Elasticsearch 通常作为业务搜索的重要组件,或者用于 ELK 做日志分析使用,支持从最简单的全文搜索,模糊/精确搜索,到复杂的组合搜索,还有一些特殊场景下的搜索如地理坐标搜索,甚至可以自己定制搜索脚本来完成自定义的搜索,更重要的是搜索效率非常高。但对于初入者来说,理解 es 的常规使用还是有一定门槛。虽然自己也使用了很久 es,但对使用 es 仅限边边角角的改动,正好前段时间整体重构了一次搜索,顺便把 es 从 2.3 升级到了 5.5,做些总结,应该对新手或是进阶多少有些帮助吧。
前言
本文侧重总结对 es 本身的使用,平时在开发时还是会借助工具来调试功能,比如 sense,有本地版和 chrome 的插件,在调试错误时能更清晰的定位到问题。还有 es 的 web 管理后台 elasticsearch-head,主要用来看 es 数据和调试查询,有了这俩工具,可以像调试数据库一样来调试搜索。
查询表达式
自我感觉对 elasticsearch 使用理解的关键还是在对表达式的理解上。大部分开发者对 sql 的搜索都比较熟悉,但当看到 es 这种缩进式的搜索语句还是一头雾水(至少我入门时是这样的)。es 的搜索采用了 json 结构的查询表达式,所有的查询表达式包裹在最外层的query关键字下,像这样
GET /_search
{
query: YOUR_QUERY_HASH_HERE
}
比起 sql 固定的表达式结构,看起来 json 结构的查询语实在太灵活了,但明确一点:这是个 json 结构的 DSL。每一层的 key 都是有使用规则,错误的查询关键字会导致 ES 在解析查询语句时抛出异常,所以在使用前要多看看官方文档,每种关键字下面可用 options 都有明确的说明,而且在查询文档时一定要确定好自己使用的 es 版本。基于自己常用的一些查询语句画了个图,帮助理解一下 es 搜索语句的结构
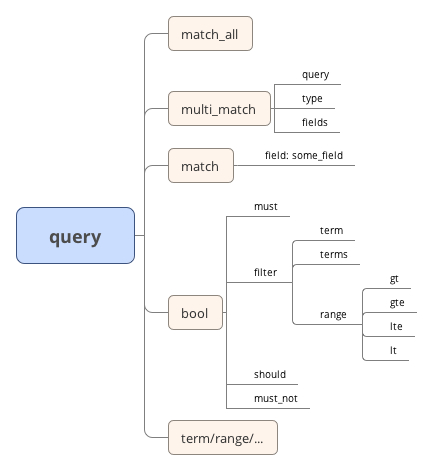
理解 es 的搜索结构,基本可以丝滑的用起来了
SQL like 的搜索方式
习惯了 sql 搜索语句,初见 es 的时候我也是一脸无辜,看起不知道从哪下手,但是类比 sql 搜索之后,发现 es 搜索的结构还是很简单的。
通常使用的查询结构是这样的:
POST /houses/_search
{
query: {
bool: {
must: {
country_id: 123
}
}
}
}
这样的一个语句就类似 sql 中的 House.where(country_id: 123),组合搜索的话,可以参考 一个 2.x 版本的关于组合搜索的中文文档 类似这样常规的搜索就可以完成很多条件的组合搜索,像 sql 一样完成结构化搜索。
查询嵌套
es 的搜索语句很多是可以嵌套的,例如可以在 bool 中嵌套 bool 等等,这样更复杂的嵌套组合语句可以完成更为复杂的搜索。
上面链接里的示例是基于 2.x 的,升级到 5.x 后query不再支持filterd,所以改写成 5.x 的结构就会是这样:
POST /my_store/products/_search
{
"query" : {
"bool" : {
"filter":{ # 同2.x的filterd
"bool": { # 这里嵌套一层bool
"should" : [
{ "term" : {"productID" : "KDKE-B-9947-#kL5"}},
{ "bool" : { # 这里又嵌套了一层bool
"must" : [
{ "term" : {"productID" : "JODL-X-1937-#pV7"}},
{ "term" : {"price" : 30}}
]
}}
]
}
}
}
}
}
关于搜索和过滤
es 默认搜索会给每个结果文档算出一个排序分数,如果只是简单的过滤结果而不需要排序,或是某些过滤条件和结果排序无关,可以把过滤条件嵌套到 filter 中,这样搜索的性能会有所提升(因为不需要算分)。如果只是单纯过滤的话,结果还可以被缓存,增加下一次相同搜索的速度
关于脚本
作为搜索引擎,支持脚本语句给搜索带来了更多可能,完成一些结构化搜索语句难以完成的功能。es 支持的脚本语言有很多种,python, javasript, 还有内建的 groovy,5.x 的 painless 等。5.x 下推荐使用内建的 painless,性能很强大,另外是运行在沙盒环境下,安全性要比其他的要高,语法类似 java 上手还比较容易。
举个例子,找出当前商品折扣价高于 500 的商品,要搜索出这些商品,用一个简单的脚本搜索即可完成:
POST /my_store/products/_search
{
"query": {
"bool": {
"must": {
"script": {
"script": {
"lang": "painless",
"inline": "doc['price'] * doc['discount'] >= 500"
}
}
}
}
}
}
如果不固定是 500,可能是其他值的话,还可以为脚本传参数:
POST /my_store/products/_search
{
"query": {
"bool": {
"must": {
"script": {
"script": {
"lang": "painless",
"params": {
"lowest_price": 500,
},
"inline": "doc['price'] * doc['discount'] >= lowest_price"
}
}
}
}
}
}
因为脚本语句在执行时也需要编译,所以也会消耗一定的执行时间,第二种传参的写法好有个好处,语句中不存在变量时查询语句会被缓存,这样下次执行同样的查询时可以省去编译的时间。
如果使用脚本搜索的话还有几个小建议:
- 尽量选择脚本原生提供的语法支持,某些扩展的语法可能会带来性能问题。比如在 painless 中没有支持 java string 的 split 方法,但可以修改 es 配置开启正则的 split 语法,但在实际使用中发现性能损耗很大,一条执行一百毫秒左右的搜索语句,加上 split 后搜索时间升到七百毫秒左右,所以官方在未支持 split 方法时也指出本身 string 的 split 性能也不是很好,尽量避免使用
- 数组字段的值和 object 类型的字段,在索引中都会打乱顺序,按照 es 的索引顺序去进行索引,可能会导致搜索的结果未按照预期的顺序给出。因为 es 是以 key/value 方式存储索引信息,所以复杂格式类型的字段都会被拍平后按顺序索引起来,比如数字数组 [3,2,1] 在索引中会被索引为 [1,2,3],[{name: ‘a’, age: 12}, {name: ‘b’, age:14}] 这样的信息也会被拍平后索引为 name: [‘a’, ‘b’], age: [12, 14], 从而失去原有数据的顺序或对应关系,在搜索中如果使用类似‘doc.field[1] == 3’或‘doc.field[’name’] == ‘a’ && doc.field[‘age’] == 14’时,搜索结果很有可能是错误的。这类字段只能用来做非顺序或对应关系的搜索
- 在脚本中避免使用
source去搜索原文档,上面提到的问题,其实用souce['name'] == 'a'是可以解决的,但读取原文档的性能也是非常低的,所以不建议使用source去做原文档的查询
最后,一些琐碎的建议:
- 深度使用 es 一定要理解 es 的索引方式,避免误解使用而产生奇怪的问题。es 的字段支持很多基础类型,比如 int/string/boolean 等,如果想要将字段定义为数组类型,只要定义该字段数组中元素的类型即可,因为在存储时字段存储一个和多个值对于 es 来说都是一样的处理方式。某字段如果未指定格式并且存储多个值,es 会以第一个值的格式作为该字段所有存储数据的格式,所以 es 的数组字段不支持存储不同类型的值,如果存储了不同类型的值,es 会尝试去转换值存储,一旦转换失败则会抛出异常
- Rails 集成 es 也有很多好用的 gem,比如 Searchkick可以像写 sql 一样做 es 搜索,或者干脆使用 jbuilder 等工具手撕搜索 json,不管哪种工具,了解 es 才是重中之重
- es 更新换代很快,选好版本,看好文档别出错。前一年才升级到的 2.3,转眼间已经到了 5.5。使用 5.5 开发完成后,发现 6.0 也出来了,在查文档时,发现 5.6 文档中 script 的 inline 关键字变成了 source,调试时没注意到小版本改动踩了个小坑,不禁感慨世界变化太快。。。看文档一定得注意完整版本号
到此!
 受用了
受用了