Python Python 新手] 爬虫练习:爬取起点中文网的小说排行并存入 excel 表格中
使用的 python 库 1.request 库,用于向服务器发起请求信息。 2.lxml 库,用于解析服务器返回的 HTML 文件。 3.time 库,设置爬取时间差,防止短时间内多次页面请求而被限制访问。 4.xwlt 库,用于将数据存入 excel 表格之中。
爬取思路 1.爬取页面的网址为https://www.qidian.com/all?page=1page的值不一样,由此可以得到所有页面的网址。,经过手动浏览可以发现页面之间 2.需要爬取的信息如下图所示: 在这里插入图片描述 3.在信息提取完成之后使用 xlwt 库将它们存入 excel 表格中。
爬虫代码 import xlwt from lxml import etree import request import time
#伪装请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36' ' (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' }
all_info_list = [] #存储每部小说的各种信息列表
#定义获取爬虫信息的函数 def get_info(url): res = requests.get(url, headers=headers) selector = etree.HTML(res.text) #采用 xpath 方法对网页信息进行搜索 infos = selector.xpath('//ul[@class="all-img-list cf"]/li') #找到信息的循环点 for info in infos: title = info.xpath('div[2]/h4/a/text()')[0] author = info.xpath('div[2]/p[@class="author"]/a[@class="name"]/text()')[0] style1 = info.xpath('div[2]/p[@class="author"]/a[2]/text()')[0] style2 = info.xpath('div[2]/p[@class="author"]/a[3]/text()')[0] style = style1+'-'+style2 complete = info.xpath('div[2]/p[@class="author"]/span/text()')[0] introduce = info.xpath('div[2]/p[@class="intro"]/text()')[0].strip() info_list = [title, author, style, complete, introduce] all_info_list.append(info_list) #爬取成功后等待两秒 time.sleep(2)
#主程序入口 if name == "main": urls = ['https://www.qidian.com/all?page=.format(str(i)){}' for i in range(1, 101)] for url in urls: get_info(url) #写好 excel 表格中的各个属性名 header = ['书名', '作者', '类型', '状态', '简介'] book = xlwt.Workbook(encoding='utf-8') sheet = book.add_sheet('sheet1') for h in range(len(header)): sheet.write(0, h, header[h]) i = 1 #将提取到的信息写入 excel 表格中 for list in all_info_list: j = 0 for data in list: sheet.write(i, j, data) j += 1 i += 1 #将信息保存在 D:/reptile 目录下的 xiaoshuo.xls 文件中 book.save('D:/reptile/xiaoshuo.xls')
爬取结果
在这里插入图片描述
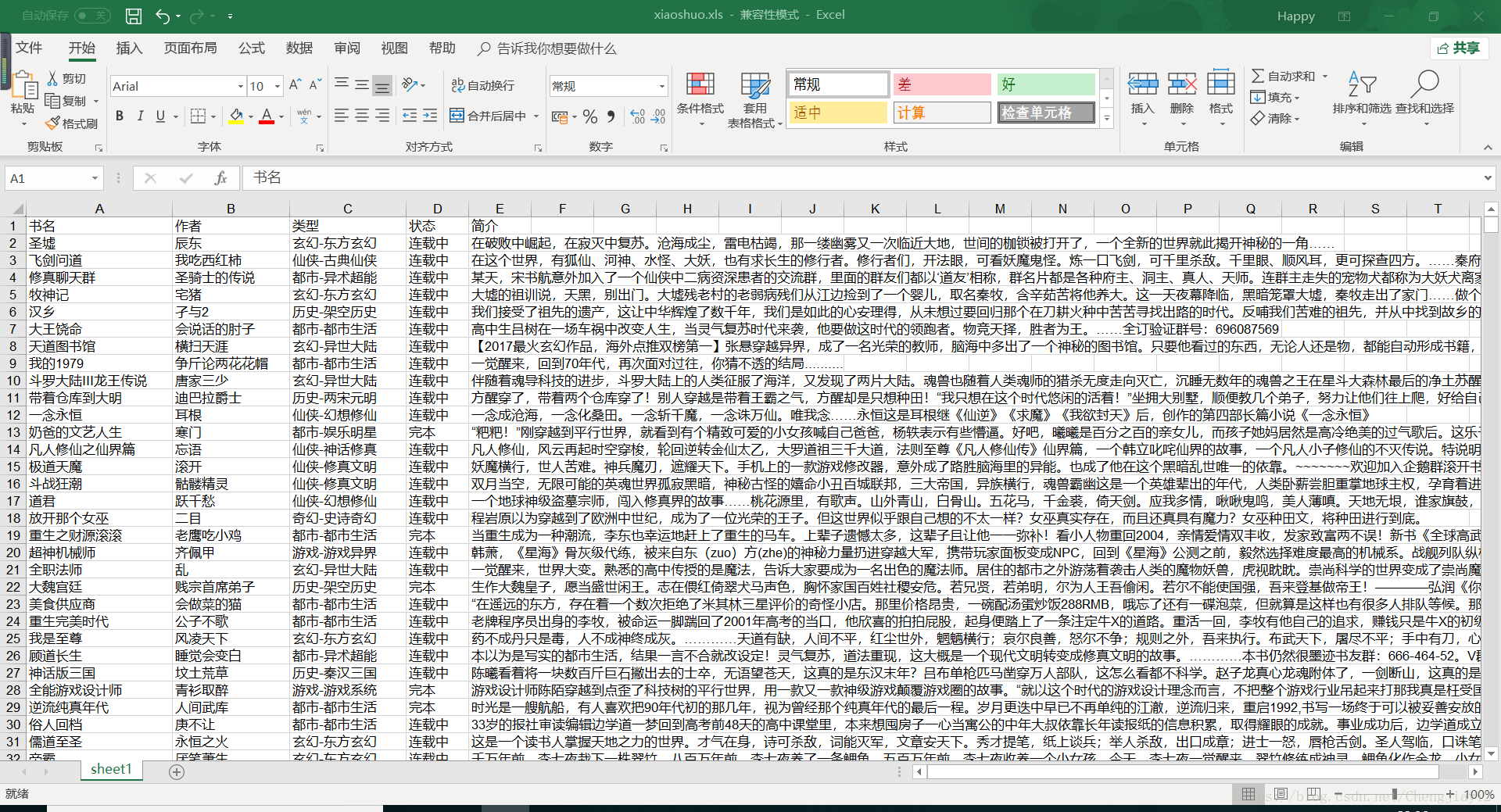
总结 虽然能成功的爬取小说的大部分信息,但是由于小说的字数信息在网页上并不是不变的,使用没能爬取到小说的字数信息,本次爬虫练习基本上完成了爬虫的功能,但在复杂页面的爬取上面还得继续学习。