分享人: 陈海泉,青云 QingCloud 系统工程师
大家好,我是 QingCloud 的工程师陈海泉,今天给大家分享一些 SDN/NFV 2.0 架构的网络技术。
首先,说一下什么是 SDN,SDN 就是软件定义网络。当然也不是所有网络定制一定要软件来实现,因为有很多硬件方案也可以做到 SDN 的效果。
青云 QingCloud 用软件定义来实现虚拟网络,我们 2013 年的时候,在公有云上线了第一代产品。当时 SDN 还是一个比较新鲜的事情,用户用的还比较少,随着用户量越来越大,私有网络里面的 VM 数量超过一定的数量级的时候,我们发现性能就有一个比较大的损失,已经无法满足用户的需求。所以我们在去年下半年的时候,花了很大功夫去做 SDN/NFV 2.0 的事情。
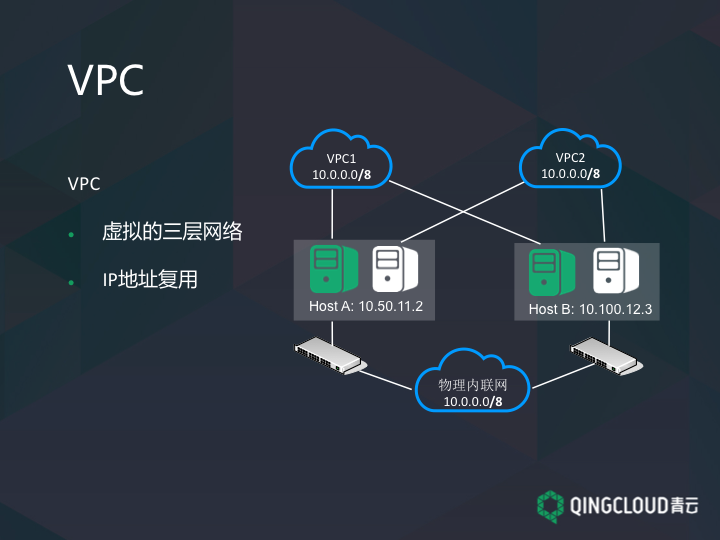
VPC 是什么意思呢?VPC 网络是 QingCloud 环境内可以为用户预配置出的一个专属的大型网络。在 VPC 网络内,用户可以自定义 IP 地址范围、创建子网,并在子网内创建主机/数据库/大数据等各种云资源。

正是因为云计算需要虚拟网络,也需要 VPC。所以我们还需要定义一个 SDN 方案解决这两个需求,现有的 SDN 方案主要分成两个方向:
一是用软件来定义,但是用硬件来实现。比如某些带 SDN 功能的交换机,把它采购进来,部署到产品里,用硬件厂商提供的 API,在上面提供 SDN 功能。
二是 NFV,就是网络功能虚拟化,用软件的方式来实现,用软件的交换机和路由器,把他们组织起来成为一个软件实现的 SDN。其代表有 VMware NSX、Juniper OpenContrail 等等。

QingCloud 在 SDN 方案的选型上也做过讨论,用软件还是用硬件方案?其中考虑的问题主要是以下三个方面:
- 第一,成本。在公有云上面大家拼的是成本,谁的硬件成本低,谁就能把价格降到最低。如果我们采用现有的硬件方案,在网络设备上面增加了很多投资,并且我要采购的不是一个或者两个,而是一批。
- 第二,设备依赖。我们的私有云卖的是软件,客户可以按照偏好选择自己的硬件,假如 QingCloud 的 SDN 绑定了某款硬件产品,那我们在面对用户的时候,可能连招标的机会都没有,因为人家压根就没有办法用你的硬件。
- 第三,情怀。对于工程师来说,大家都想把产品做得更优秀。其实,软件跟传统快递行业非常的接近,为什么这么说。因为网络中的交换机、路由器,其实跟快递行业里的快递员和包裹集散中心非常相似,一般包裹给快递员以后,快递员会发给一个快递集散中心,这里可以查询包裹应该被送到哪个地方,然后再将包裹交给快递员,送到用户那里。顺丰在中国应该是最好的快递公司之一,因为它把转运环节都做全了,只有方方面面都能够控制才能实现压倒性的优势。因此,我们如果把数据包转发的每个流程都控制到,就有可能在系统上面做到最优,采用硬件设备使用这些功能的话,最后带来的是同质化,跟竞争对手相比不会有任何的优势。
综合以上三方面的原因,我们决定开发一套新的 SDN/NFV 2.0 方案,取代 1.0。

既然定了要自己做一套新的方案,怎么去实现?我们做了一些总结,新的产品需要满足传统 SDN 的需求。第一,数据封装。也就是实现一个基本的虚拟网络;第二,实现控制平面。二层、三层的网络数据进行路由规则的同步,然后下发到虚拟的交换机和路由器里面去,控制做到 ARP 泛洪抑制;第三,实现数据平面。除了 DVR 之外,还提供了虚拟边界路由器。

除此之外,还需要增加我们需要的 2.0 方面的功能。
- 第一,VPC 主机直接绑定公网 IP。私有云用户大量依赖基础网络,要求 VM 直接绑定公网 IP;
- 第二,负载均衡器。可对进入流量进行分流,出流量经由多台 Virtual Gateway (虚拟网关) 分担负载,单 IP 可承载 1 TB 出流量。同时,4—7 层完全透明;
- 第三,IP 不变。支持可以无限水平扩展的基础网络,并保持高可用及高性能,VM 任意迁移,IP 地址保持不变;
- 第四,VPC 和物理网络连接。
下面分别解释刚才说的那几个基础实现。
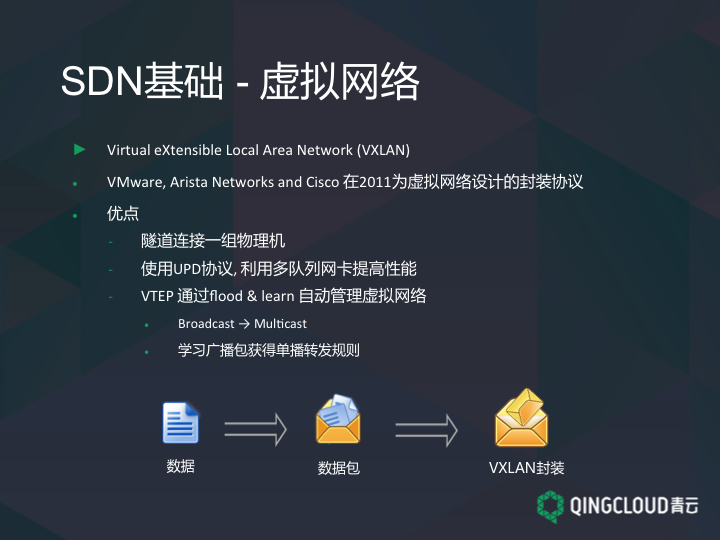
首先解释虚拟网络。在一些大公司里会提供一种叫内部邮递的服务。公司员工之间可以发送一种快递,比如要给财务部门某同事发一个报价单,会查他的工位,知道他坐在哪,比如 184-323-534。然后准备一个大信封,把要填的单子放在里面。我不需要知道这个人是在北京,还是在上海,我把这个信封交给公司的收发室,这个收发室会对这个信封进行重新封装,因为他有此员工的具体地址,然后把具有新地址的信封交给外包快递公司。放到云计算里,这就是一个虚拟网络。可以允许用户自己定义一个地址,然后进行传输,为了让它在三层网络里传输,可以再进行封装,再套一个包,写上新的地址。根据外包的内容和里层包的内容把这个数据包发送到对应的信息那里。
虚拟网络依赖于拆包、分包。现在采用的方案主要是比较流行的 VXLAN,因为 VXLAN 有一系列的优势。第一,隧道连接一组物理机,由于 VXLAN 的数据包在整个转发过程中保持了内部数据的完整,因此 VXLAN 的数据平面是一个基于隧道的数据平面;第二,使用 UPD 协议,当数据包交给网卡的时候,网卡根据这个数据的包头,用不同的网卡队列。这样把包交给不同的 CPU 处理,提升性能;第三,是比较有争议的 Flood & Learn 自动管理虚拟网络,VXLAN 可以进行泛洪学习,当 VTEP 收到一个 UDP 数据报后,会检查自己是否收到过这个虚拟机的数据,避免组播学习。
通过以上几点,我们觉得 VXLAN 不错,但是仔细的去想,就发现它有两个非常大的不足。一个是组播协议,大规模部署会受硬件设备组播路由限制;第二,泛洪学习的机制,会把原来在二层广播的 ARP 包扩大到三层网络,这样随着规模扩大,广播越来越多,会严重的浪费带宽资源。所以,我们既要使用 VXLAN,又要消灭它的不足,所以我们设置了 SDN 控制器,通过我们自己设置的规则,取代它自有的泛洪学习规则。
那么这个控制器需要多少个呢?我之前曾经了解过一些用户生产环境里用到的控制器,通常只有一个。它负责整个集群中所有节点的规则,这么做造成一个问题,当集群创建、销毁、迁移的时候,需要把规则同步到整个集群所有的节点中,这样随着用户秒级创建资源的需求,同步规则的流量就会相当相当大。所以我们做了一个分布式控制器,不仅把控制器分布到 VPC,还分布到虚拟网络里头。每个 VPC 有 253 个虚拟网络。

刚才说了虚拟网络和控制器,第三点 SDN 需要做的就是控制数据平面,其作用就是把数据包真的从一个地方拷贝到另外一个地方。传统的数据平面,比如 OpenStack 通常会用 OVS,OVS 会有一个问题,它会把数据交给另外一个程序,这样会带来一个性能的下降,而我们的方案完全改变了这个问题,自己做了一些 Kernel 的改动,将转发放到 Linux Kernel 上,而且我们是用 NFV 来实现的。
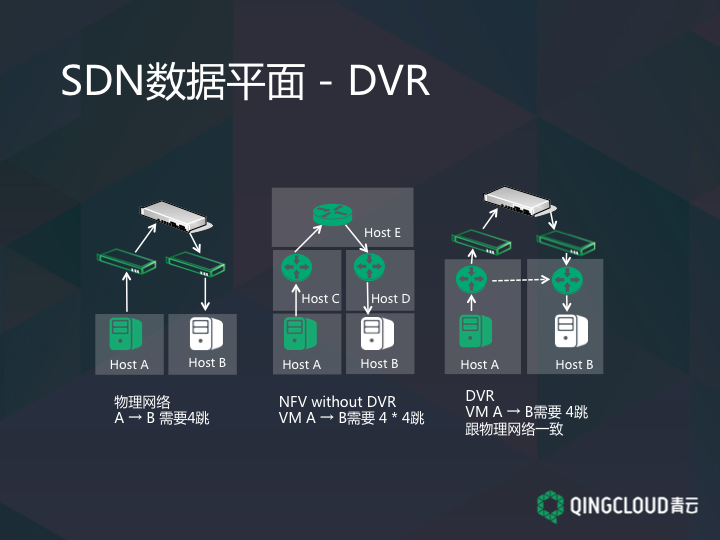
同时我们引入了一个新的功能叫做 DVR(分布式虚拟路由器)。通过上面的图解释一下我们为什么需要 DVR。左边是这张是物理拓扑图,物理世界中 A 和 B 通信,需要把信息发送到 A 的交换机,然后到路由器,然后路由器转给 B 的交换机,B 的交换机再发送给 B,A 和 B 通常需要 4 跳才能发一个数据包。
我们 1.0 的时候,也是用 NFV 实现的 SDN,我们会模仿物理世界,虚拟出虚拟的路由器和交换机提供给用户。如果 A、B、C、D、E 这五个设备分别位于五个不同的虚拟机上,在逻辑上 A 的包经过 C、E、D、B 才能到,逻辑上是四跳。但是虚拟设备每一跳都要通过物理设备去交换,而物理设备每一条四跳,这样总得转发量实际上需要 16 跳。这也就是为什么 1.0 的性能总是上不去。为了解决这个问题,我们引入了 DVR,从 A 到 B 还是这样,两个 DVR 之间直接交换一下数据就可以了,因为在逻辑上有一跳,所以总数跟原来物理设备一样,四跳完成一个数据包的转换,这样性能就可以非常接近物理机的性能,从而可以组成一个大的虚拟网络。
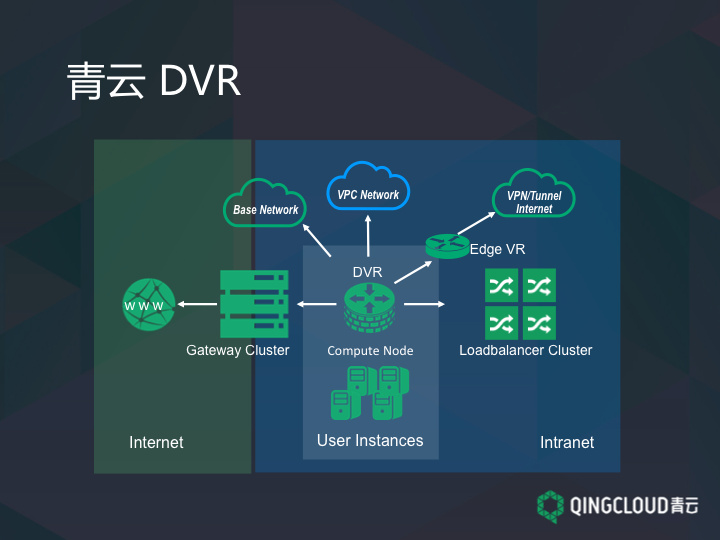
QingCloud 的 DVR 除了实现 VPC 简单的功能之外,它实际上是一个复杂的东西。因为除了保持自己跟自己的虚拟网络,还需要有其他四个方向:第一个就是网关需求,我们需要提高公网 IP 存储量,希望 DVR 把包发到公网网关;第二是 VPC 的虚拟机要能跟硬件设备进行高度的互访。因为我们私有云用户的机房里,不止有 QingCloud 的东西,还有 Oracle 的数据库、F5 的路由器等等,假如我们让用户把这些业务放到虚拟网络里,虚拟网络就要跟硬件网络进行高速的互访。第三是 VPC,可以让用户定义 255 个 C 段,加起来可以有 60000 多个虚拟机。第四是,我们还提供了一个边界路由器,可以让用户虚拟资源跟远程的 IDC 之间做一个互通。最后一个就是一个负载均衡器集群,我们的 DVR 就是一个平台,让用户的主机和负载均衡器直接相连。
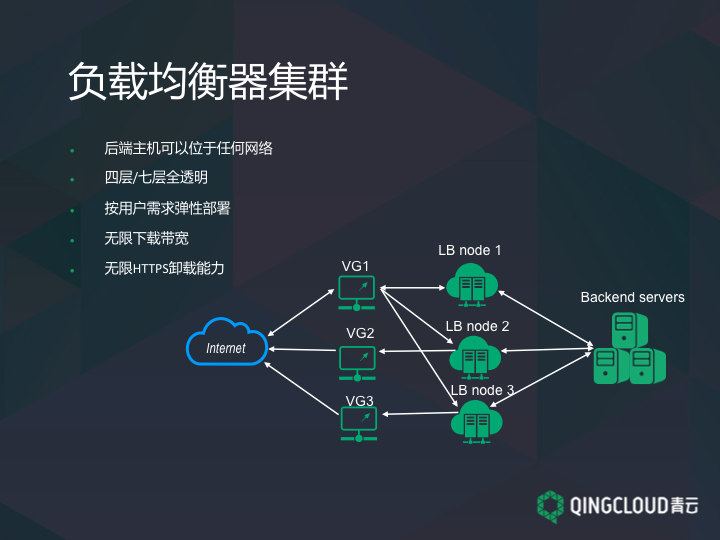
我们做的最后一个功能就是负载均衡器集群。设计是这样,我们有一个网关集群连着因特网。比如我有一个 IP 1.1,实际上是绑定在 VG 1 这里,VG 1 会做第一次的流量转发,会把流量按照用户定义的负载均衡器节点数量转发到自己私有的负载均衡器节点里(1、2、3),它的特点就是,返回流量不需要经过进来的这个网关,而是经过自己对应的不同物理网关发送到因特网。因为当 VG 1 能力受到限制的时候,假如我们所有流量都从它回去的时候,它自己的网络带宽实际上就是整个集群的能力。而我们把它分散之后,就可以做到,出去的流量几乎是没有限制。只要我们的 VG 设备有多少,它的带宽就会有多少,因为流量不需要从默认的线路回去。同时随着用户拓展负载均衡器节点的数量,也扩展了 HTTPS 的卸载能力,并且我们做到了 4 层/ 7 层的完全透明,也就是说用户通过因特网访问到他们业务的时候,我们在所有转发过程中,都会保留其原地址,用户这边得到的包是直接来自因特网用户的 IP 地址。