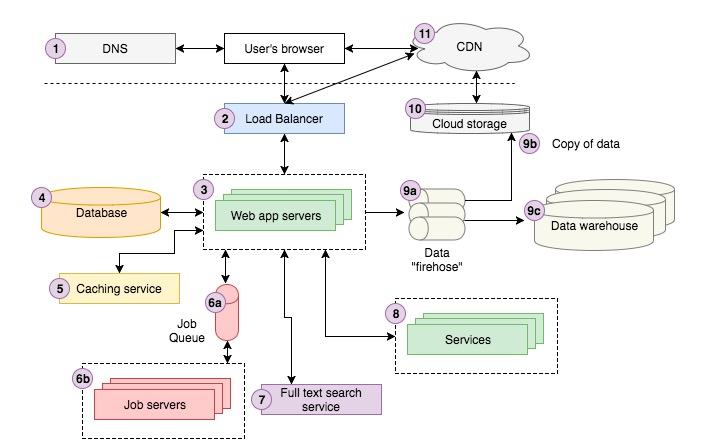
我们先来看一个 use case 流程:
- 用户在 google 搜到我们网站的一篇文章,于是点击。用户会发送一个 request 给 DNS,询问如何解析我们的域名,也就是如何将域名转化为 IP 地址。之后用户的浏览器用这个 IP 地址,发送 request 到我们的 load balancer
- load balancer 会从 web server 中分配一台合适的给 request(业界有各种不同的 load balancing 算法)。web server 的职责一般是负责给用户提供渲染好的网页。
- web server 会从 cache 中加载已经缓存的图片,从 database 加载其他数据。如果 web server 发现有个图片没有被缓存,甚至没有被生成,那么它会生成一个 job,加到 job queue 里面。而 job server 会异步的生成图片,并且把数据更新到 database
- 如果说,这个页面还需要显示比如说同类型的其他一些图片,那么 web server 会发送一个 request 给我们自己的全文搜索引擎(full text search engine)
- 对于已登陆的用户,页面还要加载用户信息
- 最后,发送一个 event 到 data firehose,evert 最终会被记录在 data warehouse,以便数据分析和 BI。
- 这时,web server 才把 html 渲染好,发送会用户浏览器。这个过程还会经过 load balancer。而页面中的 javascript 和 css 一般存储在 CDN。这之后,用户能在浏览器上看到完整的页面
下面我们来详细说说,图中的各个部分是用来干什么的
1. DNS
DNS 是域名服务器。它类似于一个 hash table,把域名映射到 IP 地址。类比一下我们常见的通讯录,是把人名映射到电话号码一样。
当然,很多大公司的域名会被映射到很多不同的 IP 地址。现在不展开讲解。
2. Load balancer
中文里一般叫做 负载均衡。在讲这个之前,我们需要来说说 horizontal vs. vertical scaling。
Scaling
Scaling 是指扩展,当网站的需求量大于了网站的接纳能力时,网站需要 scale out。Vertical scaling(纵向扩展),是通过扩大一台服务器的硬件能力来扩展,比如加硬盘,加内存,加 CPU。但它的问题在于,它很容易达到上限。想象现在单块硬盘的容量才多大。而 horizontal scaling(横向扩展),是通过增加服务器的数量来扩展。这显然比 vertical scaling 的上限要高得多。以 Storyblocks 为例,现在有 150 - 400 台 AWS EC2 在运行。而这不可能由一台巨大的服务器来完成。
在网站架构中,一个稍微大点的网站肯定会做 horizontal scaling。这还有助于避免 single point of failure(也就是当一台服务器挂了的时候,网站不会整个挂掉)。换句专业术语说,网站变得 fault tolerant。
Horizontal scaling 的另一点好处是,可以 decouple server 之间的职能。网站可以按照 web server, database, cache, service X 等来划分。(而且,还可以由不同的 team 来管理不同的 server,从而影响公司的组织结构,译者注)。
Load balancing
Load balancing 简单说就是把请求合理的分配给服务器,比如不让某台服务器特别忙而其他的特别闲。这就要求 load balancer 所管理的这些 server 要能按照完全一样的工作方式工作。一个 request 不管被分配到哪台 server,它所返回的结果应该完全一样。
另外,有些 request 是跟用户相关的。同一类型请求来自不同用于,所返回的结果也不同。这时 load balancer 该如何处理?这样的问题叫 sticky session problem
3. web server
Web server 可以说是用户做业务逻辑请求的入口。所以一般 web server 会和后端 services 进行通讯。为了避免 single point of failure,一般再小的网站,web server 也应该至少两台,如果预算允许的话。
web server 所使用的技术,一般是 MVC 或者 MVP web framework。常见的 web framework 所使用的语言可以是 node.js, ruby, php, python, java, c# .NET 等等。
4. Database
Database 提供对数据的增删查改,一般称为 CRUD(create, read, update, delete)。在 microservices 架构中,很多 service 会有属于自己的 database。这样做的原因也是为了 decouple。
这里主要提两个技术:不严谨的说叫做 SQL vs. NoSQL。严谨一些,应该叫做 relational database vs. non-relational database
SQL 是 relational database 最流行的语言,所以一般也用来代指了这类 database。它擅长处理 data entities 之间的关系,比如一对一,一对多,多对多。
更多关于 SQL 的细节,我个人推荐 W3Cschools 的 SQL 教程。
而 NoSQL,泛指所有 non-relational database,其实是有很多不同类型的。它们很多都不擅长处理 data entities relation。但它们有自己擅长的。有的是能存储更大量的数据,比如 mongodb,有的是擅长处理 key value storage,比如 redis,有的擅长处理地理数据,比如 neo4j。所以 relational database 并不是架构中 database 的唯一选择。
5. Cache
Cache (缓存) 就是将常用的数据存储在一个单独的地方,这个地方一般来说提供了更快速的硬件,可能比硬盘快 10 倍以上。而 database 一般存储在硬盘上,所以 cache 的读取速度远快于 database。
Cache 理论上可以存储任何类型的数据,不过一般大家经常存储的是 key value pair、文件、渲染好的 page、复杂的 data query 的结果等等。
一些例子:
- Google 把 taylor swift 的搜索结果缓存了起来
- Facebook 会把特别活跃用户的首页应该显示的内容缓存起来
- Storyblocks 缓存一些 rendered page,搜索结果等
6. Job queue
Job 是指在后台异步处理的工作。Job 出现的原因是,比如按照 request 压缩一张图片。这个任务可能需要 1 秒。如果在 web server 上进行,那么这台 web server 可能在 1 秒内不能接受其他 request,或者至少是影响 web server 的性能。这对于流量很大的网站是不可接受的。所以有了 job server 来异步处理 job。当 job 完成后,job server 会以某种方式通知其他 server。
再举个例子,google 每时每刻都要关注世界上其他网站每天发布的新的页面,抓取页面并 index。这些都是在他的 job server 上进行的。
Job queue 一般由两个部分组成,一个部分是 queue 本身,另一个是 worker,用于执行 job。
最简单的 job queue 就是一个 FIFO 的数据结构。你也可以使用 priority queue 来实现,如果你的 job 有 priority 的话。
7. Full-text search service
这个技术是,用户提供一个 text query,service 返回相关结果。它们一般通过一个 inverted index(反向索引) 技术 来实现。
比如说,我们在网站的搜索条里输入 man ,网站应该返回所有含有词语 man 的网页。
确实,我们可以使用 database 自带的 full-text search 功能实现,比如 mysql 和 postgres 都支持。但是更多时候我们会使用专门做 full-text search 的工具来实现,比如 elasticsearch, sphinx 或 apache solr。
8. Services
一般当网站大到一定规模后会发现,把所有业务逻辑放在一起并不方便开发、部署、管理。近年来流行的 microservices architecture 就是把不同类型的业务服务切分到不同的 services 里面,各自开发管理。各个 services 之间可以进行数据交流。
比如在 Storyblocks,我们有这些 services:
- Account service 负责用户账户
- Content service 管理视频、音频、图片、下载
- Payment service 负责收费,计费
9. Data
数据对于公司来说,在当下就是命根子。data pipeline 负责搜集、存储、分析数据。
一个典型的 data pipeline 的有 3 个阶段:
- app 发送数据(一般来说是 event ) 到 data firehose。data firehose 提供接口来接收处理元数据。AWS Kinesis 和 Kafka 是两个常用的工具。
- 存储数据。AWS Kinesis 可以非常方便的将数据存储在 AWS S3
- 处理之后的数据存入 data。Storyblocks 使用 AWS Redshift
10. Cloud storage
云存储,是指把一些原本放在比如 web server 上的文件放到云端,比如 AWS S3 上。通常静态不怎么修改的文件都会放在 cloud storage,比如 video, photo, audio, css, javascript 等等
11. CDN
CDN 的基本原理是,通过将文件在世界各个不同地区的服务器 ( edge server ) 上,来提高在不同地区加载文件的速度。用户在加载文件时,CDN 服务会自动选择从最近的服务器上加载。而文件,一般是由网站主动式的将文件传到 CDN 上。
这篇文章更详细的讲解了 CDN。