[hi1]content1[hi2]content2[h3]content3
如果想截取 [hi1] [h2] [h3] 之间的文本内容 要怎么写了
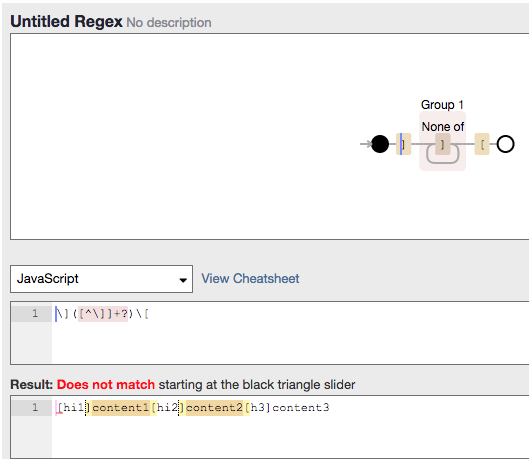
\]([^\]]+?)\[
非贪婪模式即可 str.scan(/](.*?)[/)
@leopku thanks. 顺便请教下,为何这个规则行不通 /\[.\](.)\[.\]/ 我的想法是,前后各一个括号,中间用 (.) 这个思路主要是哪错了
#3 楼 @luffycn 我来说一下你这个正则的大概工作流程。
\[
.*
h
3
hi1]content1[hi2]content2[h3]content3
\]
t
]
(.*)
content3
hi1]content1[hi2
]content2[h3]content3
[
content2
h3]content3
n
e
h3]
h3
整个匹配结束时,第一个 .* 匹配了 hi1]content1[hi2,第二个 .* 匹配了 content2,第三个 .* 匹配了 h3。