先来一段看起来非常好使的代码:
def self.page_check
pages = Pages.pages #读取配置文件中页面的地址
pages.each do |page|
begin
timeout(30) do
begin
RestClient.get("http://#{@@domain}#{page}"){|respose|
if respose.code != 200
puts "页面检测失败,页面地址为:http://#{@@domain}#{page} 状态为#{respose.code}".colorize(:red)
else
puts "页面#{page}检测通过".colorize(:green)
end
}
end
end
rescue TimeoutError
puts "页面检测超时,页面地址为:http://#{@@domain}#{page}".colorize(:yellow)
end
end
这段代码的作用就是检查网站的页面,在更新时用来检查是不是所有的页面都可用。
看起来好给力的样子,有 http 状态码检查,有超时控制,似乎非常完美了,然而,这段代码跑起来经常因为超时错误而中断,是的,你没看错,超时!!!代码中明明有捕获超时异常并且处理的代码,但脚本却因为超时而中断
报的错误日志如下:
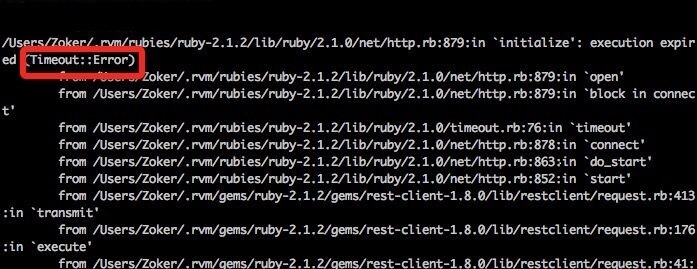 百思不得其解,然后使劲翻文档,翻官方解释,最后总结出 ruby 的 timeout 针对的是代码块,也就是说整个 timeout 作用范围的代码加起来只能运行设定的时常,超过了才会报错误,但是,如果说代码块中某一句在还没到设定时间时报了超时,那么异常还是异常,timeout 并不给予处理,比如本段代码中使用到了 restclient 这个 gem 包,他报的超时 timeout 并不会处理,而是如实的打印出来并终止程序,这也就是明明我们设定了 timeout 但还是报超时异常的原因
而对于这个问题的原因,结合官方文档,给出如下猜测:ruby 的 timeout 是通过线程实现的,他将设定的代码块弄到一个线程里去执行,然后本身暂停,等待设定的时间到比如 5 秒钟后取检测这个线程还在不在,如果还在就报超时并干掉这个线程,不在了就正常执行(注意,也可能是 timeout 是线程,代码块是主进程,这个观点来源于猜测,不具备权威性)。所以对于这段代码报超时的问题,我们不能再指望本身的 timeout,结合错误日志,很明显,超时的是 restclient,所以应该给 restclient 设定一个超时时间,然而,对 restclient 设定 timeout 是不现实的,因为 ruby 的 timeout 并不会管代码本身如何,他只会判断代码还有没有在执行,故只能在 restclient 上设定超时,当然,如何设定 restclient 的超时时间那是另一个问题了,本文讲的是 ruby 的 timeout,所以这里不再讲 restclient 的 timeout
当然,具体的指明 ruby 的 timeout 运行机制以及代码阅读我就不参合了。
所以,ruby 的 timeout 在有网络请求的时候就是一个坑啊!!!
好吧,我知道有点水,新人第一次发帖,如果帖子有问题麻烦管理员帮忙编辑调整一下
百思不得其解,然后使劲翻文档,翻官方解释,最后总结出 ruby 的 timeout 针对的是代码块,也就是说整个 timeout 作用范围的代码加起来只能运行设定的时常,超过了才会报错误,但是,如果说代码块中某一句在还没到设定时间时报了超时,那么异常还是异常,timeout 并不给予处理,比如本段代码中使用到了 restclient 这个 gem 包,他报的超时 timeout 并不会处理,而是如实的打印出来并终止程序,这也就是明明我们设定了 timeout 但还是报超时异常的原因
而对于这个问题的原因,结合官方文档,给出如下猜测:ruby 的 timeout 是通过线程实现的,他将设定的代码块弄到一个线程里去执行,然后本身暂停,等待设定的时间到比如 5 秒钟后取检测这个线程还在不在,如果还在就报超时并干掉这个线程,不在了就正常执行(注意,也可能是 timeout 是线程,代码块是主进程,这个观点来源于猜测,不具备权威性)。所以对于这段代码报超时的问题,我们不能再指望本身的 timeout,结合错误日志,很明显,超时的是 restclient,所以应该给 restclient 设定一个超时时间,然而,对 restclient 设定 timeout 是不现实的,因为 ruby 的 timeout 并不会管代码本身如何,他只会判断代码还有没有在执行,故只能在 restclient 上设定超时,当然,如何设定 restclient 的超时时间那是另一个问题了,本文讲的是 ruby 的 timeout,所以这里不再讲 restclient 的 timeout
当然,具体的指明 ruby 的 timeout 运行机制以及代码阅读我就不参合了。
所以,ruby 的 timeout 在有网络请求的时候就是一个坑啊!!!
好吧,我知道有点水,新人第一次发帖,如果帖子有问题麻烦管理员帮忙编辑调整一下