瞎扯淡 TiDB 为什么能横向扩展?
蛋疼的数据量
之前做过 SASS 系统,业务中有几张核心数据表,数量都超过了 5000W,查询频率很高,界面上聚合的数据字段可以通过自定义扩展非常多。每天都会定时定点来一波故障,大多数都是 MySQL 慢查询,对业务影响很恶劣。
咋个办呢?全部走 ES 搜索可以解决问题,但成本会比较高,而且还要较长的开发周期 (有部分模块接入了 ES)。最快解决问题的办法有几个,当时的先烈们已经把大盘搭好了:
- 加从库,一个不够加两个
- 使劲分表。SASS 应用是多租户的模式,各个公司的数据在逻辑上没有交叉
- 把不参与核心数据 join 的表全部迁走
效果是有的,而且这种模式也支撑了业务好长一段时间。但是随着业务数据进一步扩大,不同公司的数据量差异很大,业务精湛的公司数据量远超其他公司,这使得对应的分表数据行数也迅速搞到大几百万,在复杂的查询下,会有不同组合的索引,当数据量大索引复杂时,MySQL 就会乱选索引,执行计划都偏离了实际的数据。
再加上各个业务表都是数千万的量,由于 B 端变态的业务逻辑,有非常多的 join 联合查询,把这些大家伙分到不同的机器上非常困难。所以但 DB 的总数据量和查询压力非常大,到后来加从库也不顶用了,慢查询迅速就能堵住 DB。眼下就只有一条路,就是增加一个 MySQL 的中间件代理层。而业界的那些垃圾代理完全不靠谱,要么复杂要么完全满足不了 B 端的业务需要,而小公司根本养不起做代理层的人才。眼看数据库的机器已经是顶配了,程序员哥哥们都很焦虑啊。
后面的做法就是把那几个大家伙的数据单独搞出来,放到另一个 DB,用单独的业务实例给他们服务,在进入层通过域名直接分流,他们挂了其他客户不受影响。就像起初微博给某些大 V 单独搞服务器是一个套路。
创业公司对成本太敏感,还是很难为技术哥哥们的,后面技术哥哥们提出限制单公司数据量的意见终于被产品爸爸们采纳了,“大 V”的增长势头由此被遏制住了。一个公司导入几百上千万数据根本没有意义,排序靠后的“百年难露面”,有时候问题的根源在于产品经理天马行空的想当然。
再后来由于种种原因我跑路了。
遇见 TiDB
后面断断续续听到 TiDB 的声音越来越多,而且现公司也有业务在开始使用。在零零碎碎的知识中,我知道 TiDB 最大的优势是可以避免业务自己分表,通过简单扩容就可以解决上面的问题,这是一件超级棒的事情。
目前所在 C 端的业务,有些场景数据量也比较大,但由于 C 端超极度简单的查询场景,数据直接分表、归档就行。而这个分表也是很恶心,有些同时按天、uid 尾号、月份分表,非常麻烦,代码看着也复杂。结合我之前 B 端的经验,我觉得 TiDB 是非常有价值的,也产生了浓厚的兴趣,想一窥原理。
为什么能横向扩展
MySQL 的表数据、索引数据、表结构是分别放在一个文件中的,当数据量膨胀,表文件就会变大,这会让查询耗时急剧上升,而表文件只能在一台机器上加载。唯一的解决方案就是分表,当数据量进一步扩张时,还需要分库。这时候应用程序读库就需要通过复杂的代理层 (Vitess/Altas),不过要么太复杂,要么难以满足 B 端的需求,所以很多 B 端业务是将数据整合成宽表,写到利好搜索的存储中。
这种以表为单位集中存放数据的模式,在数据量增长的过程中成为扩展的瓶颈,这是根源问题。而业界屏蔽分库分表的复杂性的方案又不够争气。要解决这个问题,根源上是要打破以表为单位存放数据的这种模式,互联网架构的经验告诉我们,当遇到问题、遇到瓶颈时,要做的事就是一个字:拆。
先将数据拆碎
不管是微服务还是存储,都是这个思路,这是“体”级别的智慧。 拆的本质其实是将元素的组成单位变小,通过增加系统复杂度,来提高扩展能力。TiDB 也是这样做的,它瞄上了 KV 存储,让数据的最小单位以“行”存在,每行数据有一个 Key 来表达,key 对应的 value 就是行数据的内容。表解构、表数据、表索引都可以用 KV 对来表达。引用官方文档中的内容举例:
KV对如何表达MySQL的行数据:
假设表中有 3 行数据:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
那么首先每行数据都会映射为一个 Key-Value pair,注意这个表有一个 Int 类型的 Primary Key,
所以 RowID 的值即为这个 Primary Key 的值。假设这个表的 Table ID 为 10,其 Row 的数据为:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
除了 Primary Key 之外,这个表还有一个 Index,假设这个 Index 的 ID 为 1,则其数据为:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
- 每张表有一个全局唯一的 ID(Table ID)
- 每个索引有一个表级别唯一的 ID(Index 的 ID)
- 每条数据有一个表级别唯一的主键 ID(Primary Key)
这样每张表的每条数据可以用一个全局唯一的 Key 来表达。Key 的组成有特定的规律:
t{TableId}_r{Primary Key} # 如上面的 t10_r1
这种表达方式会让同一张表的行数据,Key 的头部都是一样的。而 TiDB 会将这些表数据存放在 TiKV 中 (处理 KV 存储的模块),然后会使用超级大招: KV 的存储是按 Key 全局有序排列。
这样的结果是:
- 同一张表的数据是聚集在一个区间的
- 这个区间中数据的顺序是按 Primary Key 来排列的
- 扫描表数据会变得方便
- 预测表数据在 KV 的什么位置很方便
存在 DB 中的数据是一个超大的有序列表,当需要扩容时将这个有序列表按区间,有序地分给对应的机器就行。当有新机器加入时,按区间分别分给新机器一点数据就行。然后维护一个中心节点,来记录管理数据区间在机器上的分布,按规则去取即可。
再将数据组合起来
将数据拆碎后,要实现类似 MySQL 的功能,还差得远。当一条 SQL 进来,MySQL 直接扫描索引或文件获取数据,而 TiDB 将数据拆散了按区间分布在多台机器上。这就意味这需要先解析 SQL,知道要取什么数据,然后根据数据分布记录,去对应的机器上将数据取出后组合起来返回给 client。有点类似数据库中间件的角色。但由于 TiDB 极细粒度的数据拆分,使得灵活性和适应性远远超过了中间件。
TiDB 的架构也就是如下图:
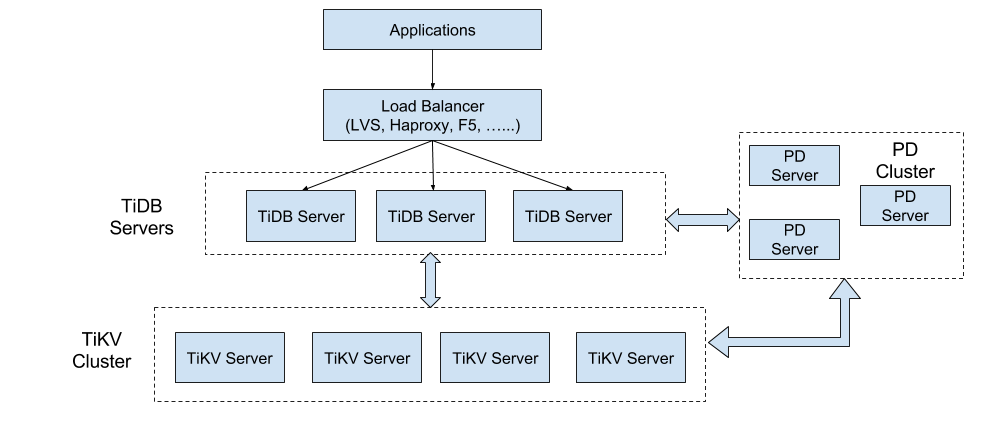
- TiKV 按区间均分了数据库中的数据,数据量变大,加 TiKV 机器就行(区间按 Key 全局排序)
- TiDB Server 表达了一个 SQL 层,解析 SQL,根据数据区间的分布,去对应的 TiKV 取数据后同一聚合处理
- TiDB Server 无状态,client 随机连一个就行,负荷变大时,直接加机器就行
- PD 是全局调度,维护区间分布数据、保障数据、负荷等均匀
可以看出,这是以极高的架构复杂度、运维复杂度来换取灵活可扩展能力。也相当于将以前各种数据库中间件的复杂度统一整合、收拢起来,对外屏蔽复杂度,只暴露简单的操作接口。这也代表了技术沉淀和迭代的统一方向,web 领域的组件化、框架化、工具化,在发展趋势上本质也是一样的。
由于水平有限,以上只简单介绍了 TiDB 零星的原理,关于横向扩展的基本原理。未能涉及 TiDB 庞大而复杂的系统,如在此架构中如何做到 ACID、高可用等等,更多的信息请阅读 PingCap 超高质量的官方技术文档: