Puma 的集群运行模式
Puma 集群的运行时结构
以集群模式启动的 Puma 服务器会有一个进程是 master 进程,然后有多个 worker 进程。Master 进程是通过 fork 的方式创建 worker 进程的,所以 master 进程是主进程,worker 进程是子进程。进程间通信采用的是 pipe 机制,每个 pipe 都是一对有两个元素的 io 对象,其中一个 io 对象只用于写,另一个 io 对象只用于读。
要理解集群的运行,一定要先理解 pipe 的工作原理,其官方文档在ruby pipe.
Puma 的运行时结构如图所示。
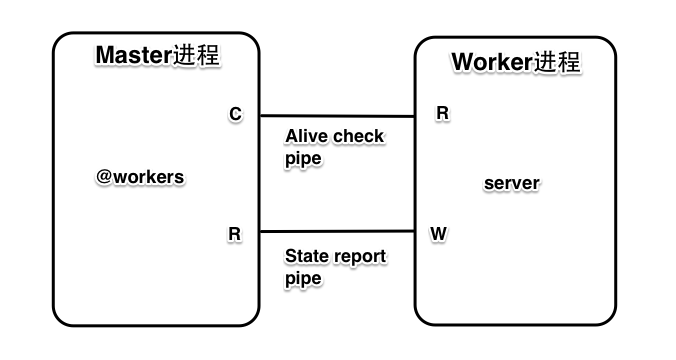
在运行时,Puma 的 Master/worker 进程间有两个 pipe,一个 pipe 用于 worker 进程报告给 master 进程自己的状态,另外一个 pipe 用于 worker 进程检查 master 进程有没有退出。代码中 pipe 相关的变量有 6 个,3 读 3 写,按执行顺序出现的次序如下:
read, @wakeup = Puma::Util.pipe
@check_pipe, @suicide_pipe = Puma::Util.pipe
@master_read, @worker_write = read, @wakeup
这段代码很奇葩,明明只有两个 pipe,只应该有 2 读 2 写,为什么偏偏多定义一组,而且是简单变量复制的方式多定义一组?仔细分析代码发现,read 和@wakeup这一组 pipe,只有 master 进程向@wakeup写内容,而且只有一处写。
def wakeup!
begin
@wakeup.write "!" unless @wakeup.closed?
rescue SystemCallError, IOError
end
end
而@master_read和@worker_write这一组 pipe,@master_read其实没有被使用,worker 进程有两处向@worker_write写内容。一处是 worker 进程内的 server 启动后,通过写"b#{Process.pid}\n"通知 master 进程;一处是 worker 进程内的独立线程,每 5 秒钟写一次"p#{Process.pid}\n",报告 master 进程自己的状态。
def worker(index, master)
server = start_server
@worker_write << "b#{Process.pid}\n"
Thread.new(@worker_write) do |io|
payload = "p#{Process.pid}\n"
while true
sleep 5
io << payload
end
end
所以图中的 state report pipe 其实有两个独立的用途,一个用途是主进程自己使用,用于 wakeup,另一个用途是子进程报告状态。因为有两种独立的用途,所以定义了两组体现用途的名字。
在 Master 进程中,有一个@workers对象,保存的是 Worker 的数组,这个 Worker 对象其实不是真的 worker,而只是子进程 worker 信息的记录对象。因为在不同的进程中,ruby 对象是完全对立的,主进程中的@workers对象和子进程中的任何 ruby 对象都没有关系。
class Worker
def initialize(idx, pid, phase, options)
@index = idx
@pid = pid
@phase = phase
@stage = :started
@signal = "TERM"
@options = options
@first_term_sent = nil
@last_checkin = Time.now
end
attr_reader :index, :pid, :phase, :signal, :last_checkin
Worker 对象的几个关键属性为:index 指子进程编号,从 0 开始;pid 指子进程的 pid,phase 指第几次 phased_restart,signal 指要发送给子进程的信号,last_checkin 指子进程最后一次报告状态的时间。
Master 主进程并不实际处理 Web 请求,而是由 worker 进程来处理。worker 进程启动的时候,会在内部启动一个 puma 的 server。
Puma 集群的启动过程
集群的启动执行的是 Cluster 类的 run 方法。其中绑定端口,写状态文件之类的函数和单进程模式是一样的,这里就不重复说明了。可以看到,集群模式多了很多信号处理的代码,pipe 处理的代码,以及最关键的启动 worker 进程的代码 spawn_workers。
class Cluster < Runner
def run
@status = :run
output_header "cluster"
log "* Process workers: #{@options[:workers]}"
@cli.binder.parse @options[:binds], self
read, @wakeup = Puma::Util.pipe
Signal.trap "SIGCHLD" do
wakeup!
end
Signal.trap "TTIN" do
@options[:workers] += 1
wakeup!
end
Signal.trap "TTOU" do
@options[:workers] -= 1 if @options[:workers] >= 2
@workers.last.term
wakeup!
end
master_pid = Process.pid
Signal.trap "SIGTERM" do
if Process.pid != master_pid
log "Early termination of worker"
exit! 0
else
stop
end
end
@check_pipe, @suicide_pipe = Puma::Util.pipe
redirect_io
start_control
@cli.write_state
@master_read, @worker_write = read, @wakeup
spawn_workers
Signal.trap "SIGINT" do
stop
end
@cli.events.fire_on_booted!
begin
while @status == :run
... #主进程的主循环,见下一小节
end
end
end
主进程一共处理 5 种类型的信号:SIGCHLD 让主进程 wakeup,TTIN 增加一个 worker 进程,TTOU 减少一个 worker 进程,SIGTERM 终止主进程,SIGINT 也是终止进程。
Master 进程的主循环
集群的主进程启动完成后,执行下面的主循环。循环中读取 read 对象,这个 read 就是前面提到的状态检查 pipe 的读取对象。该 pipe 一共可能写入三种数据,"!","b#{pid}","p#{pid}",所以读取的时候判断是哪种情况并相应进行处理。
begin
while @status == :run
begin
res = IO.select([read], nil, nil, 5)
force_check = false
if res
req = read.read_nonblock(1)
next if !req || req == "!"
pid = read.gets.to_i
if w = @workers.find { |x| x.pid == pid }
case req
when "b"
w.boot!
log "- Worker #{w.index} (pid: #{pid}) booted, phase: #{w.phase}"
force_check = true
when "p"
w.ping!
end
else
log "! Out-of-sync worker list, no #{pid} worker"
end
end
if @phased_restart
start_phased_restart
@phased_restart = false
end
check_workers force_check
rescue Interrupt
@status = :stop
end
end
stop_workers unless @status == :halt
ensure
@check_pipe.close
@suicide_pipe.close
read.close
@wakeup.close
end
end
当主进程收到"b#{pid}"和"p#{pid}"格式的数据时,根据 pid 找到 Worker 对象,然后执行该对象的 boot! 和 ping! 方法,主要就是更新 Worker 的最后签到信息。
class Worker
def boot!
@last_checkin = Time.now
@stage = :booted
end
def ping!
@last_checkin = Time.now
end
Puma 集群的 Worker 的启动过程
上面提到,Master 进程会调用 spawn_workers 方法启动 worker 进程,这里就是相关代码:
def spawn_workers
diff = @options[:workers] - @workers.size
master = Process.pid
diff.times do
idx = next_worker_index
pid = fork { worker(idx, master) }
@cli.debug "Spawned worker: #{pid}"
@workers << Worker.new(idx, pid, @phase, @options)
@options[:after_worker_boot].each { |h| h.call }
end
if diff > 0
@phased_state = :idle
end
end
其中的核心部分就是 fork 调用创建一个新的 worker 进程,该进程会立即执行 worker(idx, master) 方法。有 java 语言背景的人,容易误认为这里的 worker 方法是 Worker 类的构造函数,其实它们之间没有关系。
def worker(index, master)
title = "puma: cluster worker #{index}: #{master}"
title << " [#{@options[:tag]}]" if @options[:tag]
$0 = title
Signal.trap "SIGINT", "IGNORE"
@workers = []
@master_read.close
@suicide_pipe.close
Thread.new do
IO.select [@check_pipe]
log "! Detected parent died, dying"
exit! 1
end
hooks = @options[:before_worker_boot]
hooks.each { |h| h.call(index) }
server = start_server
Signal.trap "SIGTERM" do
server.stop
end
begin
@worker_write << "b#{Process.pid}\n"
rescue SystemCallError, IOError
STDERR.puts "Master seems to have exitted, exitting."
return
end
Thread.new(@worker_write) do |io|
payload = "p#{Process.pid}\n"
while true
sleep 5
io << payload
end
end
server.run.join
hooks = @options[:before_worker_shutdown]
hooks.each { |h| h.call(index) }
ensure
@worker_write.close
end
从代码中可以看出,worker 进程忽略 SIGINT 信号,收到 SIGTERM 信号时会调用 server.stop。但是如果 start_server 还没有调用的时候,worker 进程就收到了 SIGTERM 信号,那么 worker 进程会执行 exit。把主子进程两处定义的 SIGTERM 处理函数放在一起会更清楚一些。
Signal.trap "SIGTERM" do
# The worker installs their own SIGTERM when booted.
# Until then, this is run by the worker and the worker
# should just exit if they get it.
if Process.pid != master_pid
log "Early termination of worker"
exit! 0
else
stop
end
end
Signal.trap "SIGTERM" do
server.stop
end
因为 Linux 的 fork 创建进程时是写时拷贝的,所以当主进程设置的 SIGTERM 的处理代码,而子进程还没有修改时,子进程执行的也是同样的处理代码。而当子进程设置了 SIGTERM 的处理代码,主子进程各自拥有独立的 SIGTERM 的处理代码。
由于子进程不需要@workers对象,所以将@workers置空。子进程中不需要的 pipe 端口也关闭。子进程中有一个单独的线程来判断主进程是否退出。
Thread.new do
IO.select [@check_pipe]
log "! Detected parent died, dying"
exit! 1
end
前面提到@check_pipe和@suicide_pipe是一对读写的 pipe。但是实际上没有任何代码往@suicide_pipe里写数据。所以 IO.select 返回的唯一情况就是@suicide_pipe被关闭了。此时主进程一定挂了。
当 worker 进程执行了 start_server 以后,会通过 pipe 写状态数据“b#{pid}”和"p#{pid}",这部分代码已经分析过了。最后,worker 进程执行 server.run.join 来实际处理 web 请求。