序幕
看小说看多了,一直没有钟情一个网站,总是感觉众多不爽的地方,于是乎无聊的人脑袋一热,在国庆前的某一个晚上开始编码。
国庆就扔在服务器上跑,很长时间之后发现有了千万的章节数据,很是欣喜,使用 scaffold 生成了几个页面供自己看小说,自娱自乐。
不过最近想来这破玩意也没啥用,就想分享给各位想做类似的网站或者想抓取网页内容的看客,希望能给各位一点有用的帮助吧。
期望
- 希望能定时抓取不同小说站点的小说,
- 并选择最好的最优质的内容输出给用户
- 同时支持多种输出渠道
实现
已经实现了 ranwen 整站抓取和更新(V1.1.0 版本) 已经实现多源支持(master) 已经实现规则配置抓取内容 (master),如:目前起点网站列表抓取规则:
rules = {
#书籍列表
book: {
list: {
url: 'http://all.qidian.com/book/bookstore.aspx?PageIndex=:page',
path: 'div.twoleft',
item: {
path: 'div.sw2,div.sw1',
segments: {
title: {
path: 'div.swb/span.swbt/a',
type: 'href'
},
last_chapter: {
path: 'div.swb/a.hui2',
type: 'href'
},
word_count: 'div.swc',
author: {
path: 'div.swd/a',
type: 'href',
save_url: false
},
last_updated_at: 'div.swe',
category_id: {
path: 'div.swa',
pattern: 'SubCategoryId=(\d+)',
category: 'regexp'
}
},
},
paging: {
path: 'div.storelistbottom',
current_page: 'a.f_s',
pages: 'a.f_a'
}
},
#书籍明细,如图片,公告,评论等
info: {
},
#书籍章节列表
chapter: {
},
#书籍正文信息
content: {
}
}
}
计划
- 更多小说站点的专区
- 友好的前段体验
- 客户端支持
- 单行本生成
- ...
源头
这里源是指小说提供的站点
小说章节信息
- ranwen
- tieba (@williamherry的建议)
- 等待你的补充
小说基本信息
- 起点
- 纵横
项目
项目地址:https://github.com/yuesmart/mori
鸡蛋啥的随便扔 :) 对了,忘记说了,没有 test case,嘿嘿
演示
演示地址:暂时去掉了
* 我不期望你推广,也不要常年蹲上面,服务器有压力,看完赶紧给我闪人 :)
* 界面土那是一定的,不过是 scaffold 生成,千篇一律的 bootstrap 破玩意
演示中很多小说章节的上下级关系没跑,你可以尝试在右边的输入框中输入 星神 ,然后敲回车,选择 断晨风 的那本
开工
- 如果你要自己折腾,自己 fork
- 如果你要参加到这个项目中,告诉我下你的账号,我加你进来
git clone [email protected]:yuesmart/mori.git
截图
最后为了引诱那些小伙伴们,来点截图吧
- 首页
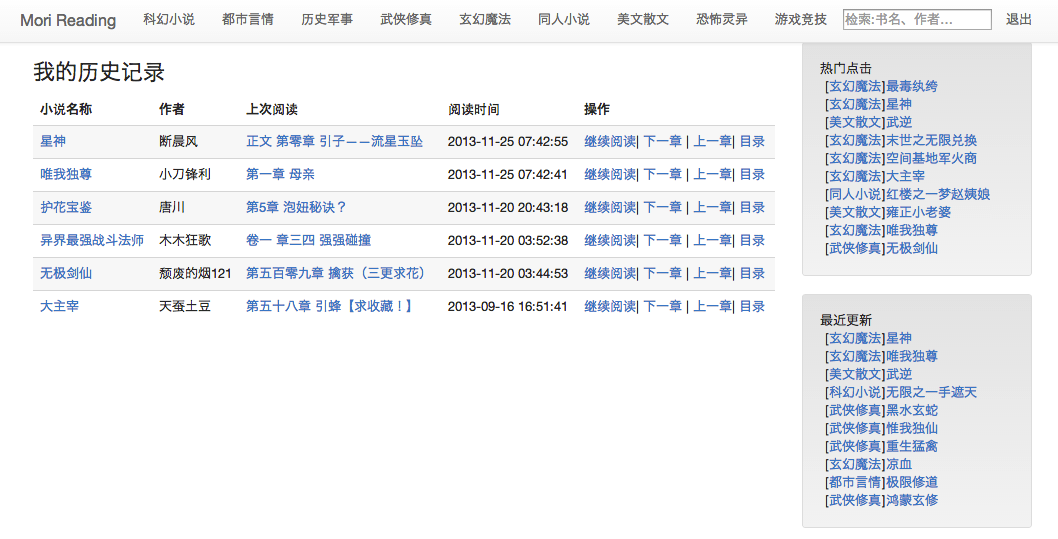
- 章节列表
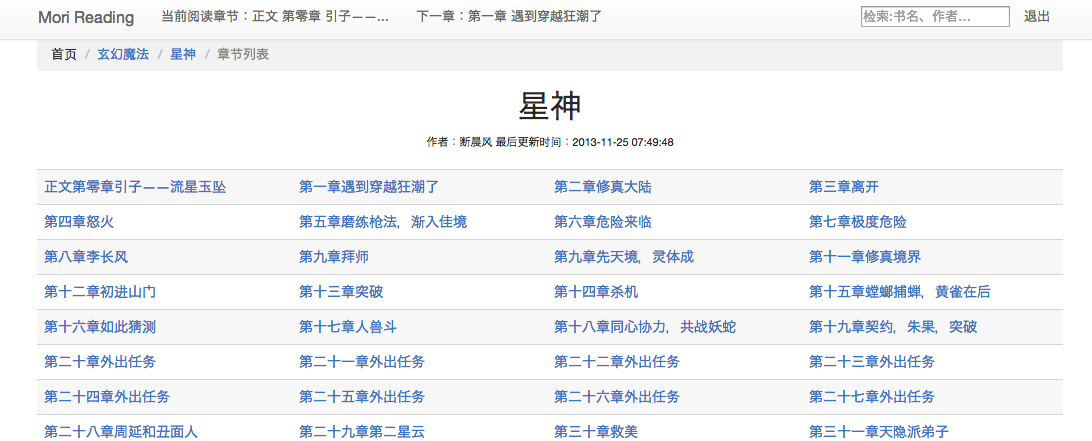
- 正文
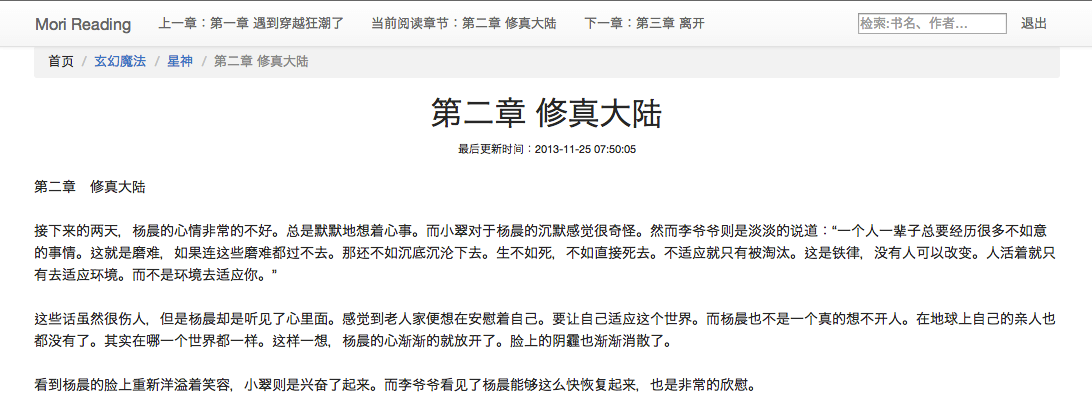
打完收工,写文档比写代码累!

