开源项目 开源公司内部的微信爬虫,寻求志同道合的人一起来改进
一个爬取微信公众号文章的爬虫
github: https://github.com/bowenpay/wechat-spider
微信爬虫的由来
我们是一家帮助中国 5000 万贫困人口与社会公益组织的对接的公司。
我们通过国家和地方政府的“建档立卡”系统,获取到了一手的贫困户数据,目前有 100 万左右,总数为 5000 万,目前每个月都在增长。
为了帮助这部分贫困户对接公益机构,我写了这个微信爬虫,从微信公众号发布的文章中上找出最新的公益项目。
这种找项目的方式的可行性,我们还在试验中。
起初,为了快速上线,本爬虫的代码是基于我的另一个 通用爬虫项目 开发的,还不是很完善,所以希望任何对本项目感兴趣的人联系我,与我一同改进这个项目。
联系方式:在该 issue 下留言告诉我 点击去留言
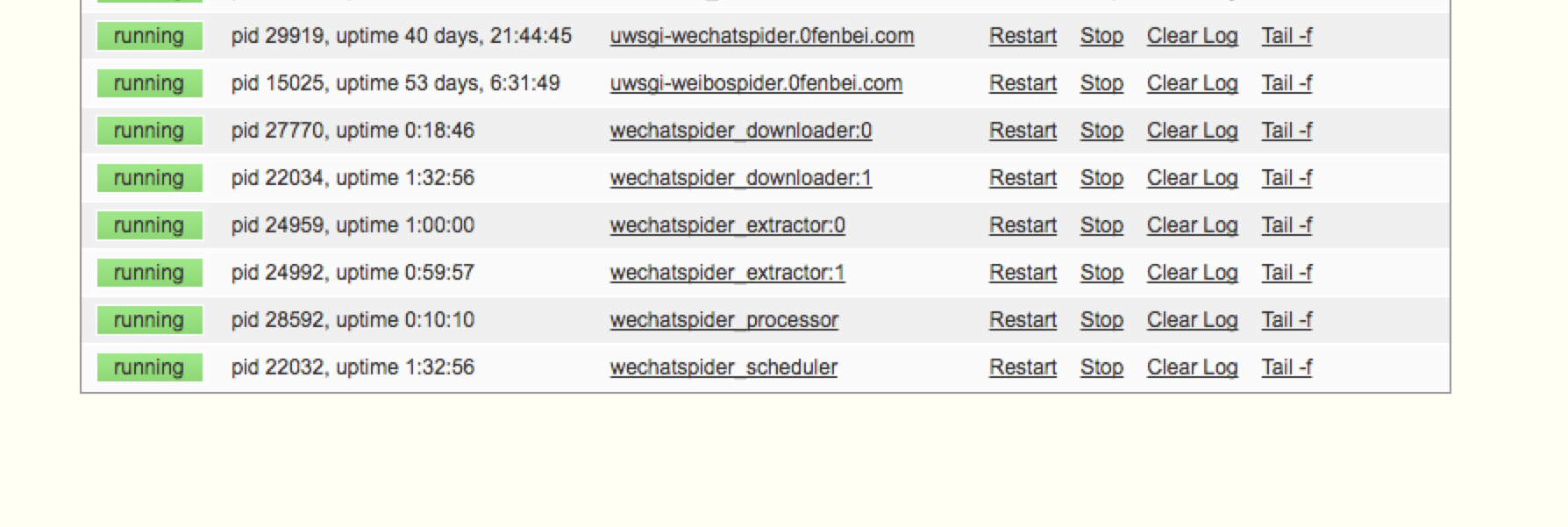
界面预览
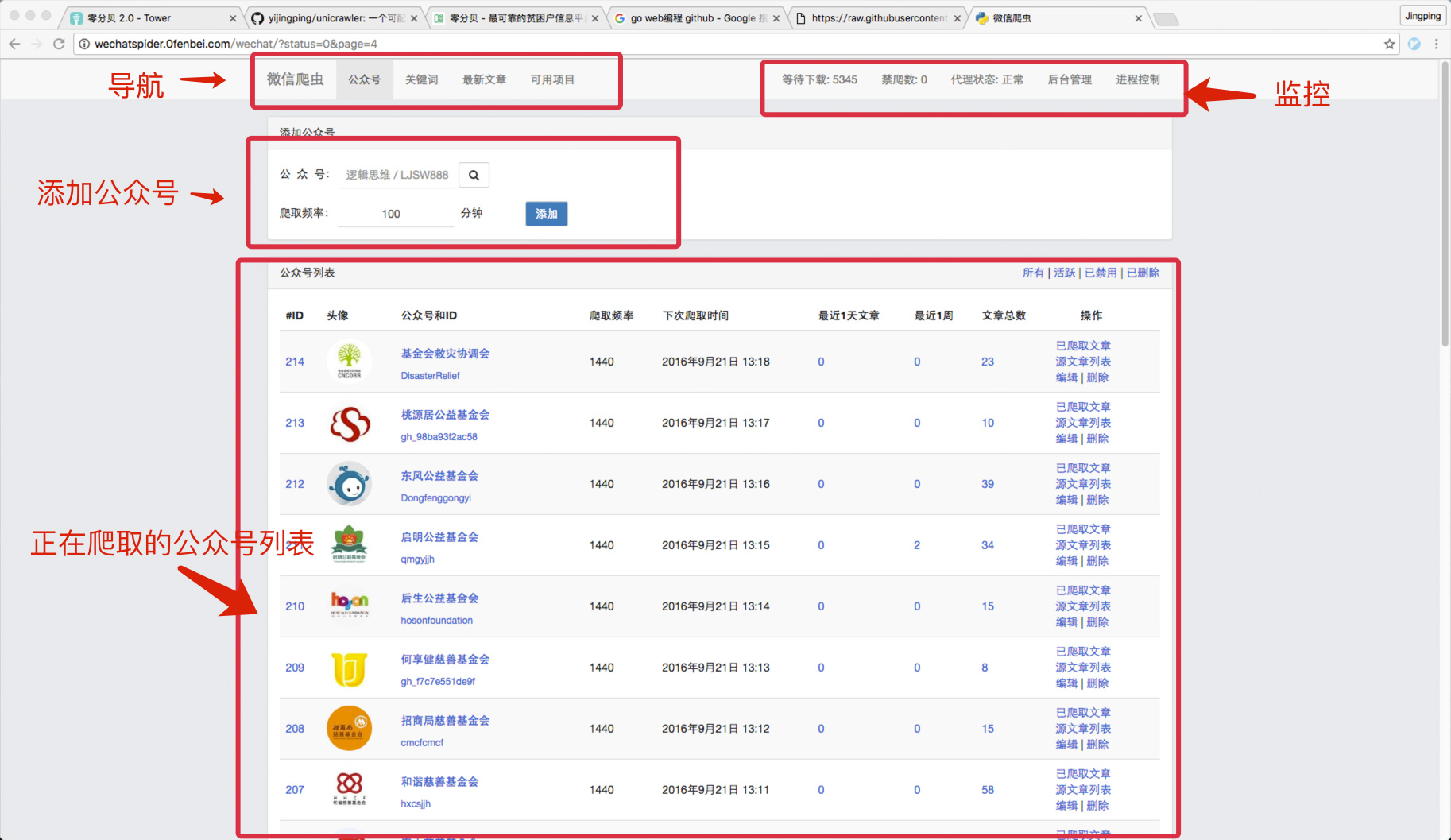
1)要爬取的微信公众号列表
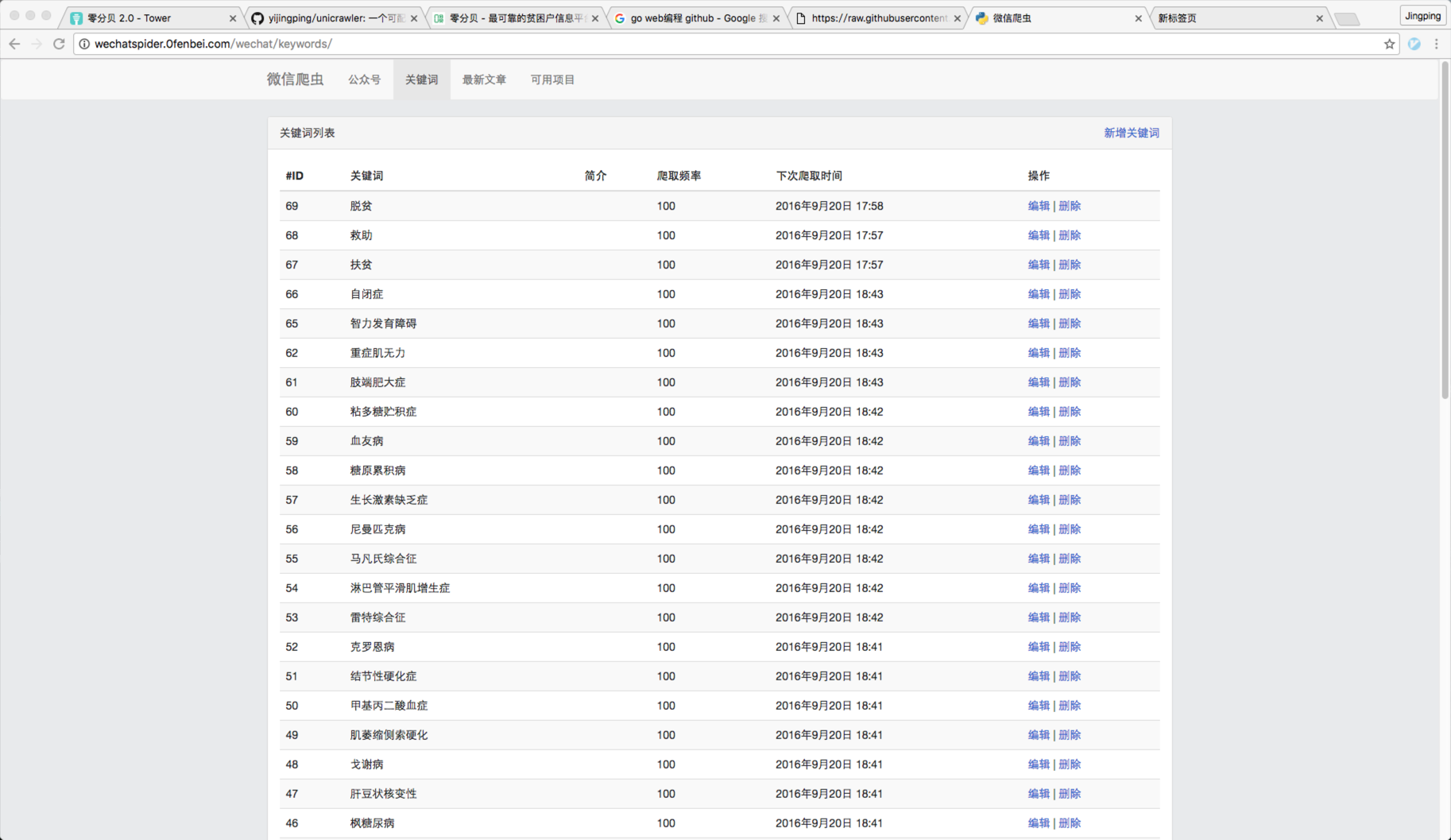
2)要爬取的文章关键字列表
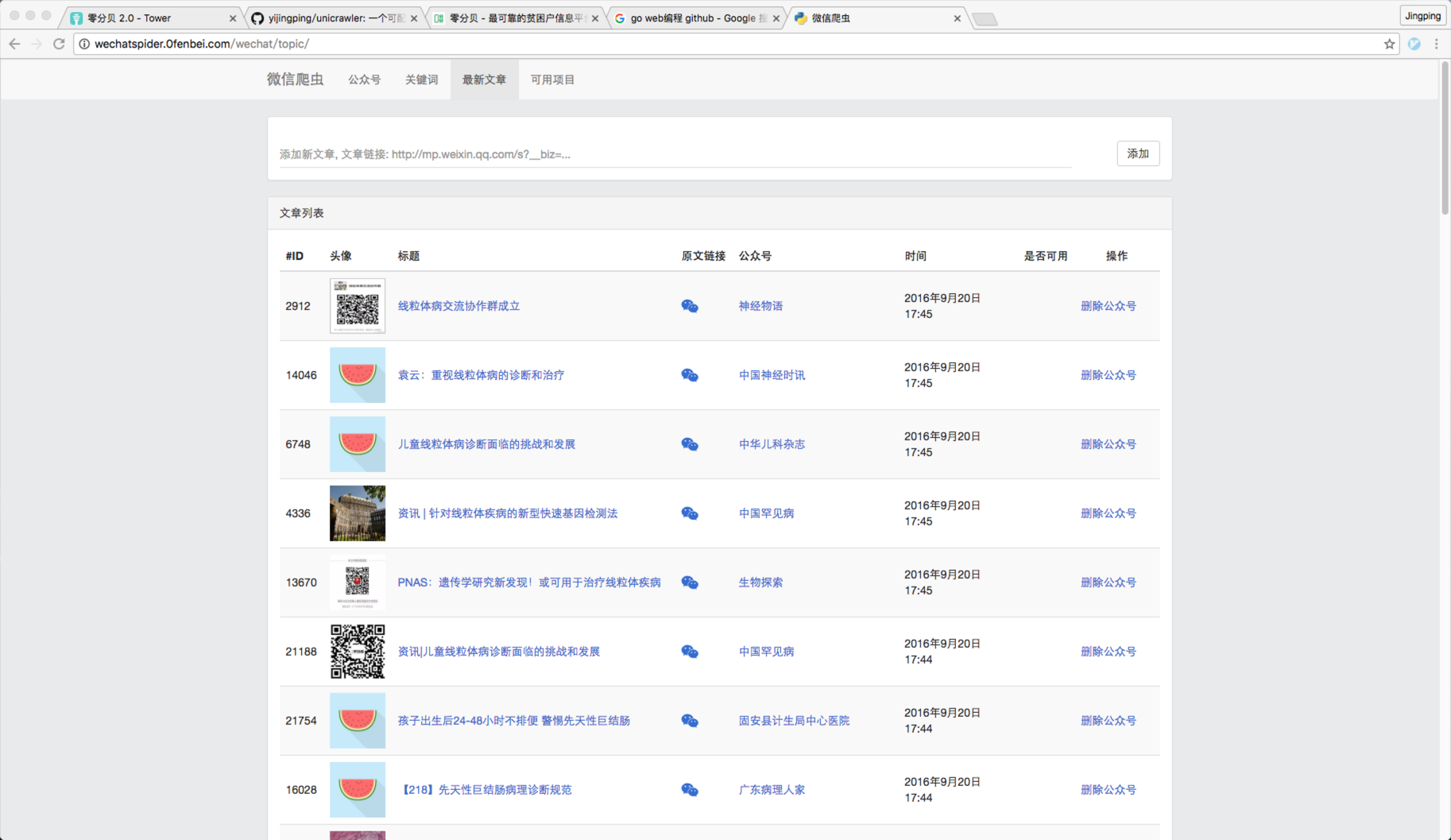
3)已经爬取的微信文章
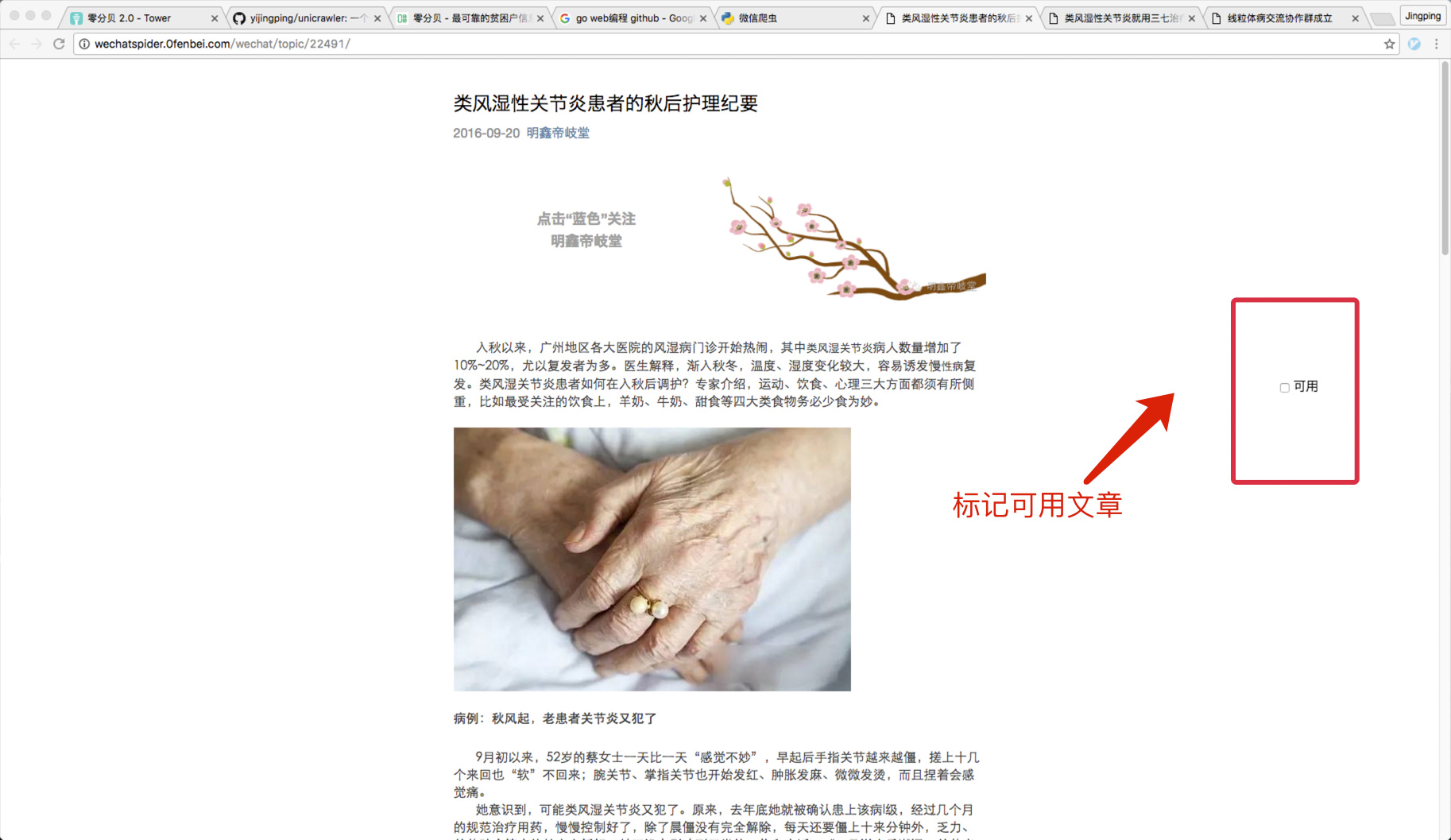
4)查看文章,并标记是否可用
5)控制爬取进程数
使用到的技术和框架
django mysql redis lxml selenium
