分享 基于 Jepsen 来发现几个 Raft 实现中的一致性问题 (2)
Nebula Graph 是一个高性能、高可用、强一致的分布式图数据库。由于 Nebula Graph 采用的是存储计算分离架构,在存储层实际只是暴露了简单的 kv 接口,采用 RocksDB 作为状态机,通过 Raft 一致性协议来保证多副本数据一致的问题。Raft 协议虽然比 Paxos 更加容易理解,但在工程实现上还是有很多需要注意和优化的地方。
另外,如何测试基于 Raft 的分布式系统也是困扰业界的问题,目前 Nebula 主要采用了 Jepsen 作为一致性验证工具。之前我的小伙伴已经在《Jepsen 测试框架在图数据库 Nebula Graph 中的实践》中做了详细的介绍,对 Jepsen 不太了解的同学可以先移步这篇文章。
在这篇文章中将着重介绍如何通过 Jepsen 来对 Nebula Graph 的分布式 kv 进行一致性验证。
强一致的定义
首先,我们需要什么了解叫强一致,它实际就是 Linearizability,也被称为线性一致性。引用《Designing Data-Intensive Applications》里一书里的定义:
In a linearizable system, as soon as one client successfully completes a write, all clients reading from the database must be able to see the value just written.
也就是说,强一致的分布式系统虽然其内部可能有多个副本,但对外暴露的就好像只有一个副本一样,客户端的任何读请求获取到的都是最新写入的数据。
Jepsen 如何检查系统是否满足强一致
以一个 Jepsen 测试的 timeline 为例,采用的模型为 single-register,也就是整个系统只有一个寄存器(初始值为空),客户端只能对该寄存器进行 read 或者 write 操作(所有操作均为满足原子性,不存在中间状态)。同时有 4 个客户端对这个系统发出请求,图中每一个方框的上沿和下沿代表发出请求的时间和收到响应的时间。

从客户端的角度来看,对于任何一次请求,服务端处理这个请求可能发生在从客户端发出请求到接收到对应的结果这段时间的任何一个时间点。可以看到在时间上,客户端 1/3/4 的三个操作 write 1/write 4/read 1 在时间上实际上是存在 overlap 的,但我们可以通过不同客户端所收到的响应,确定系统真正的状态。
由于初始值为空,客户端 4 的读请求却获取到了 1,说明客户端 4 的 read 操作一定在客户端 1 的 write 1 之后,且 write 4 发生在 write 1 之前(否则会读出 4),则可以确认三个操作实际发生的顺序为 write 4 -> write 1 -> read 1。尽管从全局角度看,read 1 的请求最先发出,但实际却是最后被处理的。后面的几个操作在时间上是不存在 overlap,是依次发生的,最终客户端 2 最后读到了最后一次写入的 4,整个过程中没有违反强一致的定义,验证通过。
如果客户端 3 的那次 read 获取到的值是 4,那么整个系统就不是强一致的了,因为根据之前的分析,最后一次成功写入的值为 1,而客户端 3 却读到了 4,是一个过期的值,也就违背了线性一致性。事实上,Jepsen 也是通过类似的算法来验证分布式系统是否满足强一致的。
通过 Jepsen 的一致性验证找到对应问题
我们先简单介绍一下 Nebula Raft 里面处理一个请求的流程(以三副本为例),以便更好地理解后面的问题。读请求相对简单,由于客户端只会将请求发送给 leader,leader 节点只需要在确保自己是 leader 的前提下,直接从状态机获取对应结果返回给客户端即可。
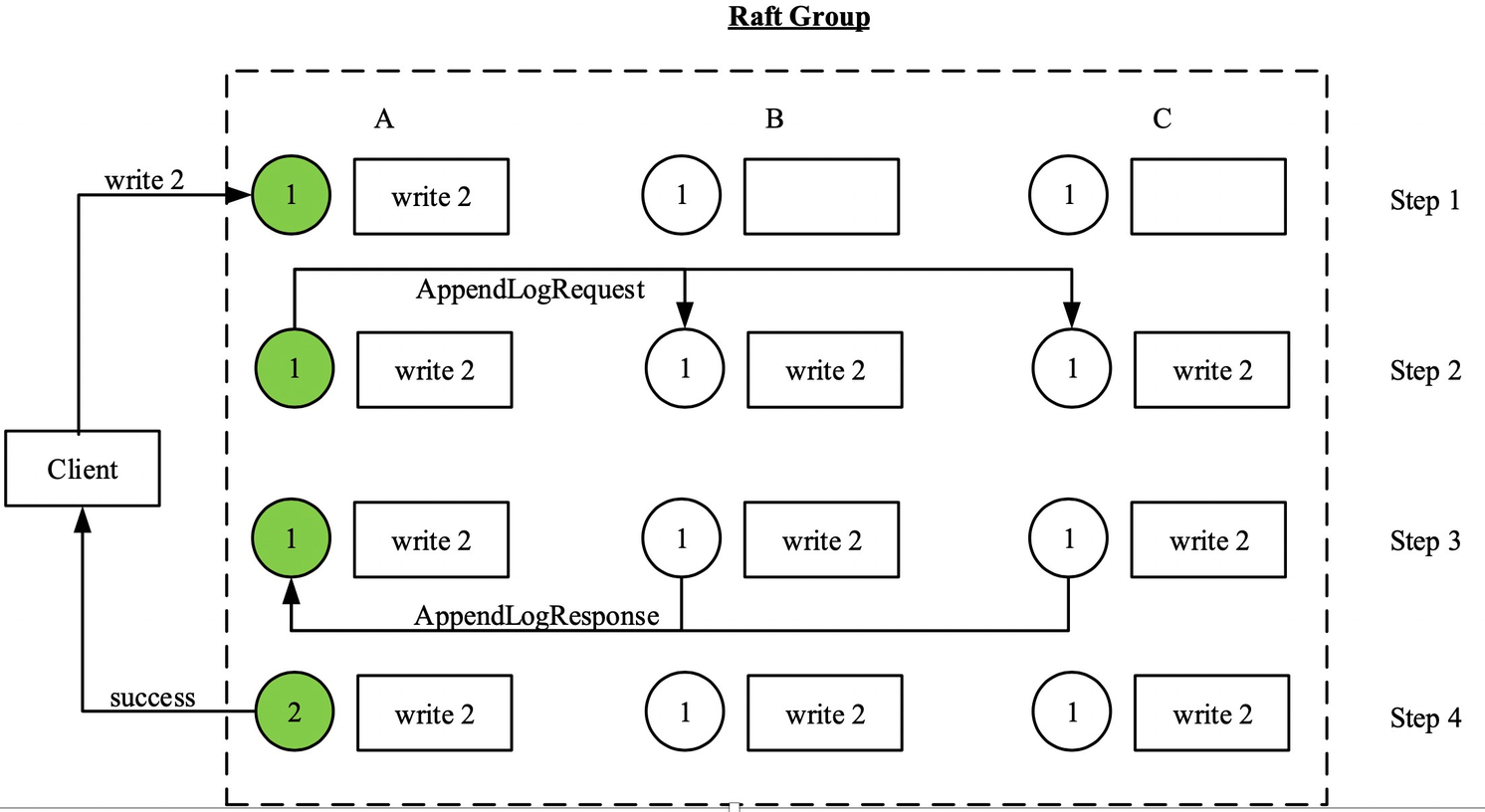
写请求的流程则复杂一些,如 Raft Group 图所示:
- Leader(图中绿色圈)收到 client 发送的 request,写入到自己的 wal(write ahead log)中。
- Leader 将 wal 中对应的 log entry 发送给 follower,并进入等待。
- Follower 收到 log entry 后写入自己的 wal 中 (不等待应用到状态机),并返回成功。
- Leader 接收到至少一个 follower 返回成功后,应用到状态机,向 client 发送 response。
下面我将用示例来说明通过 Jepsen 测试在之前的 Raft 实现中发现的一致性问题:
如上图所示,ABC 组成一个三副本 raft group,圆圈为状态机(为了简化,假设其为一个 single-register),方框中则是保存的相应 log entry。
- 在初始状态,三个副本中的状态机中都为 1,Leader 为 A,term 为 1
- 客户端发送了 write 2 的请求,Leader 根据上面的流程进行处理,在向 client 告知写入成功后被 kill。(step 4 完成后)
- 此后 C 被选为 term 2 的 leader,但由于 C 此时有可能还没有将之前 write 2 的 log entry 应用到状态机(此时状态机中仍为 1)。如果此时 C 接受到客户端的读请求,那么 C 会直接返回 1。这违背了强一致的定义,之前已经成功写入 2,却读到了过期的结果。
这个问题是出在 C 被选为 term 2 的 leader 后,需要发送心跳来保证之前 term 的 log entry 被大多数节点接受,在这个心跳成功之前是不能对外提供读(否则可能会读到过期数据)。有兴趣的同学可以参考 raft parer 中的 Figure 8 以及 5.4.2 小节。
从上一个问题出发,通过 Jepsen 我们又发现了一个相关的问题:leader 如何确保自己还是 leader?这个问题经常出现在网络分区的时候,当 leader 因为网络问题无法和其他节点通信从而被隔离后,此时如果仍然允许处理读请求,有可能读到的就是过期的值。为此我们引入了 leader lease 的概念。
当某个节点被选为 leader 之后,该节点需要定期向其他节点发送心跳,如果心跳确认大多数节点已经收到,则获取一段时间的租约,并确保在这段时间内不会出现新的 leader,也就保证该节点的数据一定是最新的,从而在这段时间内可以正常处理读请求。
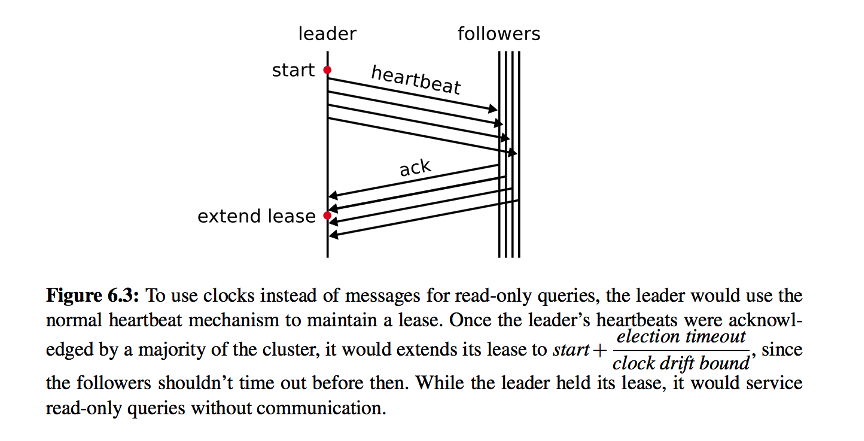
和 TiKV 的处理方法不同的是,我们没有采取心跳间隔乘以系数作为租约时间,主要是考虑到不同机器的时钟漂移不同的问题。而是保存了上一次成功的 heartbeat 或者 appendLog 所消耗的时间 cost,用心跳间隔减去 cost 即为租约时间长度。
当发生网络分区时,leader 尽管被隔离,但是在这个租约时间仍然可以处理读请求(对于写请求,由于被隔离,都会告知客户端写入失败),超出租约时间后则会返回失败。当 follower 在至少一个心跳间隔时间以上没有收到 leader 的消息,会发起选举,选出新 leader 处理后续的客户端请求。
结语
对于一个分布式系统,很多问题需要长时间的压力测试和故障模拟才能发现,通过 Jepsen 能够在不同注入故障的情况下验证分布式系统。之后我们也会考虑采用其他混沌工程工具来验证 Nebula Graph,在保证数据高可靠的前提下不断提高性能。
本文中如有错误或疏漏欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.com.cn/ 的 建议反馈 分类下提建议 👏;加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot
推荐阅读
作者有话说:Hi,我是 critical27,是 Nebula Graph 的研发工程师,目前主要从事存储相关的工作,希望能为图数据库领域带来一些自己的贡献。希望本文对你有所帮助,如果有错误或不足也请与我交流,不甚感激。