Rails Redis 实现自动输入完成
原文链接: http://www.rails365.net/articles/2015-11-09-redis-shi-xian-zi-dong-shu-ru-wan-cheng-ba
1. 介绍
当我们在京东商城的搜索框,输入想要搜索的内容,比如你想要搜索"热水瓶",刚输入一个"热"字,就会出现一个下拉框,列出了很多以"热"字开头的可供选择的条目,比如"热水器"、"热水袋"、”热水瓶"等,如下图所示:
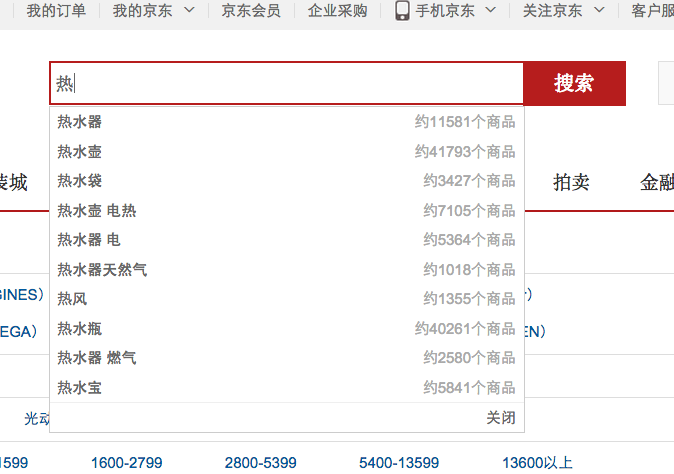
这种技术就叫做自动输入完成,当输入想要搜索的首字符或其中被包含的字符时,就会出现可供选择的条目,用户可以选择其中的条目来完成此次搜索,避免了用户输入全部的字符,改善了用户体验。这种技术很常用,比如在一个社交网站添加联系人时,就是可以通过输入来联想匹配到联系人的。
2. 功能分析
要实现这样的功能,需要前端和后端一起配合,前端部分需要监听搜入框内容的改变,当内容改变时把内容作为参数传递给服务器,服务器再请求后端的数据库,再把数据返回给客户端,前端只要把结果渲染出来即可。
这个数据库我们选择的是内存数据库 redis,而不用存储在磁盘的关系型数据库,毕竟这个功能对实时性要求比较高,频繁地请求数据库肯定是用性能高和速度快的 redis 好。
我们有一个实例网站,是存放文章的,每篇文章都有自己的标签 (tag),整个网站是具有全文检索功能的,也就是说,可以根据文章的标题、内容、标签来搜索文章。现在需要在输入框加一个自动完成的功能,当用户在输入框输入标签的头一个或几个字符的时候,会自动联想到标签。比如,有"ruby","postgresql"两个标签,当用户输入"ru"的时候,会自动出现"ruby"作为可选的项。
首先,被检索的标签的名称事先存放到 redis 中,每个标签都是唯一的,所以可选择 redis 的集合作为数据库,但是,有可以出现很多个以"ru"开头的标签,所以需要一个权重算法,那就是排序,标签被使用得频繁的越排在前面,所以最终是用排序集合 (sortedset) 来存储标签数据。
# rails console
> ActsAsTaggableOn::Tag.all
[
[ 0] 消息队列 {
:id => 50,
:name => "消息队列",
:taggings_count => 5
},
[ 1] ruby on rails {
:id => 8,
:name => "ruby on rails",
:taggings_count => 17
},
[ 2] websocket {
:id => 55,
:name => "websocket",
:taggings_count => 1
},
[ 3] database {
:id => 25,
:name => "database",
:taggings_count => 1
}
]
taggings_count就是标签被使用的次数,只要把tag的name按照taggings_count作为排序标准存到 redis 的sort set中,就可以了。下面我们会说如何去存储这些数据。
3. soulmate 使用
soulmate是一个结合 redis 实现自动输入完成的功能强大的 gem。
先安装这个 gem。
$ gem install soulmate
soulmate 要求你的数据存成一种特定格式的 json,再把 json 导出到 redis 中,格式是类似这样的。
{
"id": 5,
"term": "devise",
"score": 3,
"data": {
}
}
id是唯一的标识,term就是搜索的条目,score就是排序的项,这三项是必须要带上的,而data是可选的,里面可以存自己想要的数据,比如可把 tag 的描述信息加上。
很简单,在我们的案例中,把上面的 tag 的name换成term,taggings_count换成score即可。
3.1 导入 tags 数据
我写了一个方法可以将所有的 tag 导出到一个 json 文件。
File.open("tags.json","w+") do |f|
ActsAsTaggableOn::Tag.find_each do |tag|
tag_json = {
id: tag.id,
term: tag.name,
score: tag.taggings_count
}
f.write("#{tag_json.to_json}\n")
end
end
输出的 tags.json 类似下面这样:
{"id":5,"term":"devise","score":3}
{"id":6,"term":"登录","score":3}
{"id":7,"term":"认证","score":3}
{"id":8,"term":"ruby on rails","score":17}
{"id":9,"term":"rails","score":4}
{"id":10,"term":"ruby","score":4}
现在可以先这个 tags.json 导入到 redis 数据库中,soulmate 这个 gem 也提供了相关的命令行工具。
$ soulmate load tag --redis=redis://localhost:6379/0 < tags.json
你会发现 redis 中增加了很多的数据,我们先不管,等下再来分析那些数据。
3.2 添加单个 tag 到 redis
每次都用这种导入的方式来在 redis 增加数据很不方便的,毕竟以后我们随时要增加 tag。你总不可能为了增加一个 tag 再导一次 json 吧,这不太科学。所以我们需要在增加或删除 tag 的时候自动把数据添加到 redis 中。
通过查看 soulmate 的源码,发现它是提供了相应的方法的。
# https://github.com/seatgeek/soulmate/blob/master/lib/soulmate/loader.rb#L29
def add(item, opts = {})
opts = { :skip_duplicate_check => false }.merge(opts)
raise ArgumentError, "Items must specify both an id and a term" unless item["id"] && item["term"]
# kill any old items with this id
remove("id" => item["id"]) unless opts[:skip_duplicate_check]
Soulmate.redis.pipelined do
# store the raw data in a separate key to reduce memory usage
Soulmate.redis.hset(database, item["id"], MultiJson.encode(item))
phrase = ([item["term"]] + (item["aliases"] || [])).join(' ')
prefixes_for_phrase(phrase).each do |p|
Soulmate.redis.sadd(base, p) # remember this prefix in a master set
Soulmate.redis.zadd("#{base}:#{p}", item["score"], item["id"]) # store the id of this term in the index
end
end
end
由于add方法要接一个 hash 作为参数,所以需要对 tag 这个 model 作一些加工。
# config/initializers/tag.rb
module ActsAsTaggableOn
class Tag < ::ActiveRecord::Base
after_create :create_soulmate
def to_hash
tag_json = {
id: self.id,
term: self.name,
score: self.taggings_count
}
JSON.parse(tag_json.to_json )
end
private
def create_soulmate
Soulmate::Loader.new("tag").add self.to_hash
end
end
end
我们拿其中一个 tag 试一下,看看它究竟生成了怎样的 redis 数据 (如果在开发环境,做这个之前可以用 redis 的 flushdb 指令先清除数据)。
$ rails console
> tag = ActsAsTaggableOn::Tag.first.to_hash
{
"id" => 5,
"term" => "devise",
"score" => 3
}
> Soulmate::Loader.new("tag").add tag
在 redis 生成了如下的数据:
$ redis-cli
> keys *
1) "soulmate-index:tag:devise"
2) "soulmate-index:tag"
3) "soulmate-index:tag:devis"
4) "soulmate-index:tag:dev"
5) "soulmate-index:tag:de"
6) "soulmate-index:tag:devi"
7) "soulmate-data:tag"
所有的 key 分为三大类,分别是"soulmate-index:tag"、"soulmate-data:tag",剩下的以 tag 的 name 为 devise 的前缀开头的 key。结合 add 方法的源码,也可以知道这三种 key 的类型分别为 set, hash, sortedset,可以自己用 redis 的 type 命令打印出来。现在打印出这些 key 的值。
$ redis-cli
> smembers soulmate-index:tag
1) "devis"
2) "devi"
3) "dev"
4) "de"
5) "devise"
> hgetall soulmate-data:tag
1) "5"
2) "{\"id\":5,\"term\":\"devise\",\"score\":3}"
> zrange "soulmate-index:tag:de" 0 -1 WITHSCORES
1) "5"
2) "3"
> zrange "soulmate-index:tag:dev" 0 -1 WITHSCORES
1) "5"
2) "3"
soulmate-index:tag存的是集合 (set),将"devise"分成一个个前缀,以后按照这些前缀就能搜出"devise"这个 tag。soulmate-data:tag存的是一个哈希 (hash),健为标签 (tag) 的 id,值为 tag 的所有内容,就是那个标签 (ActsAsTaggableOn::Tag) model 中to_hash方法的内容,如果有存 data,它的数据也是会在这里出现。soulmate-index:tag:de等存的是排序后的集合,排序的健是score,也就是标签 (tag) 的taggings_count,值为标签 (tag) 的id。
3.3 测试效果
现在来实现服务端的逻辑,我们不用自己写 controller 端的代码,soulmate 为我们提供好了这一切。
先安装这个 gem。
gem install rack-contrib
然后执行以下这个命令。
$ soulmate-web --foreground --no-launch --redis=redis://localhost:6379/0
这会开启一个服务并且监听在 5678 端口。
现在我们可以用 curl 工具或 chrome 浏览器插件 postman 来测试这个服务。下面是 curl 工具的使用例子。
$ curl -X GET http://localhost:5678/search --data "types[]=tag&term=de"
{"term":"de","results":{"tag":[{"id":5,"term":"devise","score":3}]}}
$ curl -X GET http://localhost:5678/search --data "types[]=tag&term=devis"
{"term":"devis","results":{"tag":[{"id":5,"term":"devise","score":3}]}}
使用 postman 请求http://localhost:5678/search?types[]=tag&term=de的例子如下:
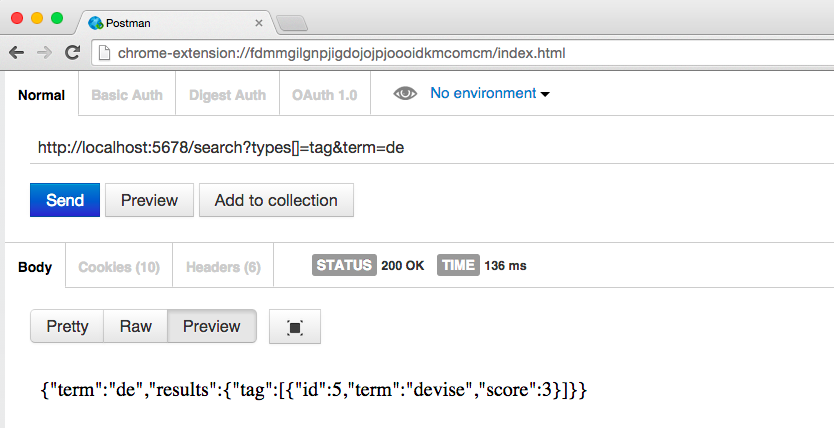
现在再来查看 redis 的数据,会发现多了两个 key。
$ redis-cli
> zrange "soulmate-cache:tag:de" 0 -1 WITHSCORES
1) "5"
2) "3"
> zrange "soulmate-cache:tag:devis" 0 -1 WITHSCORES
1) "5"
2) "3"
4. 页面上的实现
我们要用 soulmate 配合前端在 rails 项目里实现自动输入完成的功能。
先把 soulmate 安装进 rails 项目里。
4.1 挂载 soulmate 服务
把下面的代码添加到 Gemfile 文件,然后执行bundle命令。
gem 'rack-contrib'
gem 'soulmate', :require => 'soulmate/server'
在config/routes.rb文件中添加一行路由。
mount Soulmate::Server, :at => "/sm"
在config/initializers目录下添加 soulmate.rb 文件。
Soulmate.redis = 'redis://127.0.0.1:6379/0'
# or you can asign an existing instance of Redis, Redis::Namespace, etc.
# Soulmate.redis = $redis
重启服务器。现在可以这样来测试。
$ curl -X GET http://localhost:3000/sm/search --data "types[]=tag&term=dev"
{"term":"dev","results":{"tag":[{"id":5,"term":"devise","score":3}]}}
4.2 soulmate.js
至于前端部分,我们使用官方推荐的soulmate.js这个库。
相关的代码是这样的。
= form_tag "/articles", method: "get", class: "navbar-form navbar-left", role: "search"
.form-group
input.form-control id="search" placeholder="Search" type="text" name="term" value="#{params[:search].presence}" autocomplete="off"/
javascript:
// Make the input field autosuggest-y.
$(document).ready(function() {
render = function(term, data, type){ return term; }
select = function(term, data, type){ console.log("Selected " + term); }
$('#search').soulmate({
url: '/sm/search',
types: ['tag'],
renderCallback: render,
selectCallback: select,
minQueryLength: 2,
maxResults: 5
});
});
具体的 css 和 js 效果可以自己处理。
5. 源码解析
现在有个美中不足的地方,就是必须要输入两个字符以上才能开始自动输入完成。而 readme 文档没有相关的解决方法,我们只能从源码入手。
上面的例子中,"devise"这个单词会被分解成一个个前缀,比如"de","dev”等。我们来看下中文词组是如何被分解的。
上面有提到那个add方法的源码,其中调用了prefixes_for_phrase这个方法。
# https://github.com/seatgeek/soulmate/blob/ead5d6c2b6d698a5c49294a73a4f7536a5013f01/lib/soulmate/helpers.rb#L3
module Soulmate
module Helpers
def prefixes_for_phrase(phrase)
words = normalize(phrase).split(' ').reject do |w|
Soulmate.stop_words.include?(w)
end
words.map do |w|
(Soulmate.min_complete-1..(w.length-1)).map{ |l| w[0..l] }
end.flatten.uniq
end
end
end
执行rails console进入终端来看一下这个方法是如何分解中文词组的。
$ rails console
> include Soulmate::Helpers
Object < BasicObject
> prefixes_for_phrase("前端构建与部署工具")
[
[0] "前端",
[1] "前端构",
[2] "前端构建",
[3] "前端构建与",
[4] "前端构建与部",
[5] "前端构建与部署",
[6] "前端构建与部署工",
[7] "前端构建与部署工具"
]
中文词组还是能够正常处理,可是至少要输入两个字符。通过分析prefixes_for_phrase方法,可以发现关键在于Soulmate.min_complete这个变量。
通过搜索源码,发现了定义Soulmate.min_complete变量的地方。
# https://github.com/seatgeek/soulmate/blob/ead5d6c2b6d698a5c49294a73a4f7536a5013f01/lib/soulmate/config.rb#L11
require 'uri'
require 'redis'
module Soulmate
module Config
attr_writer :min_complete
def min_complete
@min_complete ||= DEFAULT_MIN_COMPLETE
end
def redis=(server)
...
end
end
end
还记得上文"挂载 soulmate 服务"部分提到config/initializers/soulmate.rb这个文件吗,里面就是定义了Soulmate.redis这个变量,那同样的道理,也把min_complete定义在里面。
# config/initializers/soulmate.rb
Soulmate.redis = 'redis://127.0.0.1:6379/0'
Soulmate.min_complete = 1
再来看结果。
$ redis-cli
> include Soulmate::Helpers
Object < BasicObject
> prefixes_for_phrase("前端构建与部署工具")
[
[0] "前",
[1] "前端",
[2] "前端构",
[3] "前端构建",
[4] "前端构建与",
[5] "前端构建与部",
[6] "前端构建与部署",
[7] "前端构建与部署工",
[8] "前端构建与部署工具"
]
完结。

 学习了,很实用的 code
学习了,很实用的 code