Data Service 是我们团队对前后端数据进行管理的中间层,它是在我们进行前后端分离过程中产生的数据共享实践。Data Service 在团队中的广泛应用,显著提升了系统性能以及大家的开发效率。
项目演进背景
我们团队维护的主要业务是 PC 商品导购平台,该项目在过去几年,经历了从一个很小的 rails 单体项目,演进为一个综合的大型互联网系统。前后端分离正是出现在这个演进过程中的一次拆分。我们在展示层架构上的技术选型是 Node.js KOA 框架,主要期望达到的效果:
- 将展示层代码迁移到 node 项目,前端同学直接管理 view 层。
- 利用 node.js 扛直接用户压力,系统日常 pv 百万级,大促可能飙到千万级,node.js 的异步 IO 是一个不错的选择。
- KOA 利用了 ES6 的 generator, 可以使用同步的语法写出异步的操作,因此 javascript 的回调金字塔也不是问题。
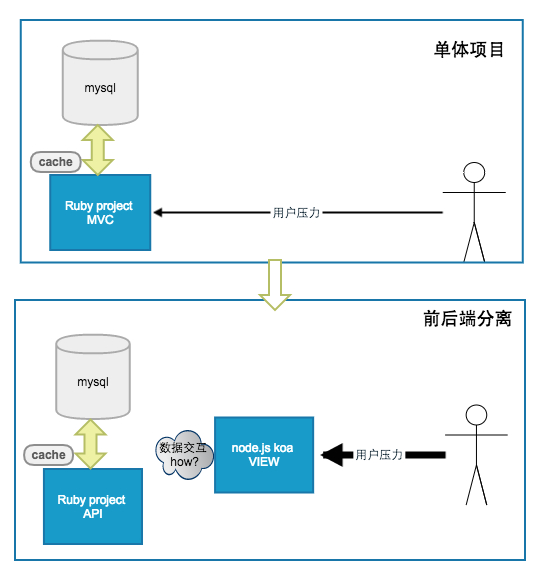
虽然 node ES6 的语言表现力仍然远不及 ruby, 不过在以上的特定领域,这套架构还是取得了预期的效果。技术选型、项目管理都充满了权衡,就看当前阶段你更想要什么。
问题
在前后端分离过程中,我们面临最明显的问题是前端如何获取数据,摸索期我们有尝试过的交互方式有:
- node.js 直接查询 mysql
- ruby 提供 http 接口供 node.js 查询
- 后端提供 thrift 接口供 node.js 查询
nodejs + ORM
先说 node 直接查询 mysql, 我们采用的 ORM 框架sequelize, 我们都很熟悉 Rails 的 ORM 框架 Activerecord, 想着在 node.js 里用 ORM 也是 so easy, 不过实际使用时我们还是遇到了很多问题。
关系型数据库管理的数据关系和程序真实操作的数据结构之间有较大的差异,关系型数据库的数据无法直接表示对象、列表、嵌套等结构,这种差异叫做阻抗失衡(Object-relational impedance mismatch), ORM 正是对阻抗失衡进行结构转译的技术。不过 ORM 框架本身的问题在于性能,在使用 ORM 时,开发同学必须十分了解 mysql 结构,具体字段有没有索引,mysql 数据量有多大,会不会造成慢查询等。然而 node 项目的维护者主要是前端同学,他们在数据库的使用技术上有较大的缺口,最后前端同学要么逼疯要么逼成全栈。
不仅前端不满意,后端同学对 sequelize 的语法也不满意,这主要也是受限于 javascript 和 ruby 的语言表现力的差异,就好比之前你熟悉了用锯子砍树,现在给你一把剪刀,你能满意吗?
http/thrift
也有的数据查询采用 http 交互,ruby 项目变成一个 api 服务。这种实现有以下问题:
http 数据传输效率不高,相对于 tpc, 处于应用层的 http 传输作为内部 RPC 有天然的缺陷:文本格式,元数据 (header) 比重太大,需要 dns 等消耗。
http 不稳定,容易受网络抖动等影响,对于内部 RPC, 重试,缓存等都需要代码自己考虑。
那么换成thrift如何?thrift 是跨语言的 RPC 框架,采用高效的二进制通讯协议,在应用场景上很适合这种多语言的系统,然后 thrift 的应用也有一些问题:
- 前端对 thrift 不熟悉,学习成本。如果整个团队都是全栈那就没问题了。
- thrift 作为面向服务框架,只有 RPC 调用功能,没有提供 RPC 治理功能,如监控,统计等,这些需要自行实现。
因为缺乏标准,一时间,前后端的数据查询进入了群魔乱舞的阶段,mysql, http, thrift 同时存在,项目耦合严重,系统不稳定,频繁告警。
Data Service 设计
上面花了大量的篇幅来说明背景和问题,其实系统的优化往往是这样,如果真的清楚了系统的痛点,那么离解决问题并不远。怕的是没有认识到问题和系统可优化的空间。
结合代码分析
通过分析前后端项目的业务代码,我们发现在涉及数据查询的代码中,大家都在做这样一些判断和操作:
Ruby 项目同学:
- 通过什么方式提供给前端同学,如果是 http/thrift, 就需要去编写具体的接口,如果是 mysql, 就需要告诉前端同学数据结构,如何查询,有时还得帮前端同学写好 sql.
- 后端要不要缓存,缓存到哪里,key 是什么,前端同学会进行缓存吗。
- 前端同学需要什么样的数据格式。
- 将持久化数据的数据组合为前端需要的格式
Node.js 项目同学:
- 从哪里获得后端数据,涉及的 ip, port, url, 参数等,是否之前有缓存。有的数据可能还是从多个后端获取。
- 从后端获取数据是否成功,如果失败了是否要重试,或者是否有备份数据提供展示。
- 获得的数据是否要缓存,缓存要缓存多久,缓存到哪里,缓存的 key 叫什么。
- 拿到业务数据后,如何展示。
各项目有大量和业务无直接关系的控制代码。后端同学其实只关心「将持久化数据的数据组合为前端需要的格式」, 而对于维护 view 层的前端同学来说,他们其实只关心「拿到业务数据后,如何展示」, 而在 data service 出现之前,以上逻辑在 node 项目中随处可见,展示层关心了太多数据的逻辑。
结合业务分析
用 rails 的 REST 术语来说,电商平台最常见的 view 形式是 list 页面和 show 页面。list 代表一类资源的列表,如商品列表,评论列表,购买列表。show 页面代码一个具体的资源实例,如 id 为 100 的商品。以上两类抽象数据占据了前后端数据查询的绝大部分。因此我们把前后端的数据抽象为 2 种情况,实例型和关系型:
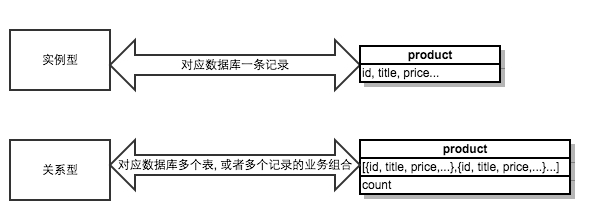
其中实例型数据代表一个资源实体,它和数据表中的一条记录一一对应,在查询时,需要提供一个资源标识和 id 标识,典型的 url 是/:resource_name/:id, 如/products/100;
我们对关系型数据的定义是:除了实例型以外的数据。它代表一类相关资源,可能对应后端的一张表,也可能是多张表中的某些数据。在查询时,只需要提供一个资源标识,典型的 url 是/:resource_name, 如/products, 这样的定义有点类似 nosql 中的聚合关系。
Show me the Code
设:mysql 有 1 个表 products(商品):
| id | title | price(单位是分) | ... |
|---|---|---|---|
| 123 | Ruby 元编程 | 6880 | ... |
| 456 | 深入浅出 Node.js | 6900 | ... |
| ... | ... | ... | ... |
Rails 中的 ActiveRecord 数据模型:
# app/models/product.rb
class Product < ActiveRecord::Base
.......
class << self
def top_products_by_sales(count)
# 查询销量最高的count个商品
......
end
end
end
如果前端展示层需要 2 个页面:
- 展示销量 top 10 的商品页面,同时显示所有商品的个数。
- 在上面的页面中点击具体商品,进入商品详情页,详情页需要展示商品的 title 和价格,价格展示单位是元。
来看看引入了 Data Service 后,Ruby 和 Node 项目中的需要增加的代码是怎么样的:
ruby 项目代码:
# lib/data_service/product.rb
class DataService::Product < DataService::Base
self.expire_time = 10.minutes
self.json_attributes = [:id, :title, :price]
def price
Util.fen_to_yuan(model.price)
end
class << self
self.expire_time = 30.minutes
self.json_attributes = [:top, :count]
def top
model.top_products_by_sales(10)
end
end
end
node.js 项目代码
let dataService = require('node_data_service')
// 单实例型调用, 返回对象
let product = yield dataService.fetch({model: 'products', ids: 123})
// => {id: 123, title: 'Ruby元编程', price: 68.8}
// 多实例型调用, 返回数组
let products = yield dataService.fetch({model: 'products', ids: [123, 456]})
// => [{id: 123, title: 'Ruby元编程', price: 68.8},
// {id: 456, title: '深入浅出Node.js', price: 69} ]
// 关系型调用, 以下2种方式完全相同
let topProducts = yield dataService.fetch({model: 'products', ids: 'relation'})
let topProducts = yield dataService.fetch({model: 'products'})
// => {
// top: [{id: 123, title: 'Ruby元编程', price: 68.8}, {id: 456, title: '深入浅出Node.js', price: 69} ...],
// count: 23
// }
以上基本是就是这一次业务需求中,前后端 2 个项目在数据交互上需要添加的全部代码! 在前后端同学商量好需要的数据定义后,后端同学只需要实现数据如何查询和组装,前端同学通过一句简单的 yield 后,可以把所有精力都放到如何展示数据 json 上。他们的代码都不涉及写接口,缓存,查询失败的逻辑,这些都是 Data Service 框架完成的事情。
Data Service 实现
Ruby 语言的 API 设计非常简洁优雅,不过在简洁设计的背后有大量复杂的实现作为支撑。DataService 的目标之一,也是希望能提供一套简单易用的 API, 隐藏大量在数据交互中重复逻辑,让前后端同学各司其职,把精力放在具体业务的实现上。
Data Service 实现的通用功能包括:
- 采用 redis 作为前后端的统一数据缓存,后端异步更新数据,前端直接查询的是 redis, 高效且稳定。
- Ruby 项目作为数据维护方,Data Service 维护了统一的 redis 数据结构,这是前后端数据交互的约定结构,对于新的业务逻辑,前后端同学不需要花太多时间去讨论数据结构,只需要明确需要哪些模型,是实例型还是关系型。
- 提供了统一的容错机制 (http miss 接口), 解决如果缓存里没数据怎么办的问题。
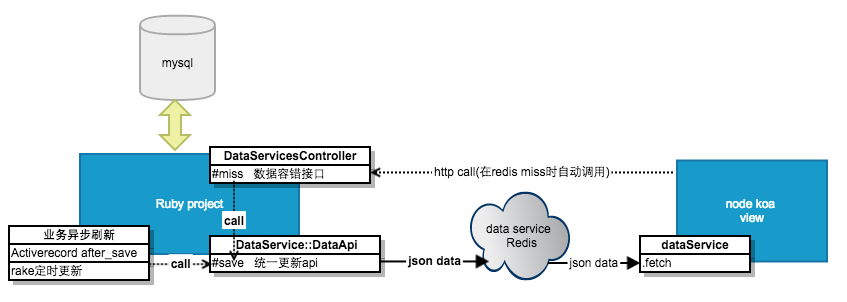
Ruby 端 DataService::Base 实现
我个人非常喜欢 Ruby 中「类也是对象」的设计,这似乎是一种能治愈强迫症的设计:
class Person
# 这个作用域定义的方法、配置等, 是针对Person实例, 比如张三, 李四
class << self
# 这个作用域定义的方法、配置等, 是针对Person这个类对象的
end
end
个体和集合这样的关系,在 ORM 领域和 RESTful 领域也有相似的对应关系:
实例对象 <--> 类对象
关系型数据库record <--> 关系型数据库table
show页面 <--> list页面
而在 Data Service 的设计中,我也把所有的数据抽象为了个体/集合这样的关系,用DataService::Base的子类代表一种实例型数据,用DataService::Base的子类的singleton_class代表一种关系型数据:
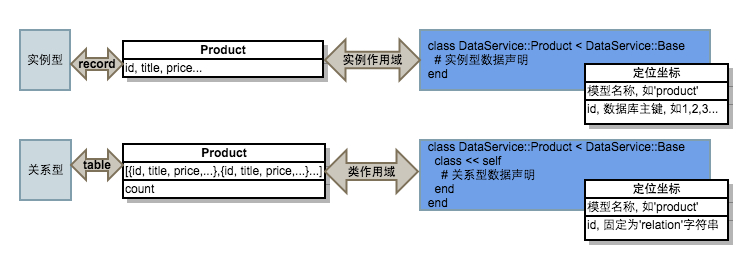
在 Data Service 中,实例型数据的定位方式是模型名称+id, 关系型数据的定位方式也是类似,只是 id 是固定的字符串'relation', 关系型数据可以认为是一个特殊的实例型数据,就类似 Ruby 中 Class 是一个特殊的 Ruby 对象。
这样设计的一个好处是统一 API, Ruby 中类也是一个对象,那么类对象和类的实例,会有一些相同的 API, 比如Object#to_s; 而 Data Service 中实例型数据和关系型数据都有设置缓存时间的需求,因此也有相同的 APIexpire_time. 其他相同的 API 还有cache_key, save等:
class DataService::Product < DataService::Base
### begin 实例存储 ##################################################
# 实例缓存存储时间
self.expire_time = 10.minutes
# 可选设置, 默认是当前的class对应的顶级ActiveRecord Model, 用于和数据模型关联
# self.model_class = ::Product
# 可选设置, 默认是当前的class的小写形式, 最后存到redis的将是 'data_service:#{cache_key}:#{model.id}'
# self.cache_key = 'product'
# 前端需要的数据内容, 每一个属性都需要一个对应的方法
# 方法优先在DataService::Base对象上查找
# 如果找不到会委托到对应的Activerecord模型上查找
# 这个例子中, price在下方定义了, id和title将委托到对应的AD模型上
self.json_attributes = [:id, :title, :price]
def price
Util.fen_to_yuan(model.price)
end
## 当调用DataService::Product.new(some_product.id).save 会更新redis实例数据
## 将在redis中存储'data_service:product:#{model.id}' 为 {id: ..., title: ..., price: ...}
### end 实例存储#####################################################
class << self
### begin 关系存储##################################################
# 关系型数据有和实例数据同样的设置API:
self.expire_time = 30.minutes
self.json_attributes = [:top, :count]
# 可选设置, 默认是当前的class对应的顶级ActiveRecord Model, 用于和数据模型关联
# self.model_class = ::Product
# 可选设置, 默认是当前的class的小写形式, 最后存到redis的将是 'data_service:#{cache_key}:relation'
# self.cache_key = 'product'
def top
model.top_products_by_sales(10)
end
## 当调用DataService::Product.save 更新关系数据
## 将在redis中存储'data_service:product:relation' 为 {top: [...], count: ...}
### end 关系存储配置#################################################
end
end
Ruby 普通对象和 Ruby 类对象的统一 API 大部分来自模块Kernel, Data Service 中的实例型和关系型的统一 API 同样来自一个模块DataService::DataApi, 感兴趣的同学可以查阅第一版DataService::Base实现:base.rb
除了统一 API, DataService::DataApi还实现了对声明的json_attributes的实现查找,默认它会在对应的 Activerecord 模型上查找,但是你可以在DataService::Base对象上进行覆盖,比如上例中,实例数据的属性id, title是在 Activerecord 模型的实例上获取的,DataService::Base中的price覆盖了 Activerecord 模型上默认的price方法。
Node.js 端 dataService.fetch 实现
Node.js 端的实现比较简单,npm package dataService 对外 export 唯一方法 fetch, 前端同学通过此方法获取实例型和关系型数据。
该方法首先查询 redis, 前端同学无需关心 redis 的数据解析,fetch 会将数据解析为期望的 json. 如果 redis 里没有数据将会自动调用 Ruby 提供的 miss 接口,不过这些逻辑都是隐藏在 fetch 之下的,前端同学不用关心。
/**
* 通过传入资源 id 数组, 获取对应的deal的属性
*
* @public
* @param {Object} query 查询信息对象
* - model: 字符串, 必要参数, 表示数据模型, 按照约定, 应该全部小写
* - ids: 字符串, 数字, 数组, 资源标识
* @param {Object} 可选参数
* - cacheOnly 如果为true, 表示只走缓存, 不会触发miss
* - ns 表示namespace
* @returns {Array/Object} 对于批量查询, 返回数组, 对于单个查询, 返回单个对象
* @throws {Error} dataService 错误: model为空
* @throws {Error} dataService 错误: ids为空
* @throws {RedisError} Redis 超时或者错误
*/
dataService.fetch = function* (query, options) {
......
总结
系统收益
- 项目解耦
引入数据中间层,Data Service 是 mysql 数据到项目实际需要的数据结构之间的转译,类似单体项目中的 ORM 的作用。
前端 View 层解除了对 mysql 和后端接口的强依赖,即使 mysql/后端服务在短时间内挂掉 (真实发生过多次), Data Service 也是有缓存数据可供前端使用 (View 展示正常,可能数据有点旧).
- 约定大于配置
Data Service 提供了默认的数据定义,默认的 Data Service 模型和 Activerecord 模型的对应关系,默认的 redis 存储结构,默认的 miss 容错机制。前后开发同学只需要把精力放到每次的业务实现上,不用重复考虑和实现这些通用的功能,这就是约定的好处。
- 缓存异步刷新,高效且稳定
Data Service 将数据写入缓存和前端读取缓存完全解耦,使得后端可以异步对缓存进行刷新,比如上面的 Product 实例型数据,后端同学可以在Product.after_commit中调用DataService::Product.new(product.id).save进行缓存刷新,也可以通过 rake 定时刷新。
缓存异步刷新的好处使得前端始终有可用的数据,也不会出现雪崩现象,以下是某页面接入 Data Service 后的效果,TP99[^注 1] 显著降低,可用性[^注 2] 明显提高。

其他
- 数据抽象为关系型数据和实例型数据,灵感来源于 Ruby 的「类也是对象」
- 这是一套小成本的优化:核心代码仅几百行; Redis 在前后端中已经广泛使用,没有引入新的中间件和复杂的概念; 简单统一的 API、出色的性能让系统推广十分顺利。
- Data Service 项目目标是统一管理 view 层可缓存的数据,大部分系统都是读多写少。对于推荐系统、用户签到、购买等写逻辑的数据流需要另外处理。
[^注 1]: TP99: 关键的性能指标,所有请求响应时间降序排列,去掉 1% 的最高耗时,剩下 99% 的请求中的耗时最大值。
[^注 2]: 可用性:关键的性能指标,HTTP 状态码 4XX, 5XX 以及响应时间超过 5s, 属于不可用,剩下的所有请求属于可用请求。