新手问题 为何调用的方法没生效?
场景:将一个包含很多二级域名的文件,解析出来第一条记录。以谷歌地图为例,格式化的输出 map.google.com maps。
~ dig map.google.com
;; ANSWER SECTION:
map.google.com. 2400 IN CNAME maps.google.com.
maps.google.com. 299 IN A 216.58.221.110
代码:
# /usr/bin/ruby -w
# coding:utf-8
# dig the domain banding in UPYUN
# https://github.com/bluemonk/net-dns
require 'net/dns'
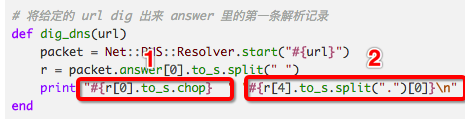
# 将给定的 url dig 出来 answer 里的第一条解析记录
def dig_dns(url)
packet = Net::DNS::Resolver.start("#{url}")
r = packet.answer[0].to_s.split(" ")
print "#{r[0].to_s.chop} " "#{r[4].to_s.split(".")[0]}\n"
end
# 将泛域名里面的 * 替换成 test,以符合域名解析规则
def subt(str)
if str.include? '*'
puts str.sub('*','upyun')
else
puts str
end
end
# 包含域名的文件作为参数输入
filename = ARGV[0]
# 遍历文件中的 url,然后格式化的输出
File.open(filename,'r+') do |f|
f.each do |line|
line.split(" ").each {|s|
dig_dns(subt(s))
}
end
end
疑问:在最后一个部分 dig_dns(subt(s)) 中 dig_dns 方法没有生效,结果输出的还是单个 url,请问问题出在哪里呢?