数据集存储、小时级全量导入、多版本控制、秒级回滚、毫秒级访问等特性。
背景
为大众所熟知的图数据库大多在大数据集合上束手无策,如:Neo4j 的社区版本,采用 Cypher 语言,由单机单副本提供服务,广泛应用于图谱领域。互联网公司只能在小数据集合下使用,还要解决 Neo4j 多副本一致性容灾的问题。JanusGraph 虽然通过外置元数据管理、kv 存储和索引的方式解决了大数据集合存储问题,但其存在广为诟病的性能问题。我们看到大部分图数据库在对比性能时都会提到和 JanusGraph 相比有几十倍以上的性能提升。
面临大数据量挑战的互联网公司,普遍走向了自研之路,为了贴合业务需求,仅支持有限的查询语义。国内主流互联网公司如何解决图数据库的挑战呢:
-
蚂蚁金服:GeaBase[1]
金融级图数据库,通过自定义类语言为业务方提供服务,全量计算下推,提供毫秒级延时。主要应用于以下场景:
- 金融风控场景:万亿级边资金网络,存储实时交易信息,实时欺诈检测。
- 推荐场景:股票证券推荐。
- 蚂蚁森林:万亿级的图存储能力,低延时强一致关系数据查询更新。
- GNN:用于小时级 GNN 训练。尝试动态图 GNN 在线推理。[7]
阿里巴巴:iGraph[2] iGraph 是图索引及查询系统,存储用户的行为信息,是阿里数据中台四驾马车之一。通过 Gremlin 语言为业务方提供电商图谱实时查询。
今日头条:ByteGraph[3] ByteGraph 通过在 kv 上增加统一 cache 层,关系数据拆分为 B+ 树以应对高效的边访问和采样,类似 Facebook 的 TAO [6]。
...
架构图
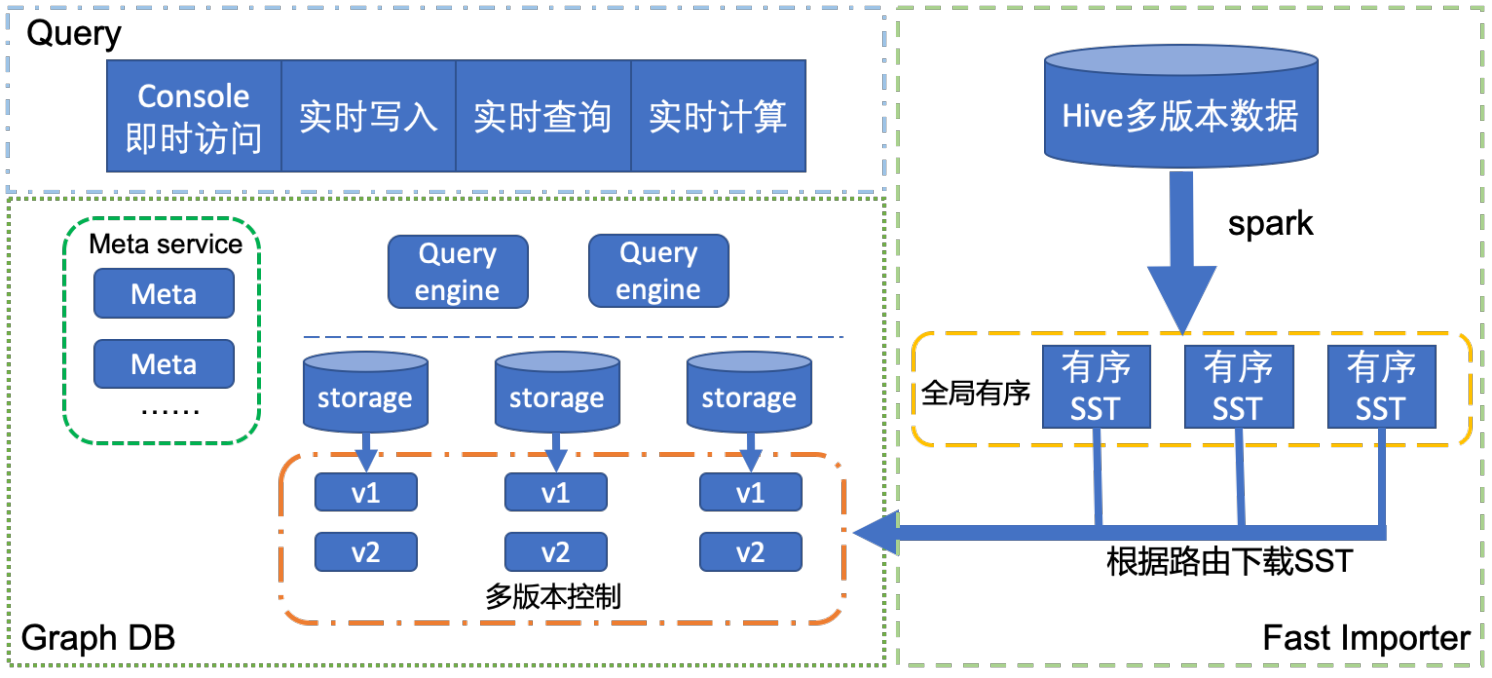
实践
从哪里开始呢?
我们选择从 Nebula Graph[4] 开始我们的图数据库之旅,其吸引我们的有以下几点:
- 数据集分片,每条边独立存储,超大规模数据集存储潜力。
- 定制强一致存储引擎,具有计算下推和 MMP 优化的潜力。
- 创始团队有丰富的图数据库经验,大数据集合下模型抽象思路经过验证。
实践中的问题
内存爆炸
本质上这是一个性能 VS 资源的问题,数据规模庞大的应用中,内存占用是一个不容忽视的问题。RocksDB 内存由三部分构成:block cache、index 和 bloom filter、iter pined block。
- block cache 优化:采用全局 LRU cache,控制机器上所有 rocksdb 实例的 cache 占用。
- bloom filter 优化:一条边被设计为一个 kv 存入到 rocksdb,如果全部 key 保存 bloom filter,每个 key 占用 10bit 空间,那么整个 filter 内存占用远超机器内存。观察到我们大部分的请求模式是获取某一个点的边列表,因此采用 prefix bloom filter;索引到点属性这一层实际上即可以对大多数请求进行加速。经过这个优化,单机 filter 所占用内存在 G 这个级别,大多数请求访问速度并未明显降低。
多版本控制
实践中,图数据需要进行快速回滚,定期全量导入,自动访问最新版本数据。我们把数据源大致可以分为两种类型:
- 周期性数据:比如,按天计算相似用户列表,导入后数据生效。
- 历史数据 + 实时数据:比如,历史数据按天刷新,和实时写入的数据进行合并成为全量数据。
如下是数据在 rocksdb 的存储模型:

vertex 存储格式
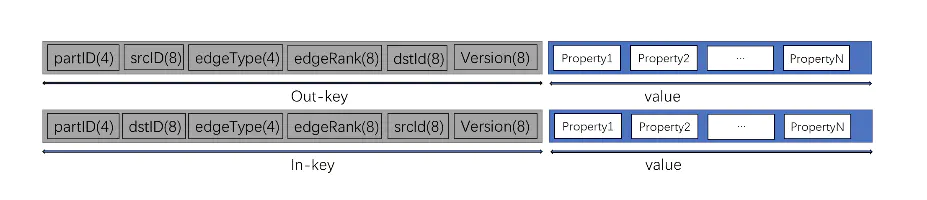
edge 存储格式
其中实时写入的数据 version 记录为时间戳。离线导入的数据 version 需要自己指定。我们将该字段和离线导入模块联合使用,用三个配置项进行版本控制:reserve_versions(需要保留的版本列表)、active_version(用户请求访问到的版本号)、max_version(保留某个版本之后数据,把历史数据和实时写入数据进行合并)。这样可以高效管理离线数据和在线数据,不再使用的数据在下一次 compaction 中被清除出磁盘。
通过这样的方式,业务代码可以无感更新数据版本,并做到了秒级回滚。
举例:
- 保留 3 个版本,激活其中一个版本:
alter edge friend reserve_versions = 1 2 3 active_version = 1 - 数据源为历史数据 + 实时导入数据。
alter edge friend max_version = 1592147484
快速批量导入
实践中导入大量数据是常规操作,如果不经任何优化,将需要导入的数据转为请求发给图数据库,不仅严重影响线上请求,而且大数据量导入耗时超过一天。对导入速度进行优化迫在眉睫。业界解决这个问题一般采用 SST Ingest 方式 [5]。我们也是采用类似方式,通过例行调度 spark 任务,离线生成磁盘文件。然后数据节点拉取自己所需要的数据,并 ingest 到数据库中,之后进行版本切换控制请求访问最新版本数据。
整个过程导入速度快,约数个小时内完成全部过程。计算过程主要离线完成,对图数据库请求影响小。
shared nothing
这是近年来老生常谈的并发加速方式,然而要落地还是考验工程师的编程功底。meta cache 访问频繁,并用 shared_ptr 进行封装,也就成为了原子操作碰撞的高发地。为了能够实现真正的 shared nothing,我们将每一份 meta cache 拷贝为 thread local,具体解决方案请参考该 pull request [8]
小结
图数据库路阻且长,且行且珍惜。如果对于本文有什么疑问,可以在 GitHub[9] 上找找。
参考文献
- Fu, Zhisong, Zhengwei Wu, Houyi Li, Yize Li, Min Wu, Xiaojie Chen, Xiaomeng Ye, Benquan Yu, and Xi Hu. "GeaBase: a high-performance distributed graph database for industry-scale applications." International Journal of High Performance Computing and Networking 15, no. 1-2 (2019): 12-21.
- https://mp.weixin.qq.com/s?__biz=MzU0OTE4MzYzMw==&mid=2247489027&idx=3&sn=c149ce488cfc5231d4273d6da9dc8679&chksm=fbb29ffdccc516ebb8313b9202cfd78ea199da211c55b0a456a9e632a33e7d5b838d8da8bc6a&mpshare=1&scene=1&srcid=0614MWpeEsBc1RaBrl4htn3D&sharer_sharetime=1592106638907&sharer_shareid=a2497c4756f8bac1bcbef9edf86a86ac&rd2werd=1#wechat_redirect
- https://zhuanlan.zhihu.com/p/109401046
- https://github.com/vesoft-inc/nebula
- https://www.infoq.cn/article/SPYkxplsq7f36L1QZIY7
- Bronson, Nathan, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov, Hui Ding, Jack Ferris et al. "{TAO}: Facebook’s distributed data store for the social graph." In Presented as part of the 2013 {USENIX} Annual Technical Conference ({USENIX}{ATC} 13), pp. 49-60. 2013.
- http://blog.itpub.net/69904796/viewspace-2653498/
- https://github.com/vesoft-inc/nebula/pull/2165
- https://github.com/xuguruogu/nebula
- 腾讯高性能分布式图计算框架柏拉图 https://github.com/Tencent/plato
🤩 加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot