背景
前两天面试一家公司,被问道,如何获取一个网页,找出其中的所有链接,并且得到哪些链接是可以访问的,哪些不可以?
最初,我以为这是一个比较清晰简单的题目,构想了以下步骤:
- 获取整个 html 文档
- 解析整个 html 文档,找出里面的所有链接
- 依次访问链接中的地址,
今天想着做一个试试,却发现这三个步骤做起来,要考虑的东西还是蛮多的。
- 如何获取到整个 html 页面。
- 大部分网页都是由 js 动态生成的,仅通过 net/http 不能获取到完整的 html 页面。这步骤也是最麻烦的,当然,解决方案也有很多,这个帖子汇总的比较全面:https://ruby-china.org/topics/31784
- 如何解析 html 文档。
- 这个就相对的要单纯一点,
nokogiri是一个很容易找到的 gem 包
- 这个就相对的要单纯一点,
- http 请求超时问题。
-
Timeout可以搞定
-
- 多链接请求带来的并发问题。
-
线程是个好东西
-
未考虑到的细节,欢迎大家补充 
代码
贴一段我尝试实现的代码
#ruby 2.4.1p111 (2017-03-22 revision 58053) [x86_64-linux]
require 'timeout'
require 'net/http'
require 'nokogiri' #gem install nokogiri
class Web_crawler
def initialize(url)
@url = url
#存储检索页面各项信息数据
@links = [] #页面链接总数
@success_links = []
@failed_links = []
@timeout_links = []
@invalid_links = []
@forbidden_links = []
@exception_links = []
#记录程序启动时间
@begin_time = Time.now
@timeout = 10 #访问超时设定,单位秒
end
def run
res = open_url(@url)
analysis(res)
print_result()
end
private
#采用线程并发检查各个链接的可达性,并限制线程并发量和链接访问超时时间
def analysis(response)
thread = []
html_doc = Nokogiri::HTML(response.body)
a_lable = html_doc.xpath("//a") #找出所有的<a>标签
a_lable.each{|each_lable|
while true
break if Thread.list.size <= 20 #线程并发量
sleep 1
end
href1 = each_lable.attributes["href"].value
thread << Thread.new(href1) do |href|
@links << href
#本地链接时,补齐url地址
if !(href.include?("http://") || href.include?("https://"))
href = @url + href
end
open_check(href)
end
}
#两倍超时设定,保证所有链接均正常检查完成
Timeout::timeout(@timeout*2){
while true
break if (@success_links+@failed_links).size >= a_lable.size
sleep 1
end
} rescue "遍历异常结束,请检查!"
thread.each{|t| t.kill }
end
def open_check(href)
begin
res = open_url(href)
case res
when Net::HTTPSuccess
##<Net::HTTPOK 200 OK readbody=true>
@success_links << href
when Net::HTTPForbidden
#<Net::HTTPForbidden 403 Forbidden readbody=true>
@forbidden_links << href
@failed_links << href
when Net::HTTPMovedPermanently , Net::HTTPFound
#<Net::HTTPMovedPermanently 301 Moved Permanently readbody=true>
#<Net::HTTPFound 302 Moved Temporarily readbody=true>
@invalid_links << href
@failed_links << href
else
@failed_links << href
end
rescue URI::InvalidURIError
@invalid_links << href
@failed_links << href
rescue Timeout::Error
@timeout_links << href
@failed_links << href
rescue Exception => ex
@exception_links << href
@failed_links << href
end
end
def open_url(url)
status = Timeout::timeout(@timeout) {
response = Net::HTTP.get_response(URI(url))
}
end
def print_result
puts "网址 #{@url} 分析结果:"
puts "共发现链接 #{@links.size} 个."
puts "能成功访问 #{@success_links.size} 个."
printf "访问失败 #{@failed_links.size} 个"
if (@forbidden_links + @timeout_links + @invalid_links + @exception_links ).size > 0
rs = []
rs << "拒绝访问 #{@forbidden_links.size} 个" if @forbidden_links !=[]
rs << "访问超时 #{@timeout_links.size} 个" if @timeout_links !=[]
rs << "无效链接 #{@invalid_links.size} 个" if @invalid_links !=[]
rs << "访问异常 #{@exception_links.size} 个" if @exception_links !=[]
printf "(#{rs.join(",")})"
end
puts "."
run_time()
end
def run_time
time = Time.now - @begin_time
puts "耗时:#{time.to_i/60} 分 #{time.to_i-time.to_i/60*60} 秒 #{((time - time.to_i)*1000).to_i}毫秒"
end
end
begin
web = Web_crawler.new('http://www.sangfor.com.cn')
web.run()
rescue Exception => ex
puts "出现未知异常,程序异常终止!"
puts ex
puts ex.backtrace.join("\n")
end
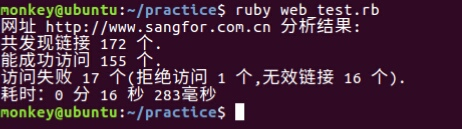
执行结果
无引用文章

