作者:个推大数据科学家朱金星
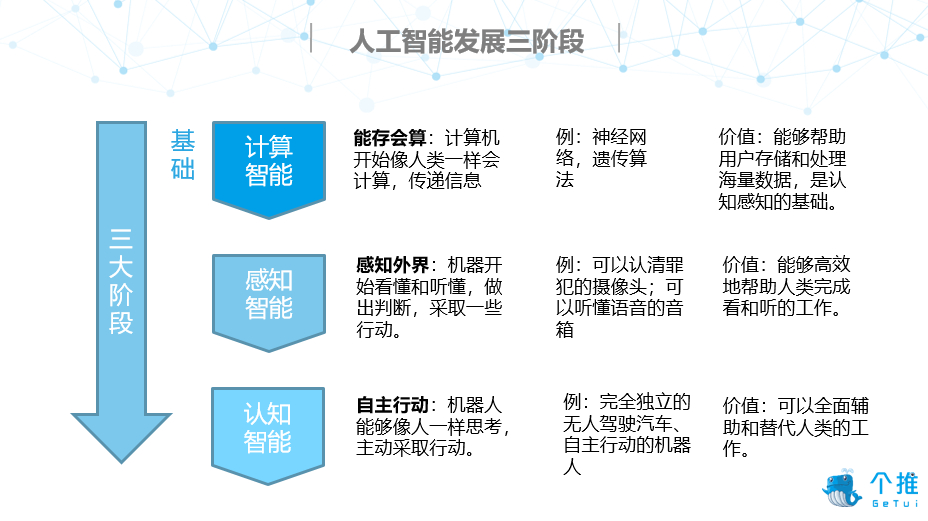
作为近几年的一大热词,人工智能一直是科技圈不可忽视的一大风口。随着智能硬件的迭代,智能家居产品逐步走进千家万户,语音识别、图像识别等 AI 相关技术也经历了阶梯式发展。如何看待人工智能的本质?人工智能的飞速发展又经历了哪些历程?本文就从技术角度为大家介绍人工智能领域经常提到的几大概念与 AI 发展简史。
一、人工智能相关概念
1、人工智能(Artifical Intelligence, AI):就是让机器像人一样的智能、会思考,
是机器学习、深度学习在实践中的应用。人工智能更适合理解为一个产业,泛指生产更加智能的软件和硬件,人工智能实现的方法就是机器学习。
2、数据挖掘:数据挖掘是从大量数据中提取出有效的、新颖的、有潜在作用的、可信的、并能最终被人理解模式 (pattern) 的非平凡的处理过程。
数据挖掘利用了统计、机器学习、数据库等技术用于解决问题;数据挖掘不仅仅是统计分析,而是统计分析方法学的延伸和扩展 ,很多的挖掘算法来源于统计学。
3、机器学习:专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,机器学习是对能通过经验自动改进的计算机算法的研究。
机器学习是建立在数据挖掘技术之上发展而来,只是数据挖掘领域中的一个新兴分支与细分领域,只不过基于大数据技术让其逐渐成为了当下显学和主流。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。
4、深度学习(Deep Learning):是相对浅层学习而言的,是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络。它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习的概念源于人工神经网络的研究。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
到了当下,经过深度学习技术训练的机器在识别图像方面已不逊于人类,比如识别猫、识别血液中的癌细胞特征、识别 MRI 扫描图片中的肿瘤。在谷歌 AlphaGo 学习围棋等等领域,AI 已经超越了人类目前水平的极限。
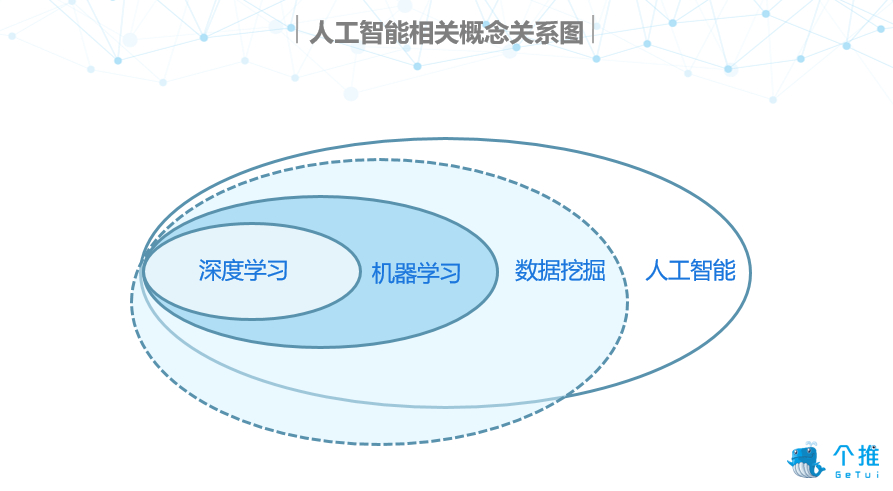
为了方便大家理解,我们将上文提到的四个概念的关系用下图表示。需要注意的是,图示展现的只是一种大致的从属关系,其中数据挖掘与人工智能并不是完全的包含关系。
二、人工智能发展历史
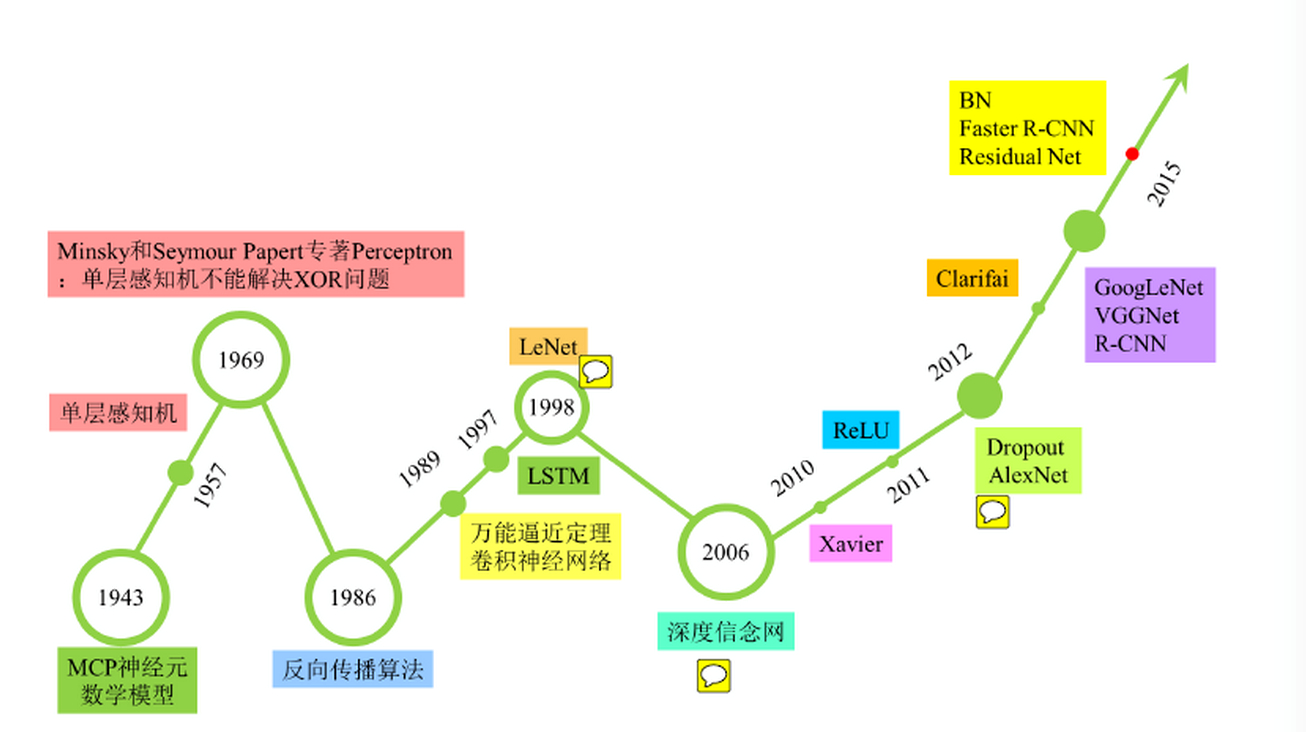
(图片来源于网络)
由图可以明显看出 Deep Learning 从 06 年崛起之前经历了两个低谷,这两个低谷也将神经网络的发展分为了几个不同的阶段,下面就分别讲述这几个阶段。
1、第一代神经网络(1958-1969)
最早的神经网络的思想起源于 1943 年的 MP 人工神经元模型,当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。如下图所示:
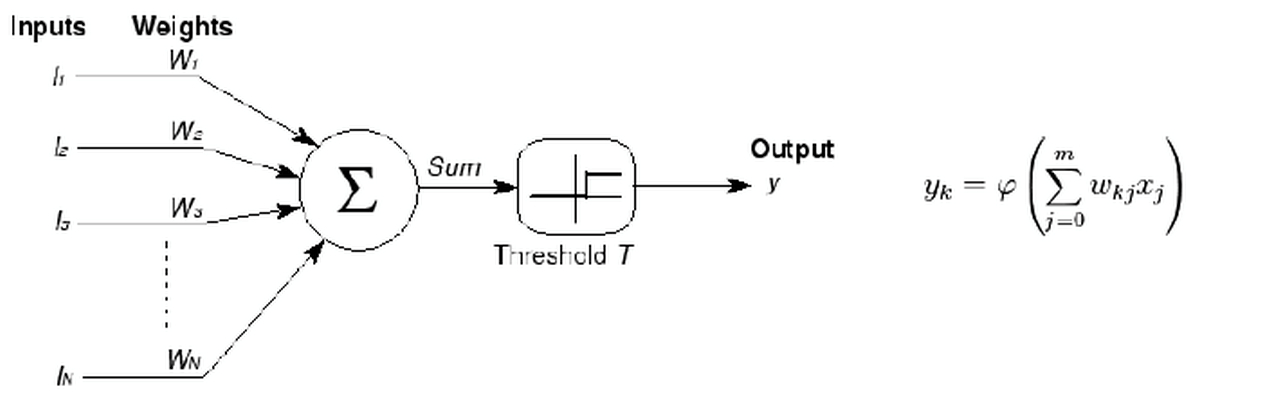
1958 年 Rosenblatt 发明的感知器(perceptron)算法。该算法使用 MP 模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962 年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。
1、第二代神经网络(1986~1998)
第一次打破非线性诅咒的当属现代 Deep Learning 大牛 Hinton,其在 1986 年发明了适用于多层感知器(MLP)的 BP 算法,并采用 Sigmoid 进行非线性映射,有效解决了非线性分类和学习的问题。该方法引起了神经网络的第二次热潮。
1989 年,Robert Hecht-Nielsen 证明了 MLP 的万能逼近定理,即对于任何闭区间内的一个连续函数 f,都可以用含有一个隐含层的 BP 网络来逼近该定理的发现极大的鼓舞了神经网络的研究人员。
同年,LeCun 发明了卷积神经网络-LeNet,并将其用于数字识别,且取得了较好的成绩,不过当时并没有引起足够的注意。
值得强调的是在 1989 年以后由于没有特别突出的方法被提出,且神经网络(NN)一直缺少相应的严格的数学理论支持,神经网络的热潮渐渐冷淡下去。
1997 年,LSTM 模型被发明,尽管该模型在序列建模上的特性非常突出,但由于正处于 NN 的下坡期,也没有引起足够的重视。
3、统计学建模的春天(1986~2006)
1986 年,决策树方法被提出,很快 ID3,ID4,CART 等改进的决策树方法相继出现。
1995 年,线性 SVM 被统计学家 Vapnik 提出。该方法的特点有两个:由非常完美的数学理论推导而来(统计学与凸优化等),符合人的直观感受(最大间隔)。不过,最重要的还是该方法在线性分类的问题上取得了当时最好的成绩。
1997 年,AdaBoost 被提出,该方法是 PAC(Probably Approximately Correct)理论在机器学习实践上的代表,也催生了集成方法这一类。该方法通过一系列的弱分类器集成,达到强分类器的效果。
2000 年,KernelSVM 被提出,核化的 SVM 通过一种巧妙的方式将原空间线性不可分的问题,通过 Kernel 映射成高维空间的线性可分问题,成功解决了非线性分类的问题,且分类效果非常好。至此也更加终结了 NN 时代。
2001 年,随机森林被提出,这是集成方法的另一代表,该方法的理论扎实,比 AdaBoost 更好的抑制过拟合问题,实际效果也非常不错。
2001 年,一种新的统一框架 - 图模型被提出,该方法试图统一机器学习混乱的方法,如朴素贝叶斯,SVM,隐马尔可夫模型等,为各种学习方法提供一个统一的描述框架。
4、快速发展期(2006~2012)
2006 年,深度学习(DL)元年。是年,Hinton 提出了深层网络训练中梯度消失问题的解决方案:无监督预训练对权值进行初始化 + 有监督训练微调。其主要思想是先通过自学习的方法学习到训练数据的结构(自动编码器),然后在该结构上进行有监督训练微调。但是由于没有特别有效的实验验证,该论文并没有引起重视。
2011 年,ReLU 激活函数被提出,该激活函数能够有效的抑制梯度消失问题。
2011 年,微软首次将 DL 应用在语音识别上,取得了重大突破。
5、爆发期(2012~至今)
2012 年,Hinton 课题组为了证明深度学习的潜力,首次参加 ImageNet 图像识别比赛,其通过构建的 CNN 网络 AlexNet 一举夺得冠军,且碾压第二名(SVM 方法)的分类性能。也正是由于该比赛,CNN 吸引到了众多研究者的注意。
AlexNet 的创新点:
(1)首次采用 ReLU 激活函数,极大增大收敛速度且从根本上解决了梯度消失问题;
(2)由于 ReLU 方法可以很好抑制梯度消失问题,AlexNet 抛弃了“预训练 + 微调”的方法,完全采用有监督训练。也正因为如此,DL 的主流学习方法也因此变为了纯粹的有监督学习;
(3)扩展了 LeNet5 结构,添加 Dropout 层减小过拟合,LRN 层增强泛化能力/减小过拟合;
(4)首次采用 GPU 对计算进行加速。
结语:作为 21 世纪最具影响力的技术之一,人工智能不仅仅在下围棋、数据挖掘这些人类原本不擅长的方面将我们打败,还在图像识别、语音识别等等领域向我们发起挑战。如今,人工智能也在与物联网、量子计算、云计算等等诸多技术互相融合、进化,以超乎我们想象的速度发展着。而这一切的发生与演变,只用了几十年的时间……