在数据结构之 HashMap中简要介绍了 HashMap 的作用、原理、冲突解决、一致性 hash 和并发等问题,以PPT的视角大致整合了 HashMap 的知识结构,蜻蜓点水。
本文尝试在上面文章的基础上,进一步关注偏底层一点的知识: HashMap 如何在内存中组织键值对?
接下来通过简单梳理 Redis、Ruby(动态语言)、Golang(静态语言) 中 HashMap 的部分实现,来解答上面的问题,如有不对的地方,还请不吝赐教。
初识问题
在刚学习 Golang 的时候,会遇到静态语言蛋疼的类型声明:
var hash map[string] int
会发现 HashMap 的 key 和 value 都各自有类型,map 的底层抽象需要能适应多类型的场景,在常规意识中,key 和 value 是捆在一起的,而类型声明让这件事情看起来更复杂了。
从 Redis 的角度来看这稍微简单,Redis 的十多个逻辑 database 实际上每个都是 HashMap,不过它的 key 都是sds,而 value 通过 RedisObject 统一抽象,内部通过 type 来区分是哪种数据结构,类型表面看起来是固定的。
从 Ruby 的角度来看就更简单了,动态语言的类型会在运行的时候进行解析,使用者根本不用关心。简单的 HashMap 抽象可以是下面:
class Hash
attr_accessor :entries # 数组,用来存放键值对
attr_accessor :size, :mask
end
class Entry # 键值对的核心抽象
attr_accessor :key, :value, :next
end
hashMap 的核心结构中始终分为两部分:
- 一个数组 (table)
- Entry 用来打包 key-value 等数据
有一个数组,其中存放着 Entry,HashMap 近似 O(1) 的时间复杂度就是得益于数组的随机访问特性。而根据解冲突的方案等的不同,Entry 的结构有差异有不同的实现。一般用链表解冲突的方案中,其 Entry 中都会有一个 next 指针,而开放寻址的就没有这个指针。
当然实际情况不会这么简单,接下来就看看更为复杂的真正实现。
Ruby 的实现
Ruby 的 hash 实现在 2.4 的时候有一次大改,核心点是引入了开放寻址的解冲突方案,让性能大幅提升。貌似为了向后兼容,两种实现现在都还在源码中,通过 C 中的 union 来整合:
//https://github.com/ruby/ruby/blob/v2_6_0/internal.h#L835
struct RHash {
struct RBasic basic;
union {
st_table *st; //新方案
struct ar_table_struct *ar; /* 旧方案 */
} as;
const int iter_lev;
const VALUE ifnone;
};
新方案在 st.c 中,来看看新方案的细节。
// https://github.com/ruby/ruby/blob/v2_6_0/include/ruby/st.h#L79
struct st_table {
/* Cached features of the table -- see st.c for more details. 缓存一些数字,例如大小*/
unsigned char entry_power, bin_power, size_ind;
/* How many times the table was rebuilt. */
unsigned int rebuilds_num;
const struct st_hash_type *type; /* hash函数等方法定义*/
/* Number of entries currently in the table. */
st_index_t num_entries;
/* Array of bins used for access by keys. */
st_index_t *bins; /* 核心实现之一 , 通过这个数组用来实现开放寻址*/
/* Start and bound index of entries in array entries.
entries_starts and entries_bound are in interval
[0,allocated_entries]. */
st_index_t entries_start, entries_bound;
/* Array of size 2^entry_power. */
st_table_entry *entries; /*核心实现之二 存放实际的键值对,将数组下表存放在bins中*/
};
上面的是 hashMap 的 table 核心结构,需重点关注的有两个地方:
- *bins 数组,通过 key 的 hash 值来实现开放寻址,数组中存放的是下面 entries 的下标
- *entries 数组,实际存放键值对的地方,按照插入的先后顺序存放
bins:
-------
|5 | entries array:
|-------| --------------------------------
|1 | | | entry: | | |
|-------| | | | | |
| ... | | ... | hash | ... | ... |
|-------| | | key | | |
| empty | | | record | | |
|-------| --------------------------------
| ... | ^ ^
|-------| |_ entries start |_ entries bound
|deleted|
-------
如果要存放一个 key-value,有两步:
- 将 key-value 追加到 entries 中,记录其所在的下标
- 获取 key 的 hash 值,通过开放寻址探测到 key 应该存放的位置,将第一步中的下标存放到 bins 中
在通过 key 查询的时候,是先到 bins 中找到 key-value 在 entries 中的下标,然后通过下标再去 entries 中找到实际的 key-value。
接下来关注本文的重点,key-value 是如何抽象的:
struct st_table_entry {
st_hash_t hash; // key的hash值
st_data_t key; // key的指针,st_data_t 定义在下面
st_data_t record; // value的指针
};
#if SIZEOF_LONG == SIZEOF_VOIDP
typedef unsigned long st_data_t; // 重点
#elif SIZEOF_LONG_LONG == SIZEOF_VOIDP
typedef unsigned LONG_LONG st_data_t;
#else
# error ---->> st.c requires sizeof(void*) == sizeof(long) or sizeof(LONG_LONG) to be compiled. <<----
#endif
可以看出 st_data_t 其实是 long,大小就等价于一个 void 指针,也就是说Ruby 在组织 key-value 时是简单地在 entries 中存放其各自的指针,将其打包到一个结构体中,而 entries 里面存放的则是结构体的指针。
Ruby 在实现 hashMap 是根本就没有考虑对象的类型问题,之所以可以这样,是因为 Ruby GC 几乎将所有对象进行了统一抽象,通过RVALUE 结构体来实现:
typedef struct RVALUE {
union {
struct {
unsigned long flags; /* 0 if not used */
struct RVALUE *next;
} free;
struct RBasic basic;
struct RObject object;
struct RClass klass;
struct RFloat flonum;
struct RString string;
struct RArray array;
//·····
} as;
} RVALUE;
Redis 的实现
redis 的 hashMap 在代码中被成为 dict,通过链表方案解决冲突问题,所以 dictEntry 的核心实现中会有 next 指针。
// https://github.com/antirez/redis/blob/4.0.0/src/dict.h#L47
typedef struct dictEntry { //Entry实现
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //next指针
} dictEntry;
/* Table的核心实现 */
typedef struct dictht {
dictEntry **table; // Entry数组
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type; // hashMap的各种方法,hash函数等
void *privdata;
dictht ht[2]; // 有两个table,一新一旧,用来实现增量迁移
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
由上面的代码可以看出,key 是通过指针直接存放,指向的其实是 sds,全名叫简单动态字符串,其实现也是通过一个字符数组实现,可以弹性扩容,其类型是可以认为就是字符串。
而 value 会根据对象来区别对待,如果是数字的话直接存储,是对象的话则存放指针。指针对应的是一个 redisObject,通过 type 可以知道具体是哪种对象:
#define OBJ_STRING 0
#define OBJ_LIST 1
#define OBJ_SET 2
#define OBJ_ZSET 3
#define OBJ_HASH 4
// https://github.com/antirez/redis/blob/4.0.0/src/server.h#L584
typedef struct redisObject {
unsigned type:4; // type有上面的5种
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits decreas time). */
int refcount;
void *ptr; // 指向实际的对象
} robj;
Golang 的实现
go 的实现相对复杂:
// https://github.com/golang/go/blob/release-branch.go1.10/src/runtime/hashmap.go#L108
// A header for a Go map.
type hmap struct {
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // table的实现, 指向一个 2^B 个Buckets的数组
//它也有两个table,和redis一样用来实现增量迁移,将扩容时的消耗分散在多个操作中,避免单次操作延迟过高。
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // 溢出链,会存放冲突的键值对
}
golang 的实现让人困惑,它没有用一个特定的 struct 来抽象 table 的结构,只是在 hmap 中保留 table 的指针,table 是一块连续的内存块,大小为 2^B 个 Bucket,一个 Bucket 的实际大小根据 key 和 value 的类型不同而不同。
在上面 Redis 和 Ruby 的方案中,每个 Entry 都只存放一个 key-value 对,而 Golang 的一个 Bucket 会存放 8 组 key-value,Bucket 中的 key-value 会打包压在一起。当 Bucket 中空间不够时,会另外申请额外的一个 Bucket,Bucket 间通过指针连接,额外申请的 Bucket 也被称作溢出 Bucket。
下面是 Bucket 的核心结构:
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8 // 第一部分,有8个元素的数组
// 第二部分是key-value对,空间可存放8对
// 第三部分是Bucket指针,指向下一个Bucket,如果有的话
}
struct 中只有第一部分的 tophash,第二部分和第三部分都是通过指针操作来进行的。在为 Bucket 分配空间时,会根据 map 的类型计算出三部分空间的总和一起分配成一块连续的内存空间。
第一部分是一个大小为 8 的数组,用来存放 8 个 key-value 对中 key 的 hash 值的高位,数组下标会对齐。由于每个 Bucket 中有 8 对 key-value,意味着当定位到某个 Bucket 后还需要遍历 Bucket 中的 key-value 才能找到对应的数据,这个遍历操作相对昂贵,而 tophash 的核心作用就是加速这个遍历过程,遍历 Bucket 时直接遍历 tophash,依次对比 hash 值的高位,找到相等的后再根据下标去定位 key-value,避免直接对比 key(数字间对比的性能字符串等好很多)。
第二部分是本文关注的核心点,key 和 value 的类型可能会有多种,在申明 map 时确定。与上面方案不同的是 golang*将 key 和 value 分开存放*,在 Bucket 内部是将 8 对 key 依次放在一起,8 个 value 依次放在一起,类似列式储存。具体原因是,Bucket 中 key 和 value 是以数组的形态存放的,为了能随机查找,必须要字节对齐,而 key 和 value 的类型有可能是不一样的,在字节对齐的时候就会造成内部碎片。而 key 之间或 value 之间类型是一样的,对齐不会造成碎片,这样做是用复杂性换效率。
内存布局大致为下图:
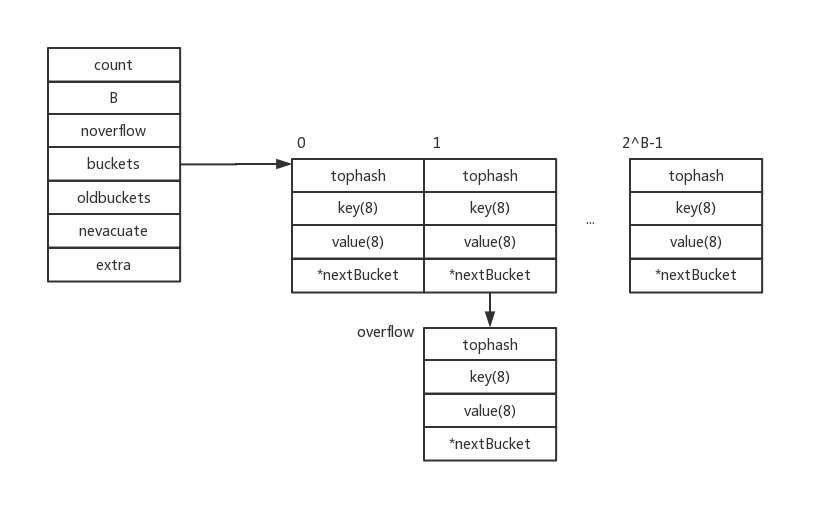
第一层 bucket 数组是在初始化时分配,overflow 层在空间不够时单独分配。值得注意的是,在存放 key 或 value 时如果其内存占用小于 128 字节,则数据是直接存放在 Bucket 中,否则只会在 Bucket 中保留指针。